HelloWorld | SV实验0 | SV实验1
UVM入门和进阶实验0
介绍
UVM系列实验学习流程:
- 如何搭建验证框架
- 验证组件之间的连接和通信
- 如何编写测试用例,继而完成复用和覆盖率收敛
UVM实验0与SV实验0思想一样,让大家通过简单 的实验要求,在轻松愉悦的气氛下,踏出 UVM 世界的第一步,大体步骤如下:
- 懂得如何编译UVM代码
- 理解 SV 和 UVM 之间的关系
- 了解 UVM 验证顶层盒子与SV验证顶层盒子之间的联系
- 掌握启动 UVM 验证的必要步骤
上面四个步骤对应四个独立的文件
内容
1 UVM编译
本节视频内容主要介绍了uvm编译相关的内容,使用到的源码为:uvm_compile.sv
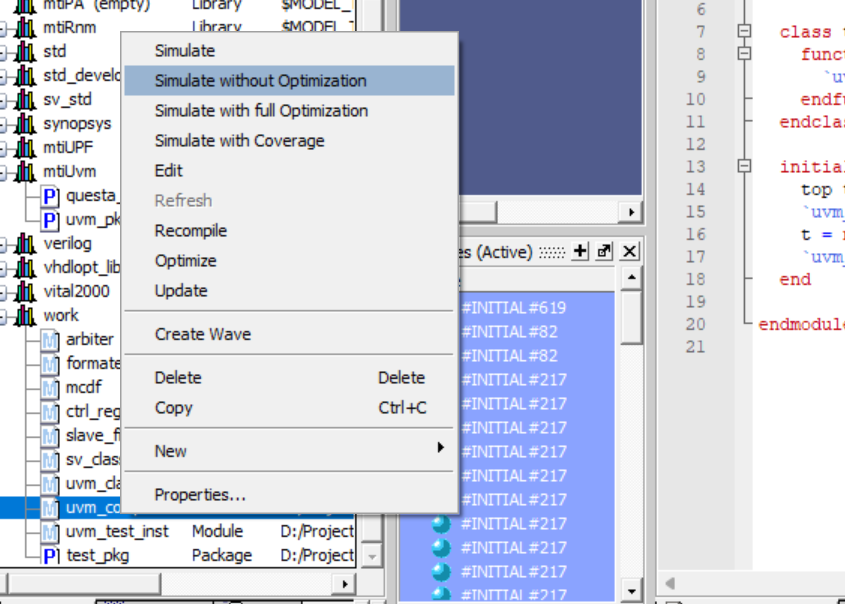
1)直接编译uvm_compile.sv
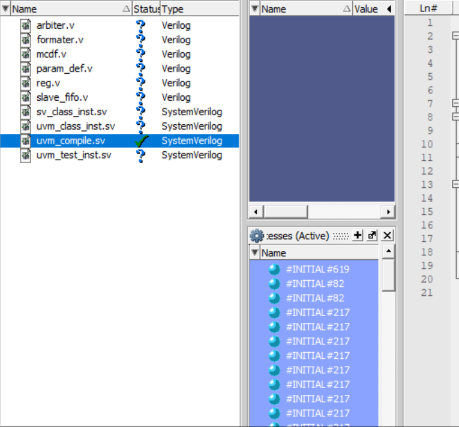
2)运行仿真
发现Loading了sv语言标准和uvm_pkg
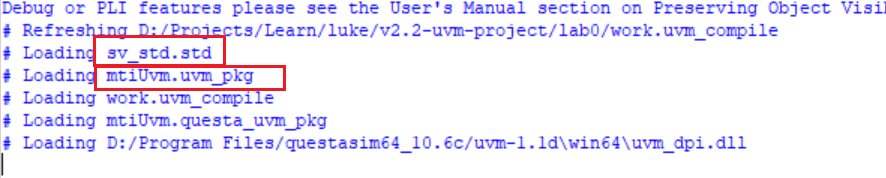
为什么不用编译uvm_pkg?
因为Questasim,默认编译到Library里面了,如下图所示,mtiUvm(默认版本uvm1.1,mti意思是mentor)
mtiUvm里面包括两个库:
- uvm开源库:uvm_pkg(我们uvm_compile.sv中import的是这个 )
- Questa的UVM定制部分库:questa_uvm_pkg
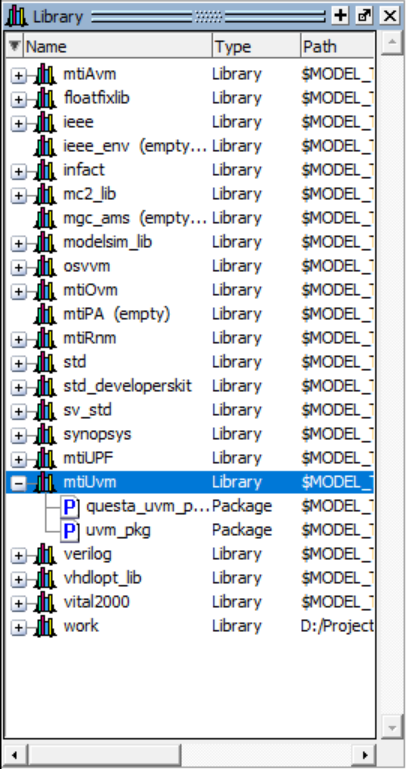
uvm_pkg编译
在qustasim帮你编译好了,其他eda中类似vcs你需要自己编译一次
3)run -all
1 | |
2 SV与UVM之间的关系:ClassBrowser
本节视频内容主要演示了View->ClassBrowser中各个工具的使用效果,使用到的源码为:sv_class_inst.sv、uvm_class_inst.sv
1 | |
locals中的值:@top@1
- @top:该实例的类
- @1:该实例类的第几次实例化
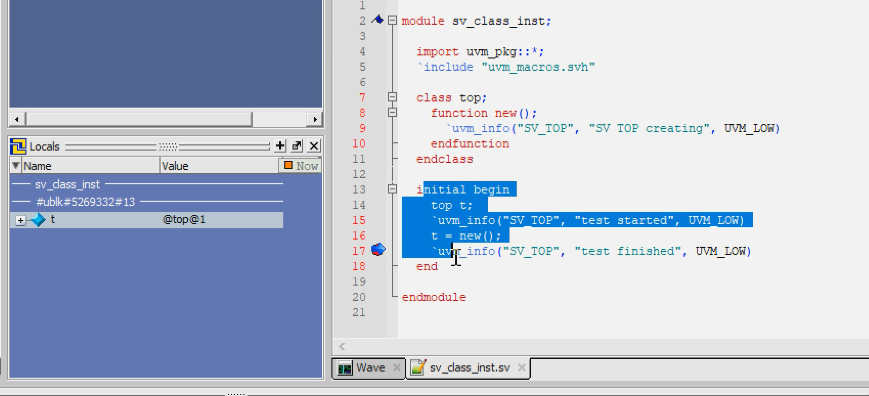
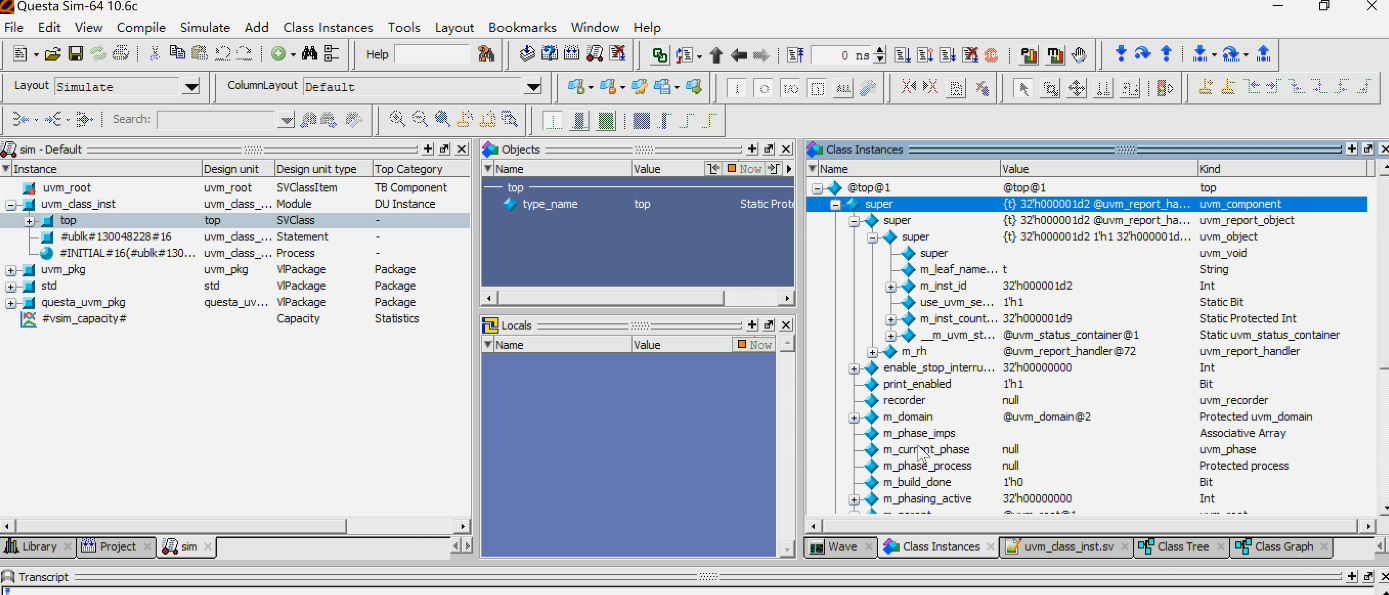
class interface:
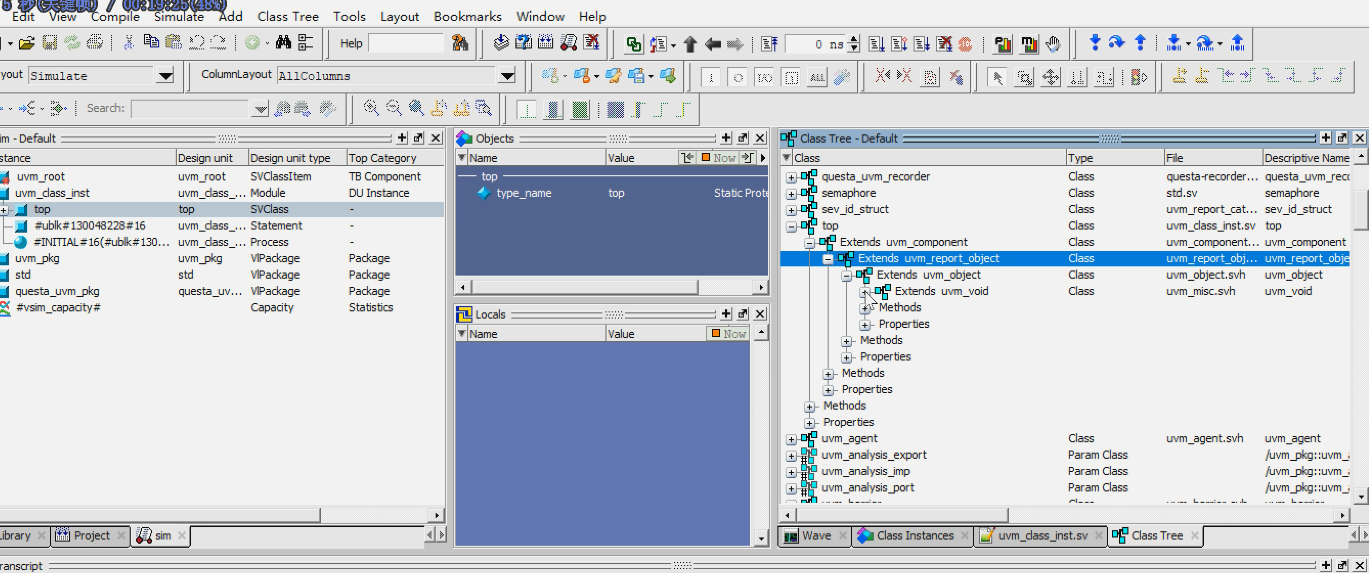
class tree:
class graph:
- graph比较大,不仅包括了文件中定义的top类
- 一般查看类的继承关系用class interface就够了
3 UVM验证顶层与SV验证顶层的对比
使用到的源码为:uvm_test_inst.sv
更刚才没有太多的变化,就是加了个package,再用uvm_test和run_test()改为uvm的建立方式,并使用objection机制
主要内容:
- objection机制与所有phase结束则退出仿真
- 仿真退出会打印统计的
uvm_info内容 - 查看内部成员的另外一种方法
1)raise_objection:
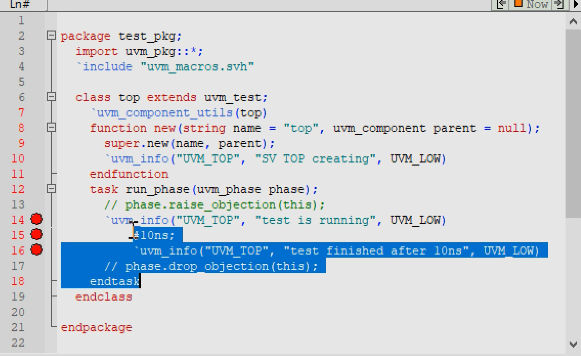
执行这个没有一开始就raise_objection的例子,则执行到14行断点后会自动退出仿真,最终显示0时刻就结束了仿真。所以run_phase必须一开始就执行raise_objection
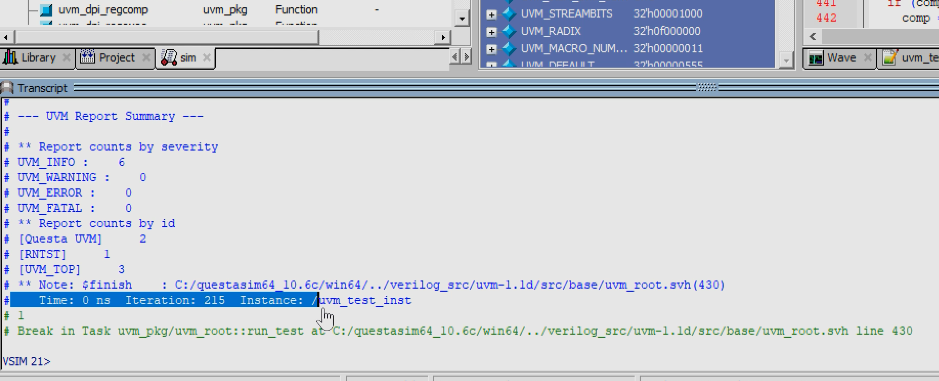
2)仿真退出会打印统计的uvm_info内容
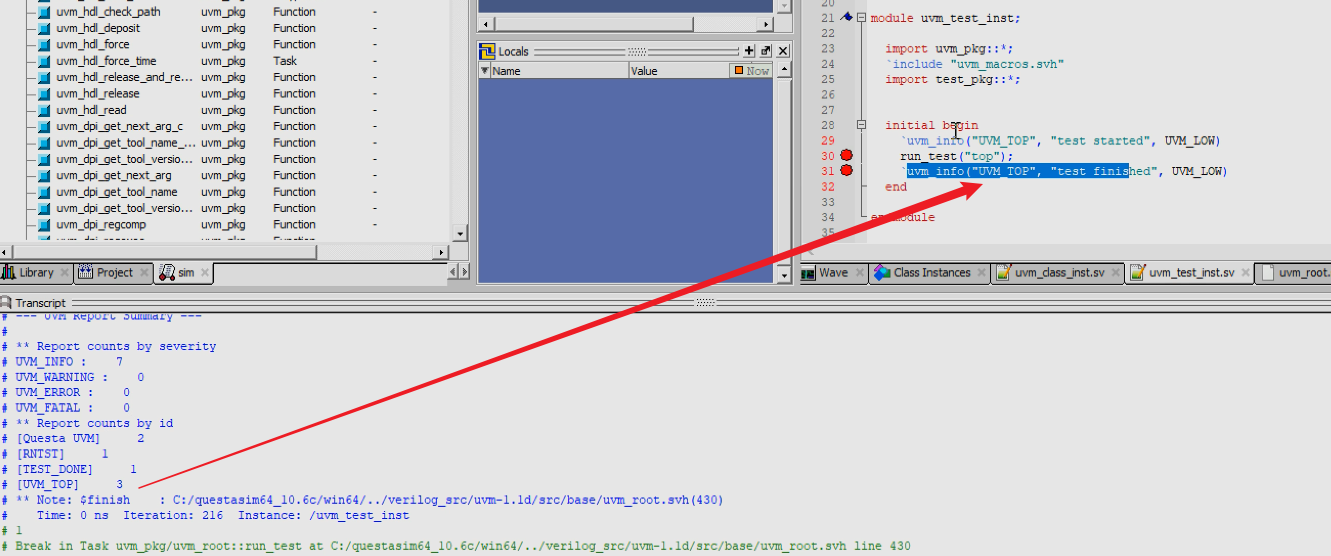
3)可以通过点击示例,直接在objects里面看内部成员,而不用locals了(路科大哥你是不是一开始说的就有问题,什么locals只能看软件)
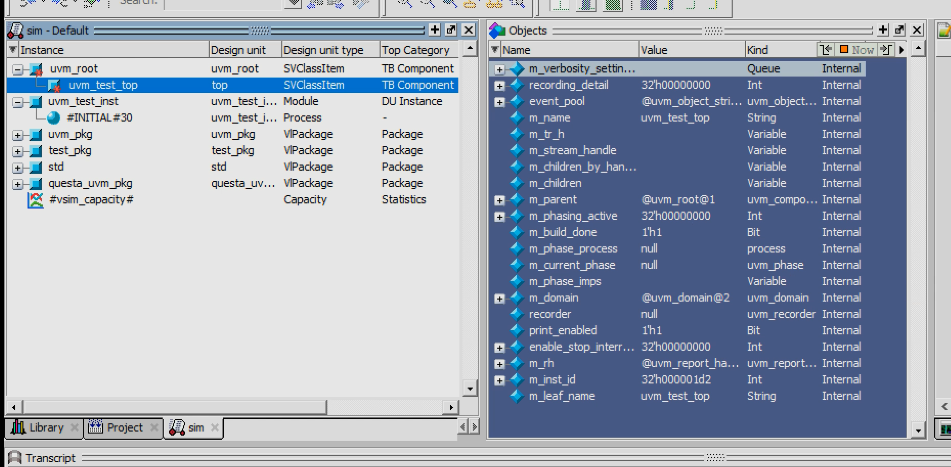
要点总结
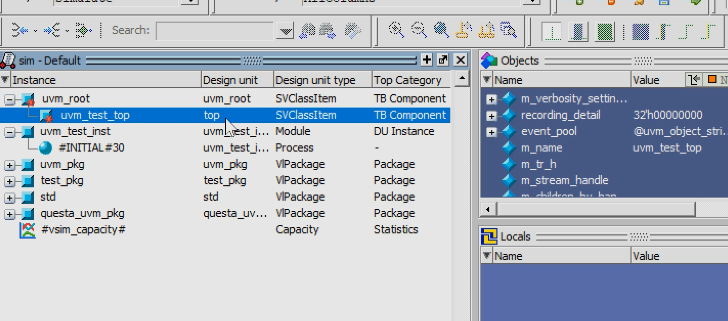
1.双顶层:
- 验证环境顶层:uvm_root
- 硬件顶层:uvm_test_inst
2.timescale缺失的情况
没有设置timescale默认时间单位为1ns/1ns,所以ps在仿真里面不被识别了,等同于#0
3.questasim中的uvm_pkg的编译(见本节1.1 uvm_pkg的编译)
questasim默认编译,其他eda(如vcs)中需要手动编译uvm_pkg
4.uvm_pkg的导入
1 | |
- 无论在什么地方,我们的验证顶层都需要下面两句,来将UVM包导入进来:
1 | |
- 我们可以看到验证顶层是在一个package里面的,并且分别定义了一个测试用例和run_test()的testbench
UVM入门和进阶实验1
介绍
将带领大家了解下面主要几个部分:
- 工厂的注册、创建和覆盖机制
- 域自动化以及 uvm object 的常用方法
- phase 机制(uvm_comp相对于uvm_object独有的)
- config 机制
- 消息管理
uvn实验1代码相对简单,讲的是一些机制的内容(类似sv实验0~3的部分),uvm实验2进入主线学习uvm结构
内容
1 工厂的注册、创建和覆盖机制
1)基本内容
factory_mechanism.sv与factory_mechanism_ref.sv
命令:vsim -novopt -classdebug +UVM_TESTNAME=object_create work.factory_mechanism
内容:comp/object的工厂的注册、创建和覆盖机制
2)注册
UVM世界中的注册一共有哪几种方式呢?只有两种用来注册的宏,请你记住它们:
`uvm_object_utils(T)`uvm_component_utils(T)
3)创建
uvm的工厂创建方式有三种:
- (推荐)通用方法:
类名::type_id::create("t2", this); - uvm_factory方法:
f.create_object_by_type()或f.create_component_by_type()f为uvm_factory句柄,获得方式:uvm_factory f = uvm_factory::get();
- object/component自带方法:
create_object()或create_component()
uvm的工厂创建代码如下:
1 | |
4)factory重载
uvm_object->trans->bad_trans
uvm_component->unit->big_unit
factory重载:回去看UVM实战第八章!
重载和创建的顺序:一定要先重载,后创建!否则重载不发挥作用!
object的重载(只能set_type_override_by_type系列,我猜的)
1 | |
component的重载(能set_type_override_by_type又能set_type_override,我猜的)
1 | |
2 域自动化以及 uvm object 的常用方法
1)基本内容
uvm_object_methods.sv与uvm_object_methods_ref.sv
有很多小的实验点:
- 实验 2.1:学习使用域自动化的宏方法,可参考红宝书表 10.2 和表 10.3
- 实验 2.2:请学习
uvm_object:compare()方法 - 实验 2.3:请尝试掌握uvm_pkg中常见的一些全局控制对象,例如
uvm_default_comparer,该对象可参考`uvm_comparer类提供的方法。具体还包括哪 些全局对象,可以参考红宝书图 10.7 uvm_pkg 的全局对象 - 实验 2.4:请学习自定义uvm object的一些回调函数,例如
do. compare(), 并且理解预定义函数compare()与do. compare()的调用顺序和关系 - 实验 2.5、2.6,请学习
uvm_object:print()及uvm_object::copy()函数,再结合 之前的compare()函数,理解域自动化的意义以及它带来的便捷性
2)具体要求
TODO
- 2.1 做类的声明
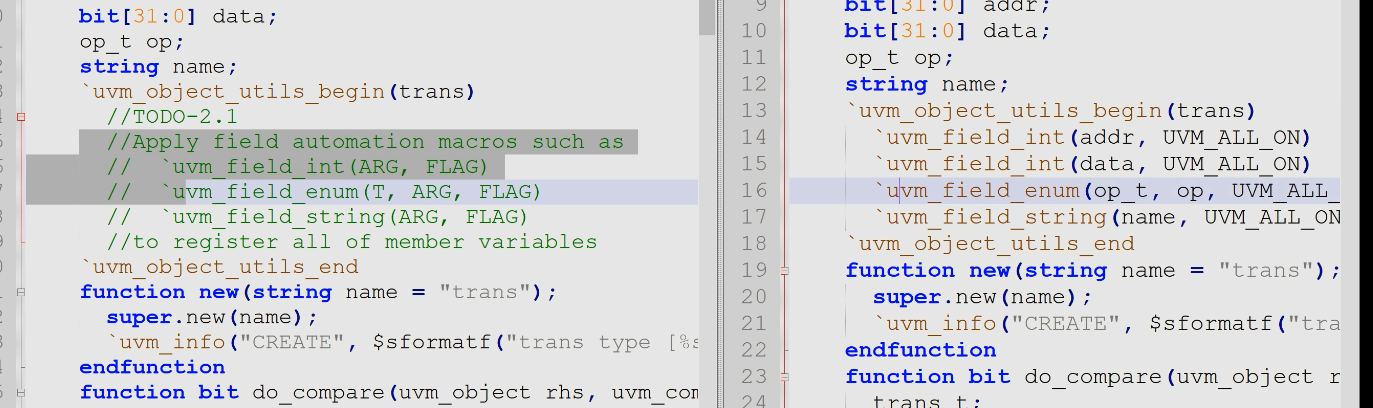
- 2.2 使用域了可以进行compare(不相等则直接停下来,不会告诉你其他不相等的内部成员)
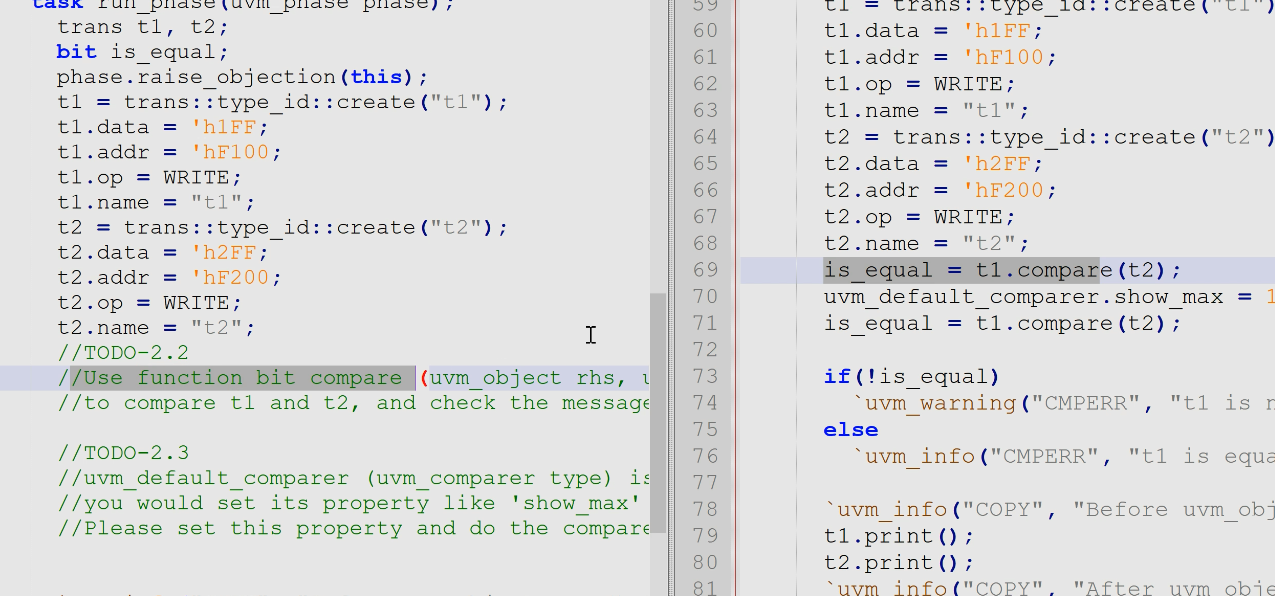
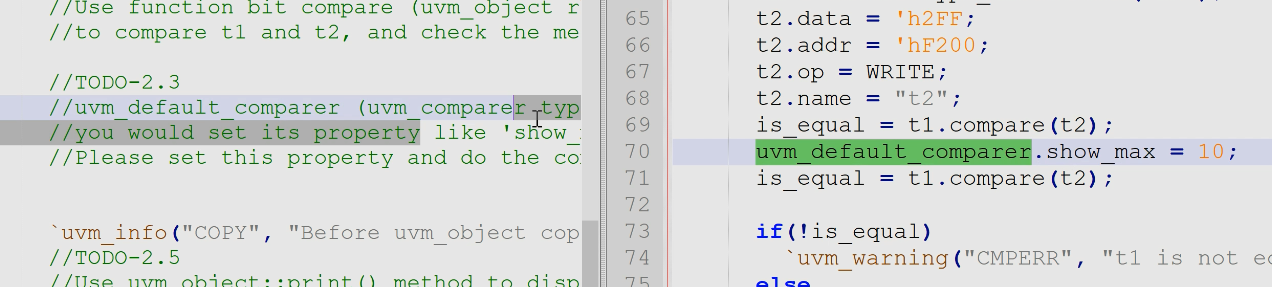
- 2.3 改变compare效果,使其比较的不同结果更多一点:使用全局控制compare的实例
uvm_default_comparer
- 2.4 自定义compare函数:
do_compare()
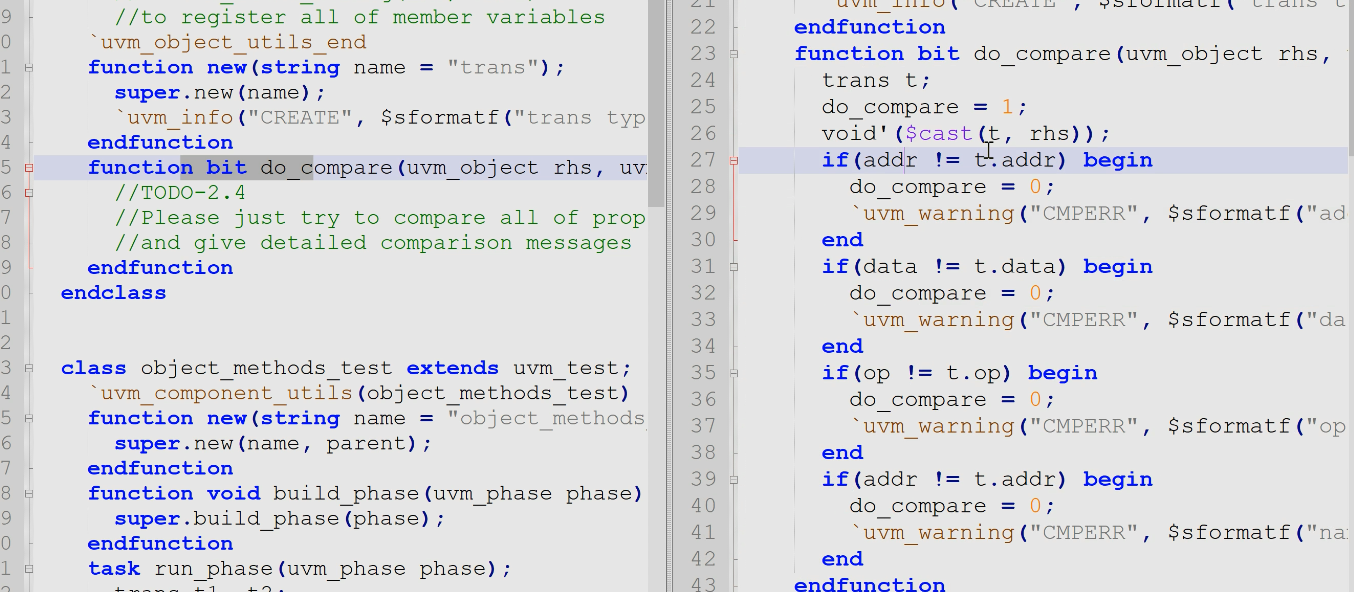
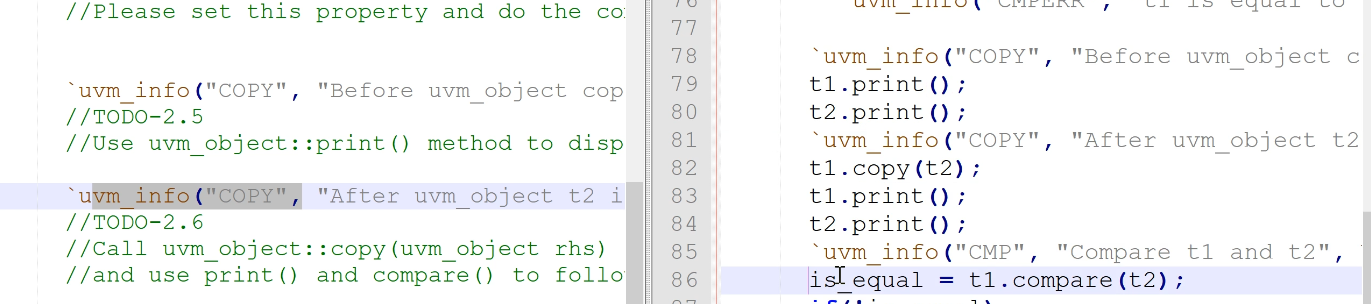
- 2.5 掌握print()作用,在调用copy之前先把对象的内容打印处理啊

- 2.6 掌握copy()作用
3 phase机制
phase_order.sv与phase_order_ref.sv
uvm独有的9个大phase
run_phase以及与其平行的12个小phase是task phase
- 建议要么用run_phase要么用12个phase其中几个,最好不要同时使用,本例只做学习使用所以同时使用了
内容:
- 理解不同层次/相同层次,phase的执行顺序
- build_phase自顶向下、connect_phase自底向上
- run_phase和12个小phase之间的并行关系
- 仿真一共执行的时间(1us?2us?…)你如何解释
实验二,组件的phase如何自动执行中对不同组建的run_phase进行了解释,实际上顶层uvm_root对所有的组件都是fork_join_none遍历的启动run_phase。不同于SV的类似点火一样一层一层调用run()
打印信息:通过打印信息,理解不同phase的执行顺序

- “CONNECT”——id
- “comp1 connect phase entered”——message body
- UVM_LOW——冗余度
- 通过打印信息,理解不同phase的执行顺序
4 config机制
1)基本内容
uvm_config.sv与uvm_config_ref.sv
内容:
- 接口传递
- 单一变量传递
对象传递
2)具体要求
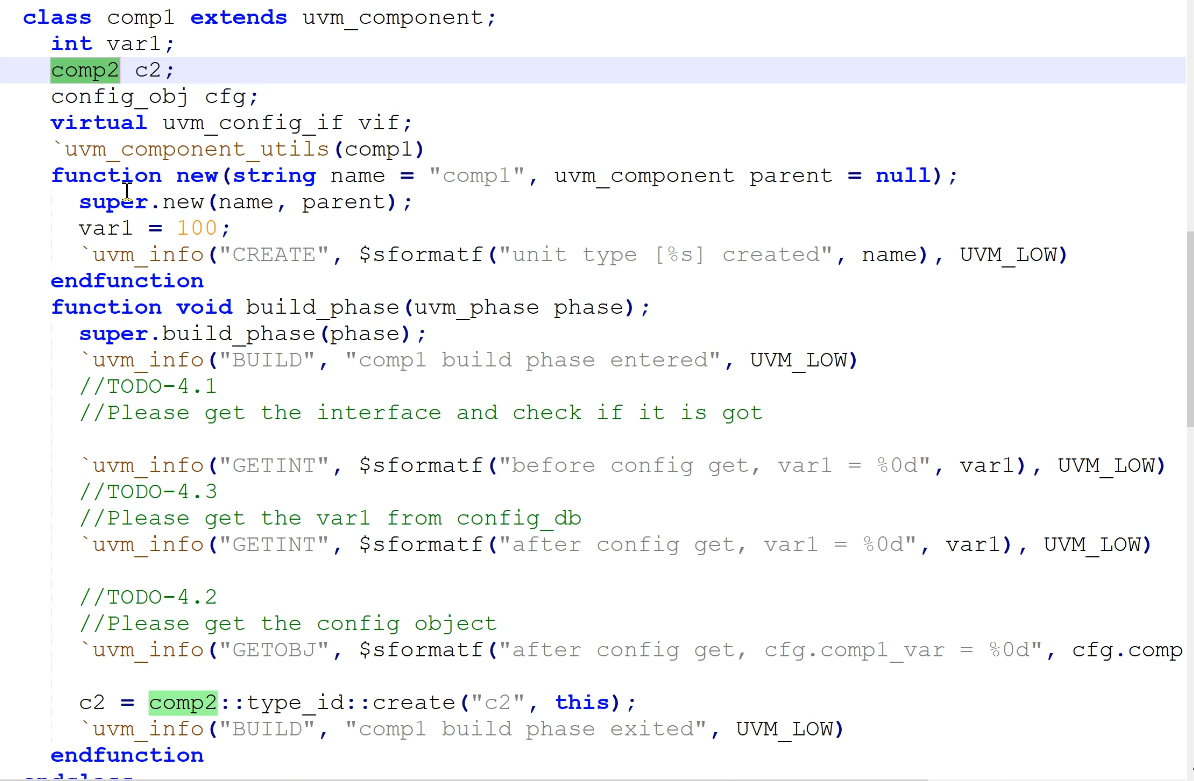
4.1,4.2,4.3:获得接口、变量、config object句柄
- 其中interface,只有在顶层tb才有,所以要在顶层tb中set
- 4.4 思考问题:
- 接口传递与run_test之间是否存在顺序
- 在uvm_config_test::build_phase()中,如果讲从的例化提前到刚进入build_phase()中时,而将后续的config_db传递操作放置于其后,是否可行?为什么
- 上面两个问题,你认为config_db在使用中应注意什么地方
5 消息管理
1)基本内容
uvm_message.sv与uvm_message_ref.sv,与uvm_config.sv结构类似,不过是增加了对消息的练习
2)具体要求
5.1:组件消息过滤,使用set_report_verbosity_level_hier(),可参考类的手册的原型进行深入学习,或者直接参考答案
5.2:ID的消息过滤,注释5.1,使用set_report_id_verbosity_level_hier()
5.3:发现5.1、5.2仍然有些消息无法被屏蔽,如config_obj的”CREATE”以及uvm_message的”TOPTB”,请思考为什么?如何屏蔽这些消息呢
- 使用uvm_root::get()来获取最顶层(即uvm_message_test的顶层)来控制过过滤”CREATE”和”TOPTB”的消息
lab1 object创建名字传入问题
问题
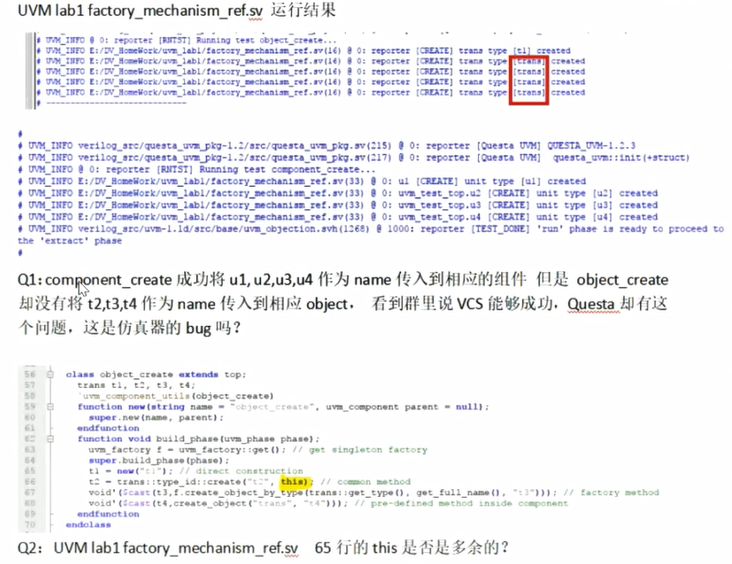
原因
Qustasim默认uvm1.1d,而vcs的Makefile使用的是uvm1.2,不同uvm版本导致执行不一样
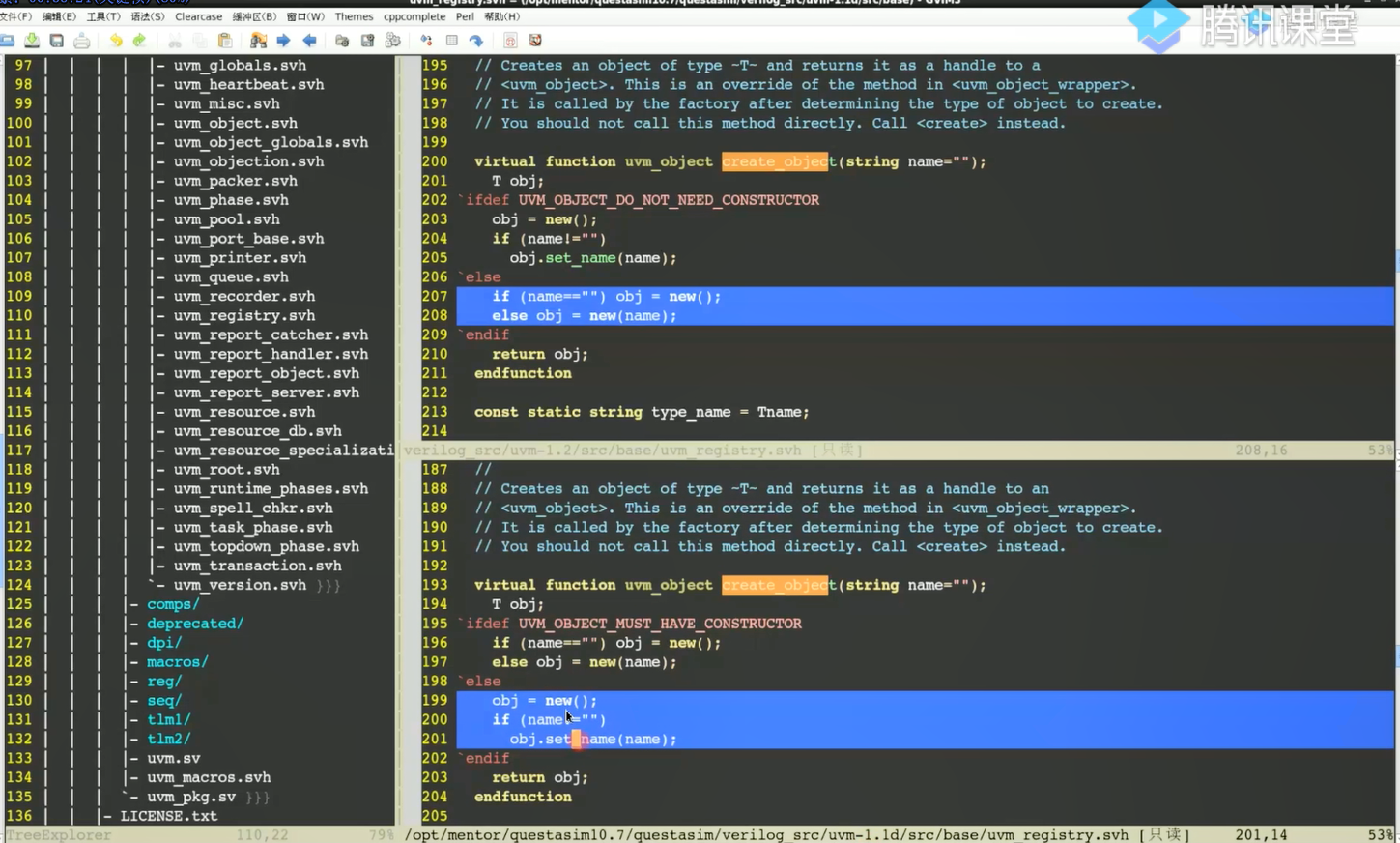
如何修改Questasim为uvm1.2
找到配置目录:
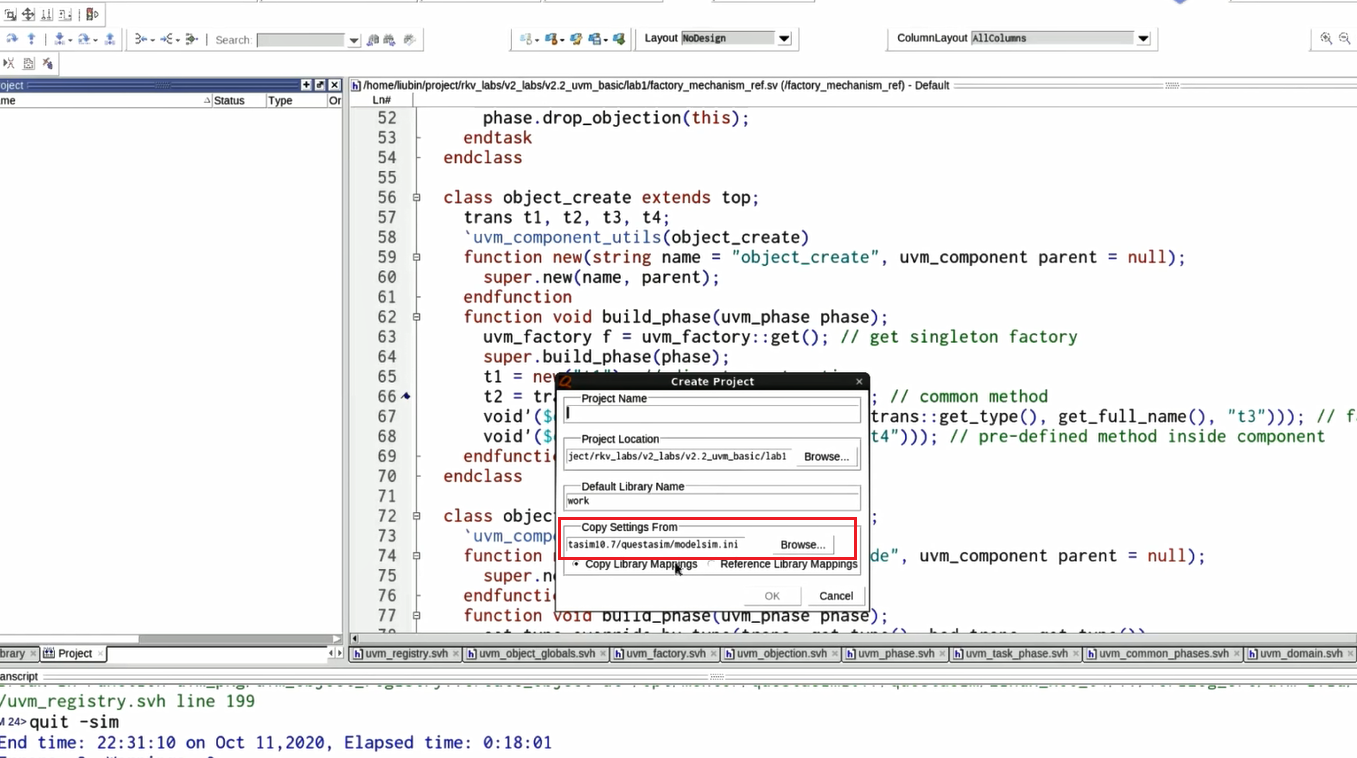
修改modelsim.ini:
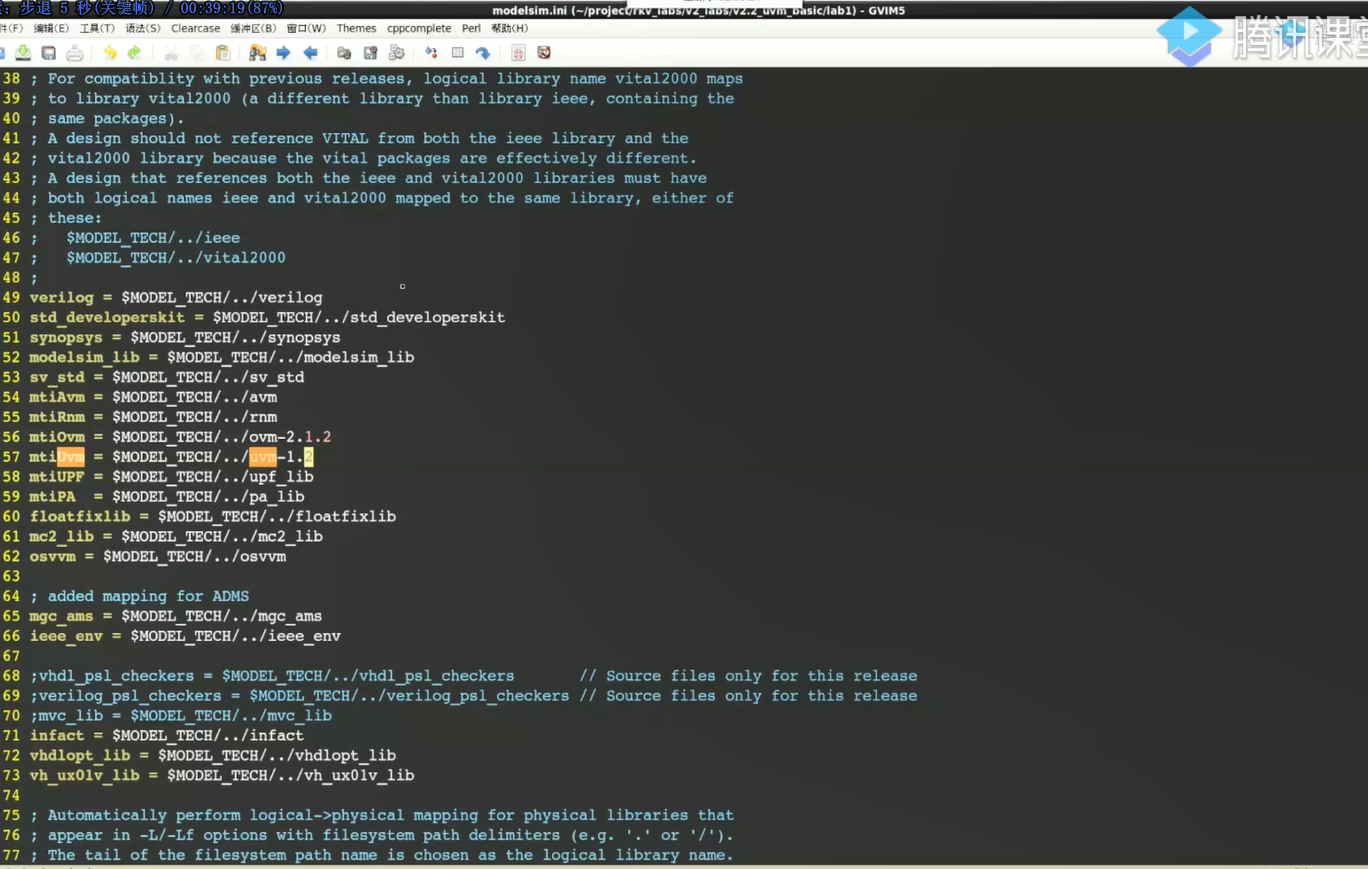
再创建project
UVM入门和进阶实验2
介绍
uvm实验2的验证结构与sv保持一致,几乎全部是svlab5一致过来的,绝大多数都没有改变(因为还没有学到),包括:
- SV验证环境结构
- SV组件之间的通信管道(mailbox,不是uvm的通信管道)
- SV的激励产生和发送模式(svlab5)
- SV的数据检查和报告(svlab5)
- SV的测试开始与结束方式(svlab5)
- SV的配置方式(svlab5)
uvm实验2到实验5,逐步移植为纯粹的UVM环境:
- SV实验我们做的是加法,做的纯软件的验证环境
- UVM我们做的是减法,不断剔除SV的特性,替换为UVM的环境,并进行比较与优势
- 实验不会暴增了,思考SV与UVM在验证环境上不同的实现方式孰优孰劣
本次实验现需要将之前学习到的内容进行充分应用和理解,包括:
- 各个验证组件的使用(实验二帮大家了解验证组件如何过度的)
- 验证组件之间的层次关系(实验二帮大家了解SV和UVM层次关系的不同)
- 工厂的””注册”和”创建”(uvm实验一了解了)
- “域自动化”和uvm.object的预定义方法(uvm实验一了解了)
- “phase”的自动执行和顺序关系(uvm实验一了解了)
- 消息宏的简单使用(uvm实验一了解了)
- 通过config_db对接口的传递(uvm实验一了解了)
- 测试的选择和开始,以及对仿真结束的控制(uvm实验一了解了)+
顾大局而不拘小节,掌握大思路,路科已经对上面的内容改造好了,鼓励大家看如何改造的
内容
讲解思路,左边SV代码右边UVM代码
验证组件和层次构建
主要内容:SV组件替换为UVM组件
讲解思路:左边SV代码右边UVM代码,跟着视频了解如何构建的
替换规则:
- 实现组件对应原则
- sv的transaction类对应uvm_sequence_item
- sv的driver类对应uvm_driver
- sv的generator类我们稍后会替换为uvm_sequence + uvm_sequencer
- sv的monitor对应uvm_monitor
- sv的agent对应uvm_agent
- sv的env对应uvm_env
- sv的checker对应uvm_scoreboard
- sv的reference model和coverage model均对应uvm_component
- sv的test对应uvm_test
- 对应的同时要注意:
- 什么时候需要域自动化?我们需要使用一些函数的时候,如:copy(),clone(),compare()
- 对谁进行域的自动化?对一些数据类型,在这里是uvm_sequence_item和generator里面的成员变量,也就是使用到传递的数据类型的组件(以后就是uvm_sequence_item与uvm_sequence了)
讲解内容
看:chnl_pkg.sv, tb.sv, reg_pkg.sv, mcdf_pkg.sv fmt_pkg.sv(report_pkg.sv我们不需要了,uvm自带相关宏和函数)
uvm的导入:
- 每一个用到uvm的pkg都要
import uvm_pkg::*;与`incldude "uvm_macros.svh" - tb.sv没用到uvm,所以不用导入
chnl_pkg.sv
1.do_driver
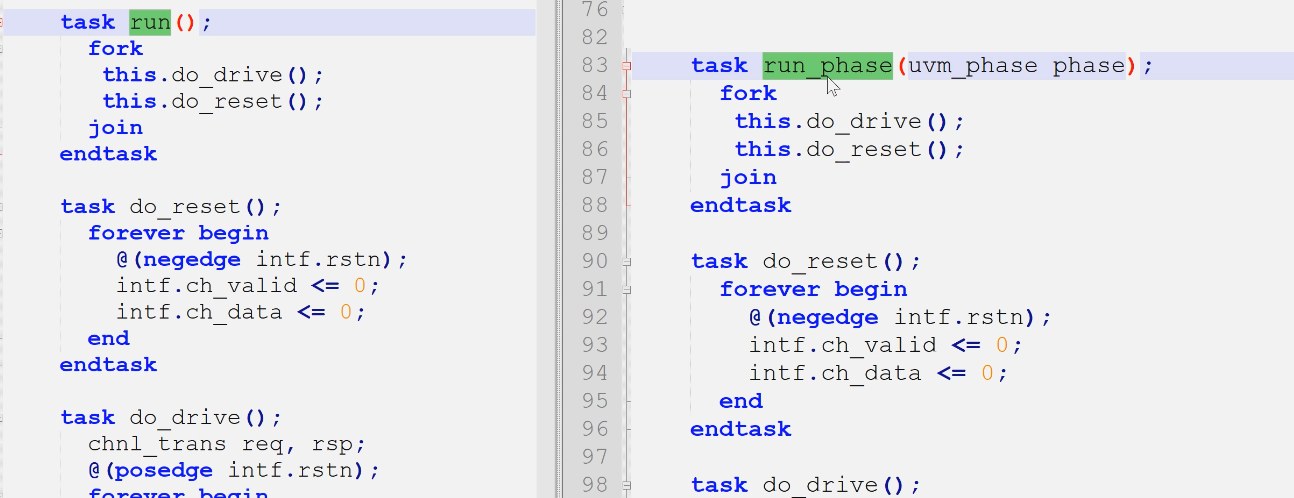
1)run_phase和run
run_phase就是把run的内容放进来了,别的没变
2)有个细节
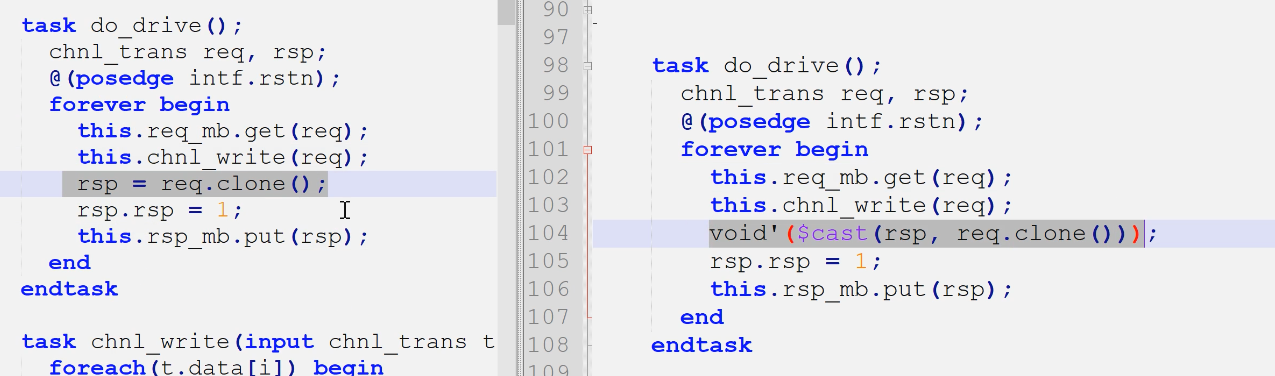
do_reset没有变化,do_driver有个细节变化
- sv中的req.clone都是相同transacation类型的
- uvm中返回的都是uvm_sequence_item父类句柄,需要转换
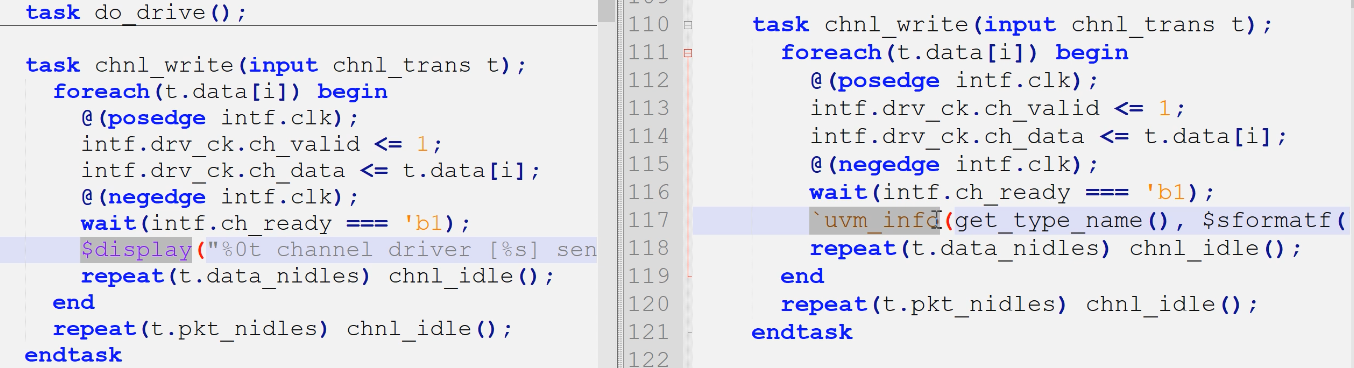
3)chnl_write不用$display了
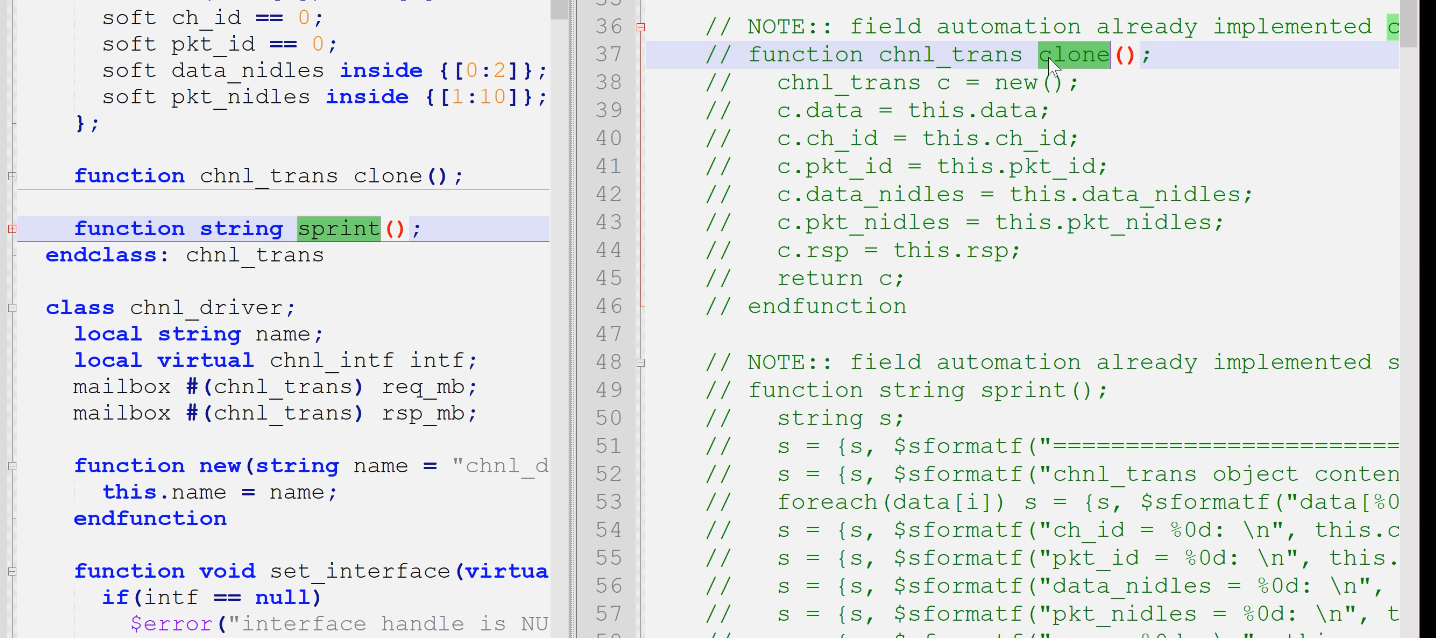
4)clone()和sprint()直接注释了
原因:我们用域的自动化里面有了
2.generator
1)没大改
这里还没改成sequencer和sequence,我们在环境四进行改造,我们学到哪里,改到哪里
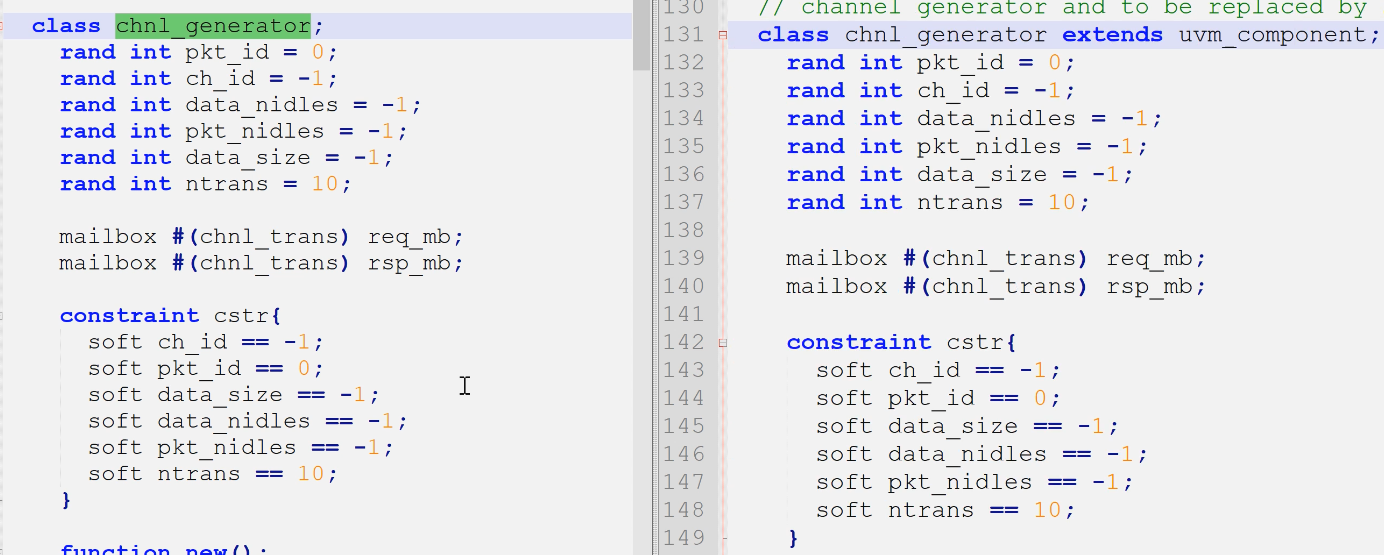
2)成员变量,域的自动化

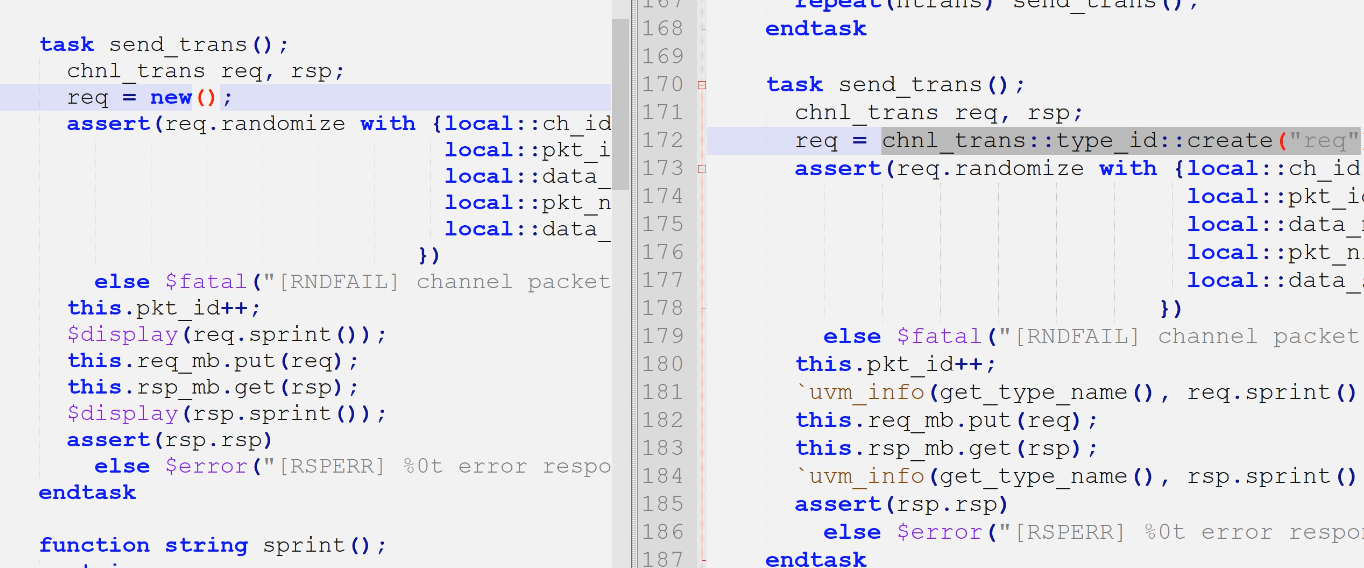
3)send_trans()创建trans
- 创建用type_id(大多数uvm类可以type_id创建,如uvm_obj和uvm_comp;但有一些类不能用type_id创建如port类,port类继承于uvm_void。原因在实验3?)
- 随机化没变
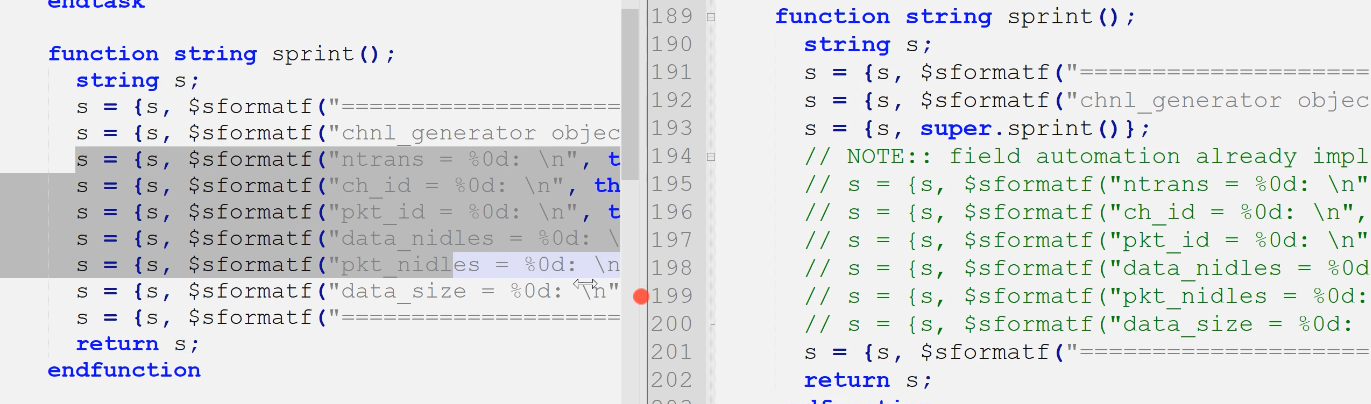
4)super.sprint()
sprint()只打印了一个头,具体内容直接调用了super.sprint()
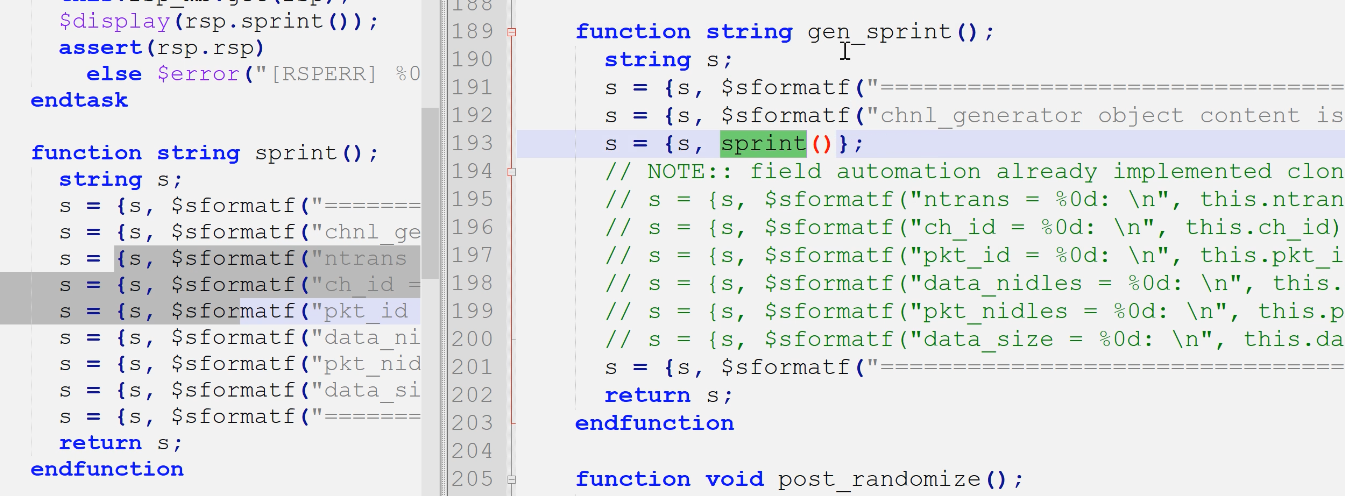
也可以直接sprint不用super,比如你把函数改成gen_sprint()这样就不会有歧义了,编译直接去父类找
5)new和build_phase
什么时候放到new,什么时候放到build_phase?
- 需要用到override且用type_id创建的放在build_phase里,以方便工厂override,进行类型转换
- new创建的放在new或者build_phase里都ok
- 最简单,所有放在build_phase,绝对错不了

send_trans中创建的req就直接type_id创建了,因为我们不需要用到工厂override机制
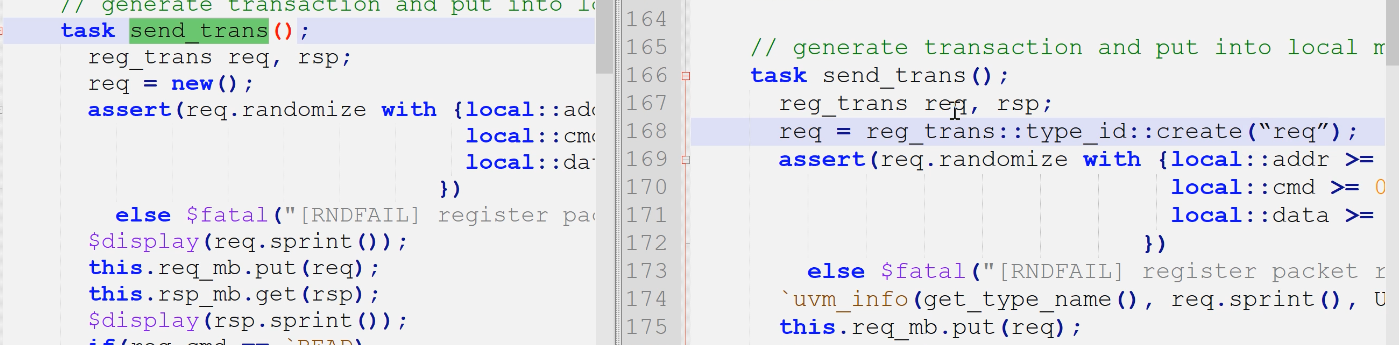
创建组件一定要要用type_id,因为需要形成uvm层次结构
3.monitor
没有变化
4.agent
1)例化
以前的例化连接放在new里面
现在例化放在build_phase
2)接口的传递没有config_db,仍然set_interface
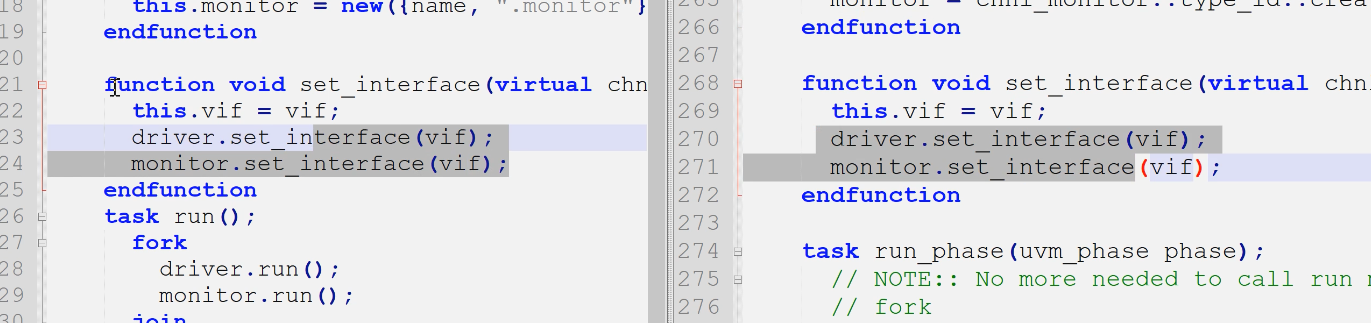
3)重要!run的调用
- 以前run需要调用子一级的run
- 现在uvm_root对run_phase统一调度,因此不需要调用了
其他package思路和chnl_pkg一样
mcdf_pkg.sv(sv顶层环境)
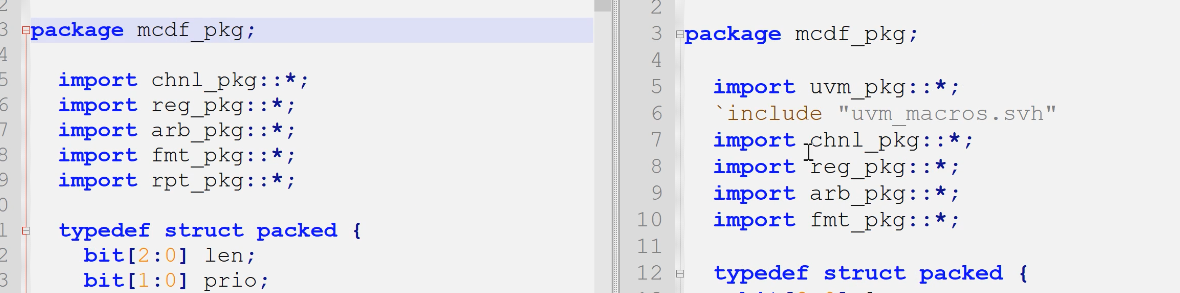
1.mcdf_checker
refmod就是加了个extends uvm_component;
1)组件间的连接
组件间mailbox的连接从new函数转移到connect_phase
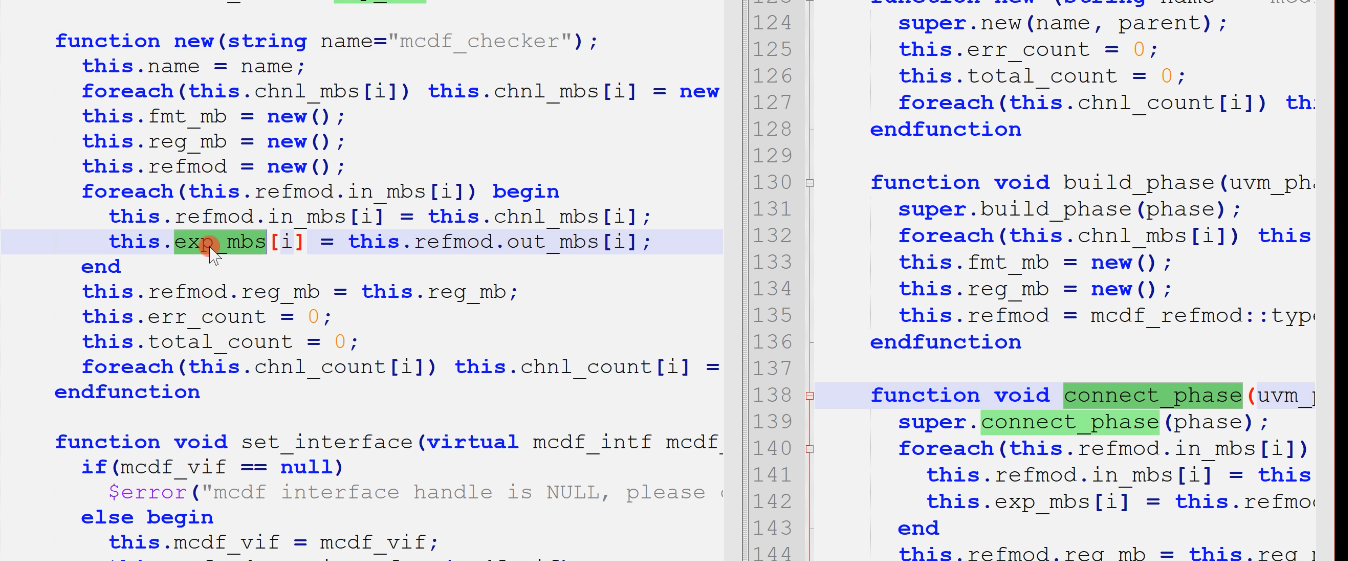
2)set_interface没有变化
3)do_compare
为了避免与uvm的回调函数冲突,改了do_compare的名字为do_data_compare,里面内容一样只不过打印信息用了uvm宏
2.mcdf_coverage
没有变化,就相当于加了extends uvm_component;
3.mcdf_env
1)组件间的例化与连接
例化放到了build_phase
组件间mailbox连接放到了connect_phase
2)run
不用调用内部组件了,直接run
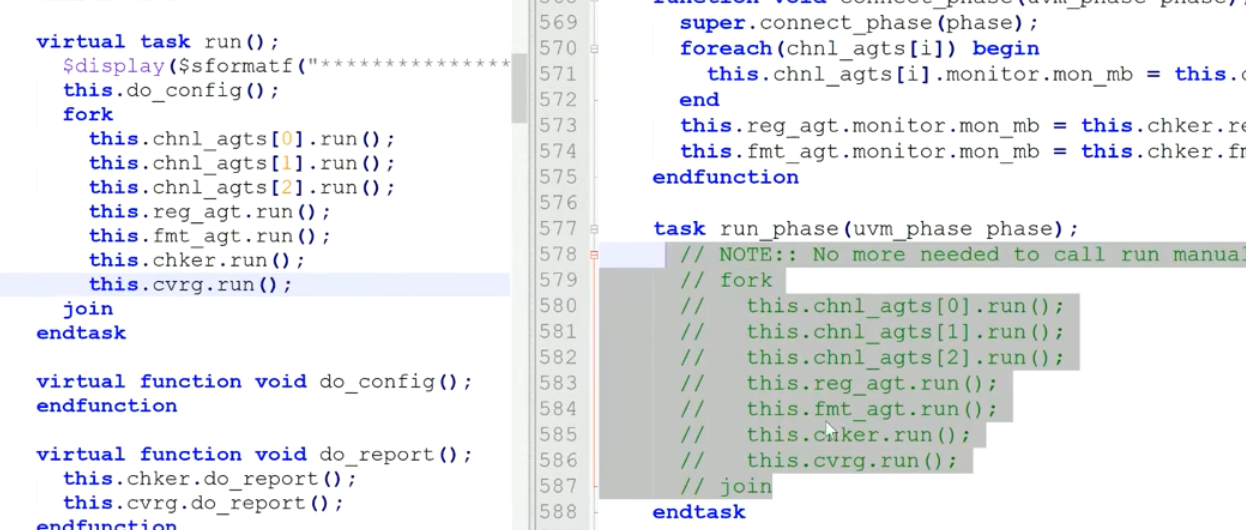
3)do_report
sv放到do_report
uvm放到report_phase,其中env不需要调用了,因此直接删掉就行,checker则是把do_report内容转移到了report_phase中

4.mcdf_base_test
1)改为继承于uvm_test了
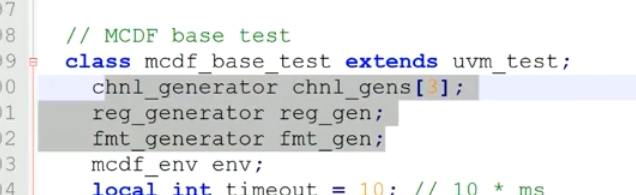
2)添加了许多vif
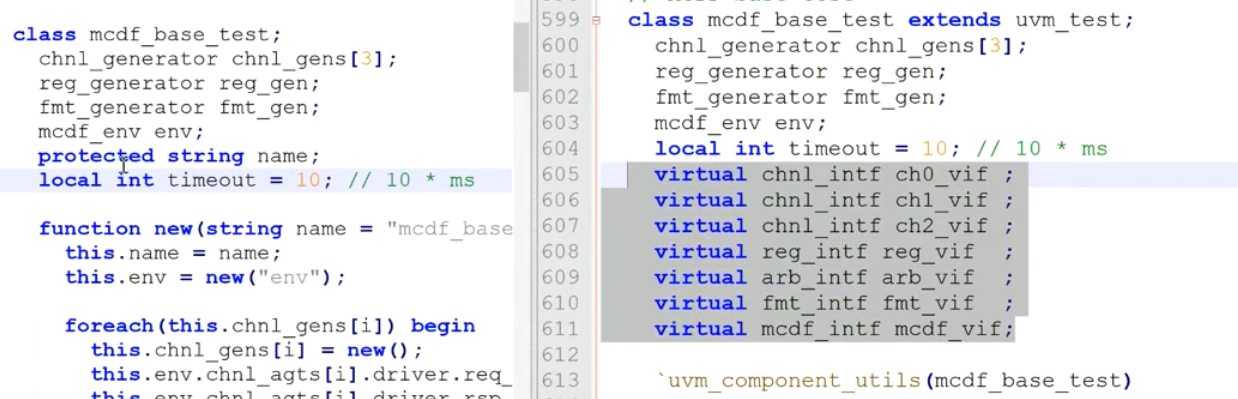
获取?在build_phase中,这些vif通过config_db::get从外部顶层获取

分发?在connect_phase进行分发

set_interface里面是啥?调用内部组件的set_interface

3)重要!run_phase与raise_objection
这里的测试用例调用了内部定义的一些任务,并且使用了objection机制
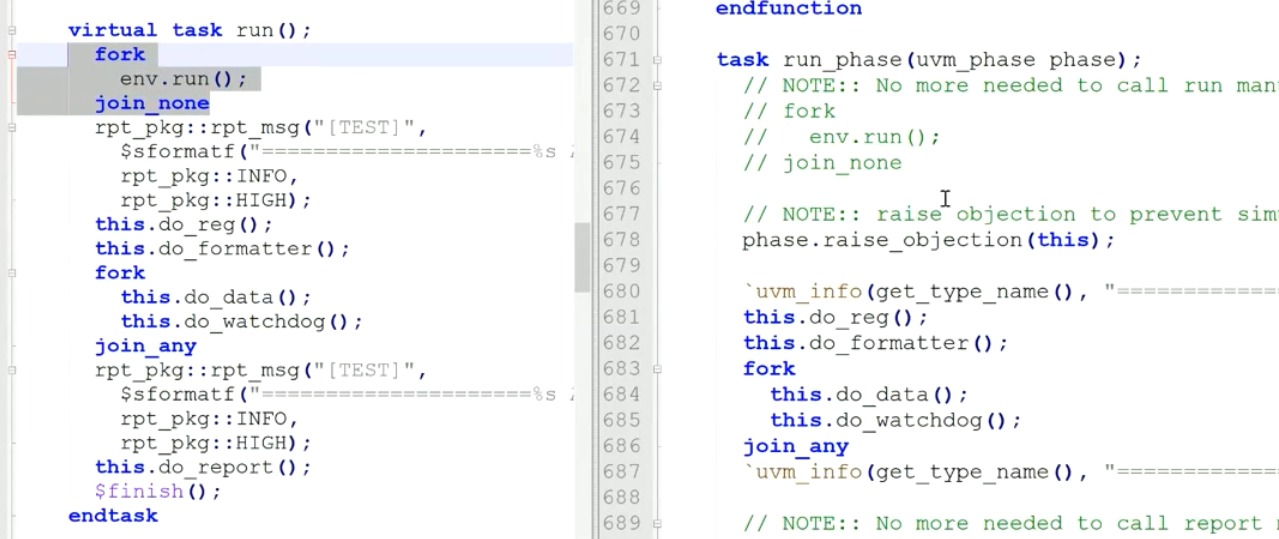
mcdf_data_consistence_basic_test
继承于mcdf_base_test同sv一样,其他do任务(如发送产生激励等)一点没变化,因为没学到,实验四会讲
tb.sv
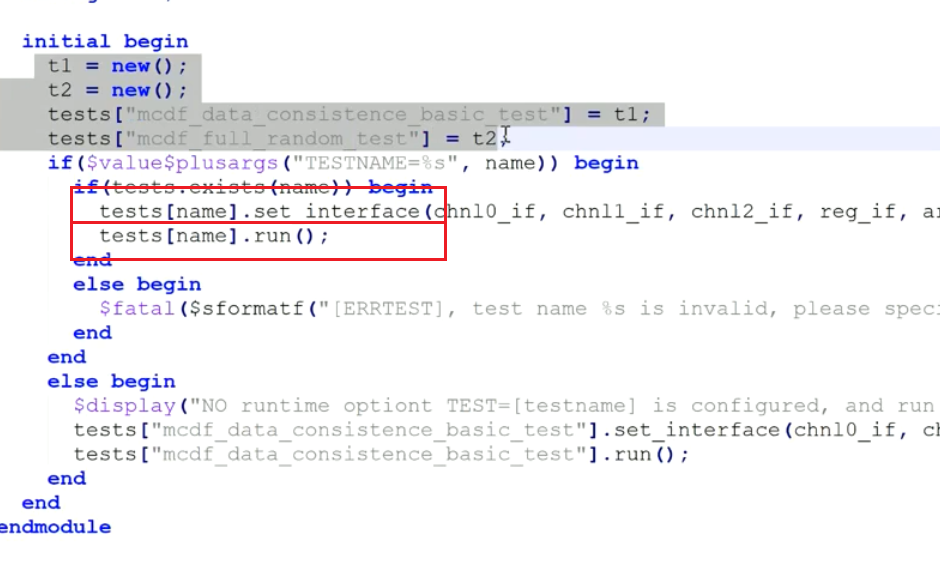
1.interface传递!只能使用config_db
使用config_db形式传递interface,而不是调用set_interface
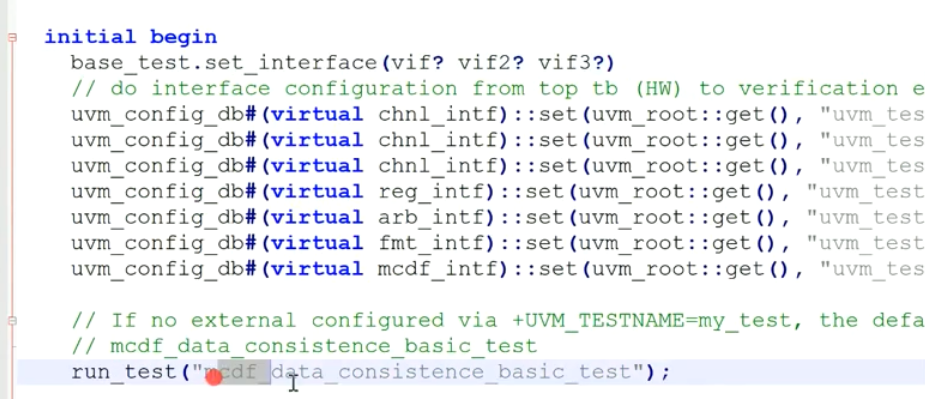
为什么不能使用set_interface了?因为这个时候你的test还没创建,而是在run_test的时候创建
如果先run_test呢?也不行,进入build_phase,还是没拿到interface指针
为什么SV可以?因为sv的时候把所有test已经例化了,此时所有的层次结构已经有了,这个时候你再对所有的test执行set_interface是合理的。这就是为什么SV需要例化所有test的原因,如果你不全部例化了,此时你的set_interface是失败的
2.run_test
直接调用run_test()或者run_test(默认测试用例的字符串),不用写TESTNAME的获取逻辑了
UVM的命令行的run_test参数为:+UVM_TESTNAME=xxx
如果没有参数则执行run_test的参数代表的测试用例,不指定则没有(路科也没说会不会报错)
小总结
命令:vsim -novopt work.tb -classdebug +UVM_TESTNAME=mcdf_data_consistence_basic_test
使用UVM的主要特性:
- run_phase、report_phase
- build_phase、connect_phase、
- config_db传递interface
- 域自动化来声明generator和transaction中的变量,不再定义clone(),看情况定义sprint()(如trans中不定义了,gen中调用了super.sprint())
- uvm_test中使用objection机制控制仿真结束
- 不再用$display而是用
`uvm_info, `uvm_warning, `uvm_error, `uvm_fatal,删除了rpt_pkg.sv - run_test代替+TESTNAME获取逻辑
目前涉及到组件间连接主要在以下三处地方:
- mcdf_pkg.mcdf_checker
- mcdf_pkg.mcdf_env
- mcdf_pkg.mcdf_base_test
不需要层层调用了,只需要在当前phase里面调用使用到的内容:
- run_phase(大多数情况可以因为层层调用而删掉)
- report_phase(大多数情况可以因为层层调用而删掉)
其他
void'
当你使用一个有返回值的函数,但你不需要使用返回值时使用,如果不加void'则编译器会提醒警告
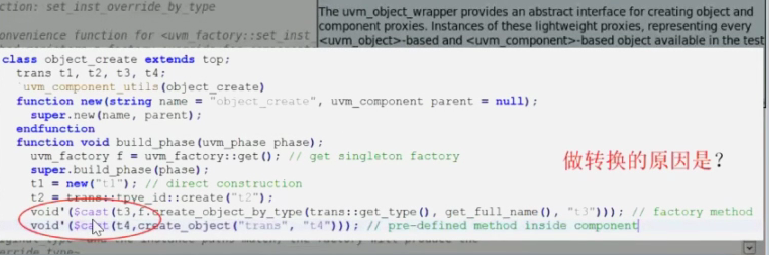
先配置再创建
问题:
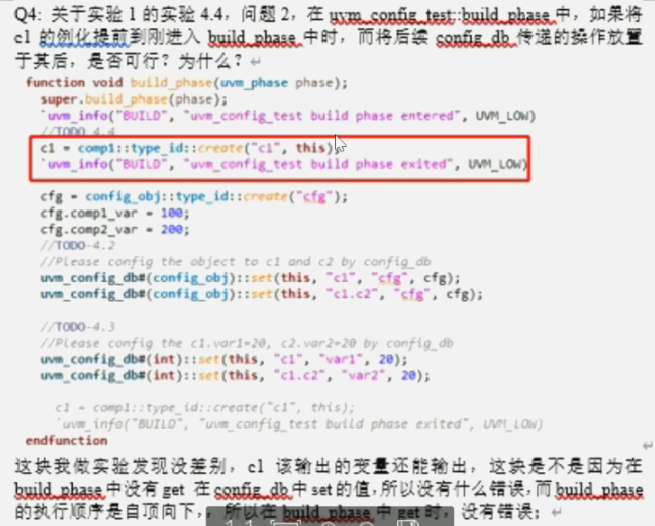
结论:此处不会出错,但不确保以后这种情况不会出错。应该遵循先配置后创建的原则。
原因:不容易出错,可以避雷。这里在build_phase可以,但当不同phase遵循不同创建配置顺序时,则创建的先后顺序会控制不住
UVM入门和进阶实验3
介绍
在实验3中,我们将SV环境移植到UVM的重点将主要在以下几个方面:
- TLM单向通信端口和多向通信端口的使用。
- TLM的通信管道
- UVM的回调类型uvm_calback
- UVM的一些仿真控制函数
内容
TLM单向通信和多向通信
之前的都是通过mailbox以及在上层进行句柄传递实现的:
- monitor到checker
- checker与reference model
内容:我们需要大家使用TLM端口进行通信,做通信元素和方法的替换
最终的更新方案(你需要围绕这个方案更新接口):
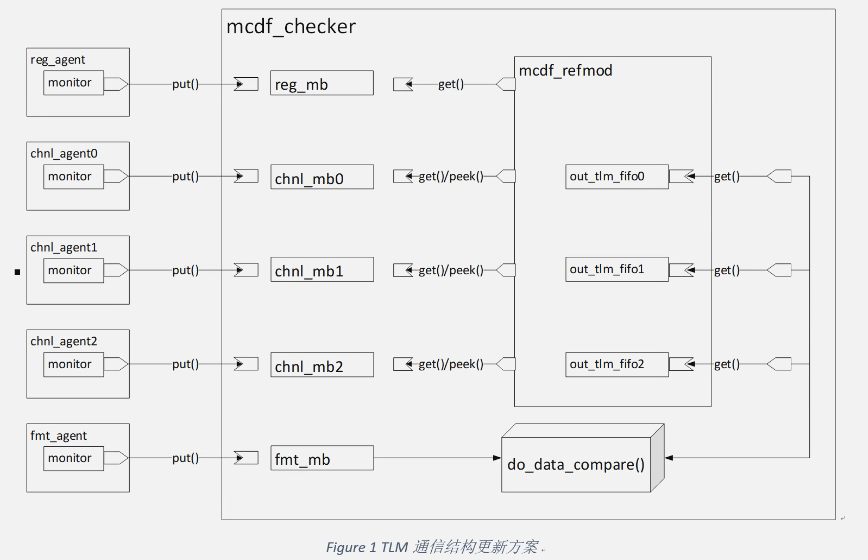
如图所示我们要修改的内容:
1.各个agent的monitor(chnl、reg、fmt)
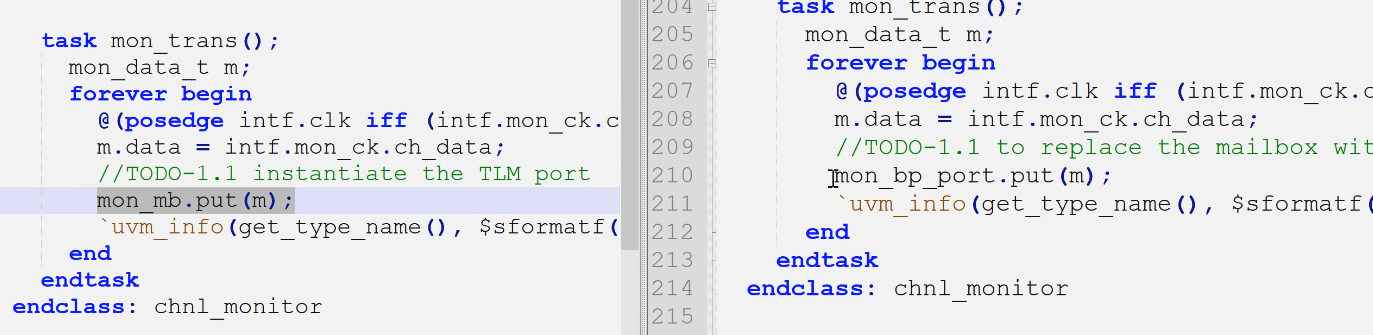
具体内容:请将在monitor中的用来与checker中的mailbox通信的mon_mb句柄替换为对应的uvm blocking_put_port类型
实现方案:
- 端口句柄添加

- 端口例化(要用new而不是create,因为它不是object)

- 端口发送数据给checker
2.checker
具体内容:
在checker中声明与monitor通信的import端口类型,以及与reference model 通信的import端口类型。具体类型可以参考代码中的注释,需要注意的是,由于checker与多个monitor以及reference model通信,是典型的多方向通信类型,因此,我们需要使用多端口通信的宏声明方法,请参考红宝书12.2.3的实例。在使用了宏声明端口类型之后,再在checker中声明其句柄,并且完成例化根据声明的import端口类型,分别实现其对应方法
实现方法:
- 外部5种端口宏声明(1)
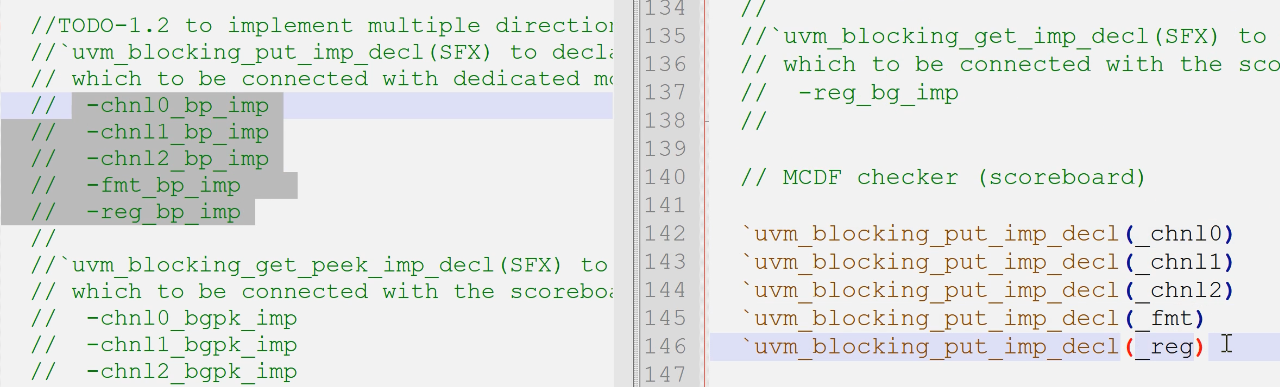
- 内部与refmod的4端口宏声明(2)
- 思考问题:get端口与get_peek不同是否可以不用宏声明?路科这里为了统一统一进行了宏声明
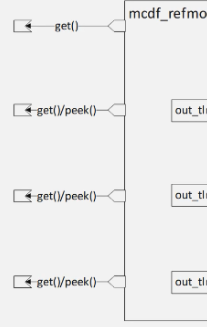

- 以上几个端口的声明

- 以上几个端口的例化
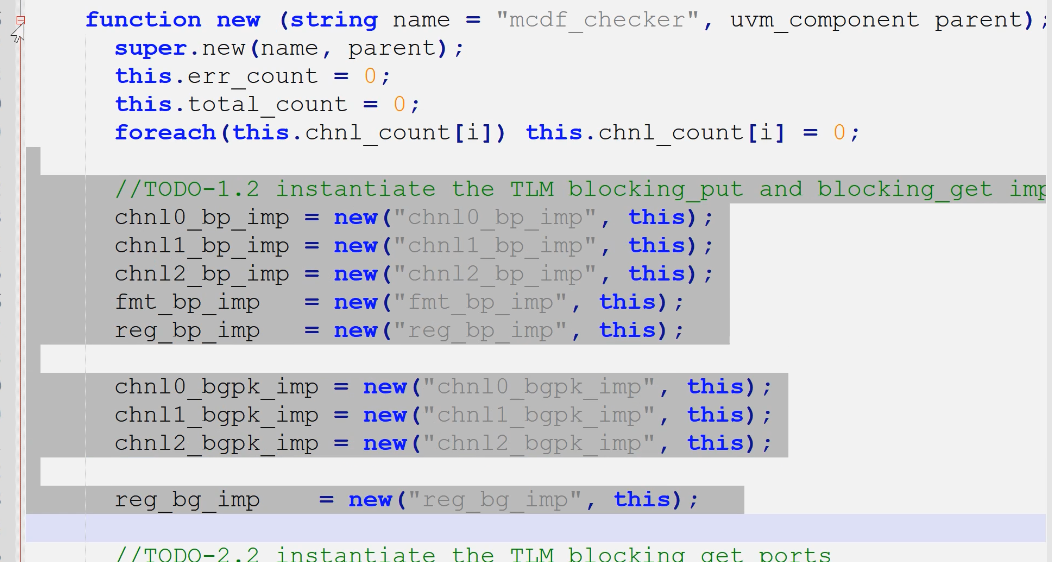
- 以上几个端口的方法实现(1.3)
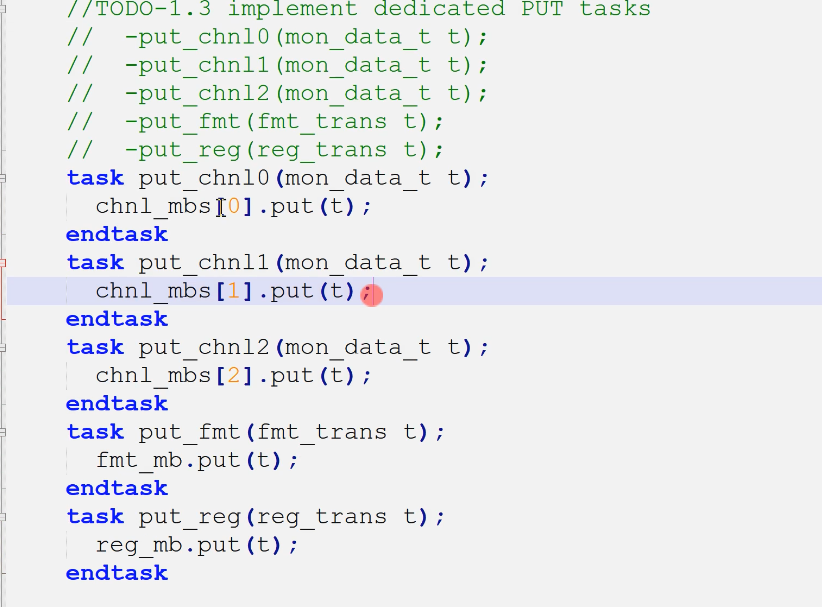
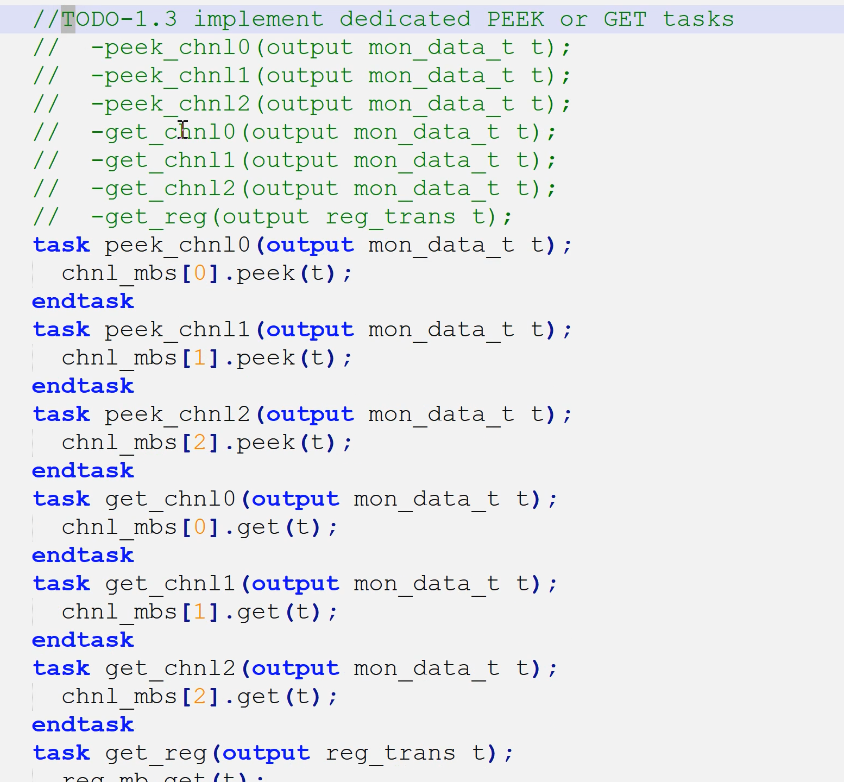
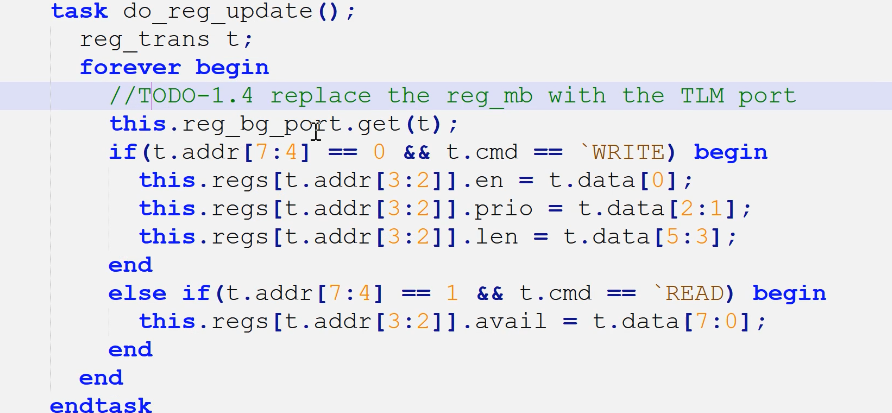
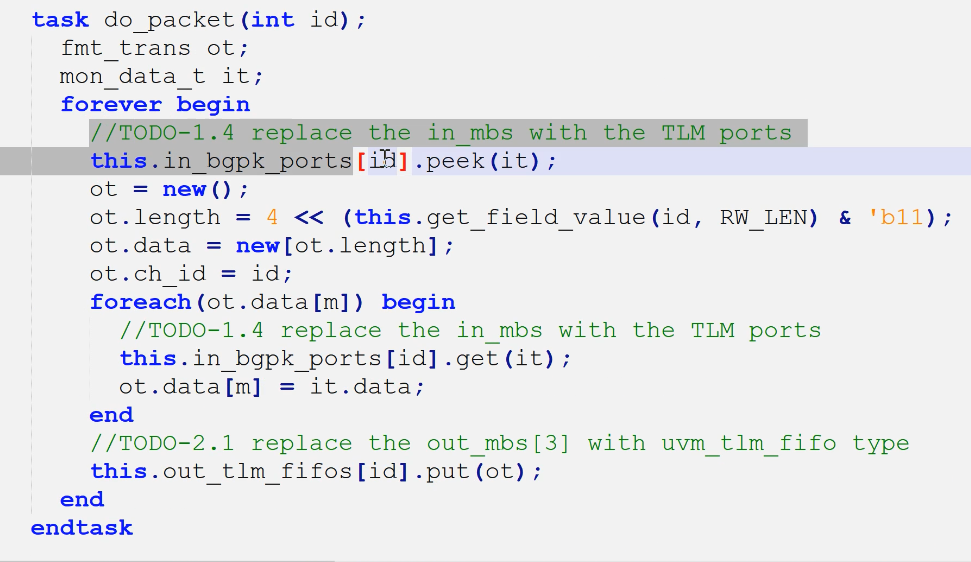
3.refmod(1.4)
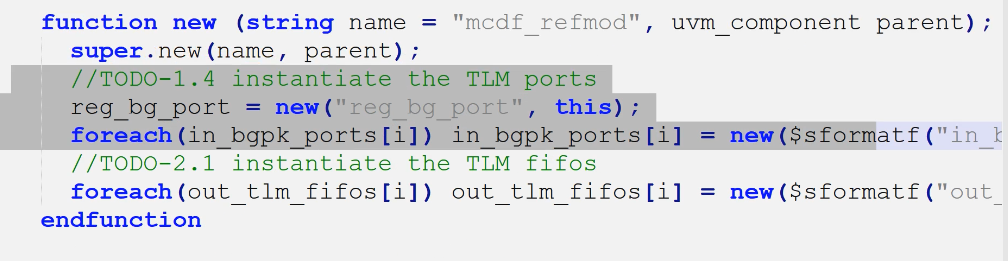
- 左侧4端口声明

- 左侧4端口例化
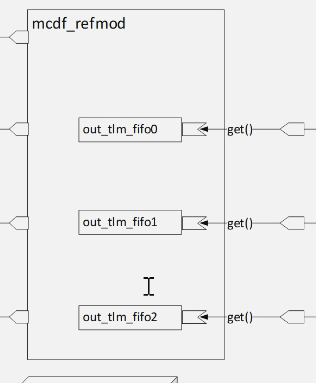
- 原有的fifo使用tlm_fifo替代(2.1为了练习通信管道)
- 通过port与验证环境进行交互
4.连接
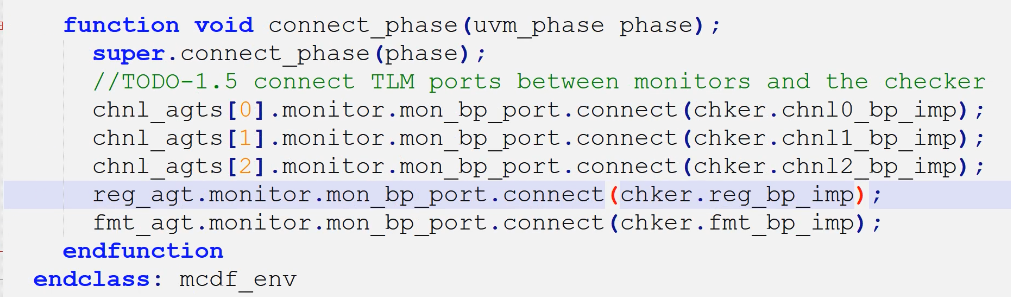
- monitor与checker
- 1.5请在mcdf_env的connect_phase()阶段,完成monitor的TLM port与mcdf_checker TLM import的连接
- 可以看到左边是agent,因为是agent发起的;右侧是checker的五个inport
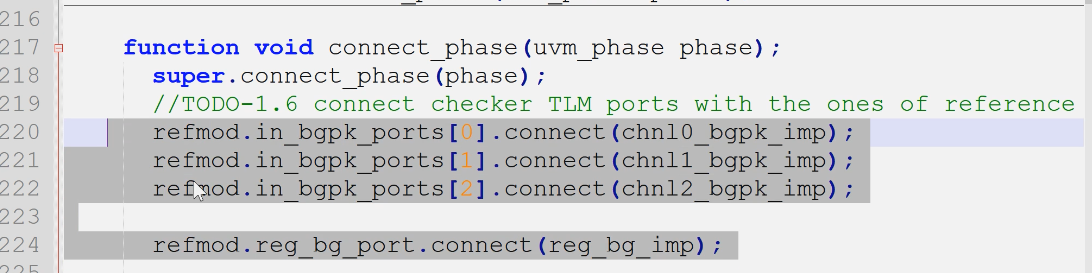
- checker与refmod
- 1.6请在checker的connect_phase()阶段, 完成mcdf_refmod的TLM port与mcdf_checker的TLM import的连接
- refmodel在左边,checker的inport在右边
TLM通信管道
在完成了上述实验之后,你可能会抱怨,看起来工作量增加不少了呢!怎么会说,TLM通信有它的好处呢?那路桑再阐述几个TLM通信的优点:
- 通信函数可以定制化,例如你可以定制put()/get()/peek()的内容和参数,这其实比mailbox的通信更加灵活
- 将组件实现了完全的隔离,可以参考红宝书图12.4,因为只有通过层次化的TLM端口连接,我们就可以很好地避免直接将不同层次的数据缓存对象的句柄进行“空中传递”。而TLM 端口按照层次的连接,虽然看起来有点繁复,但也正因为这一点,可以使得组件之间保持很好的独立性呢
如何不实现自己的put()/get()/peek()方法呢?当然有啦!依然可以参考红宝书12.3.1 节,关于uvm tm fifo 类的使用。请按照以下要求,完成本实验:
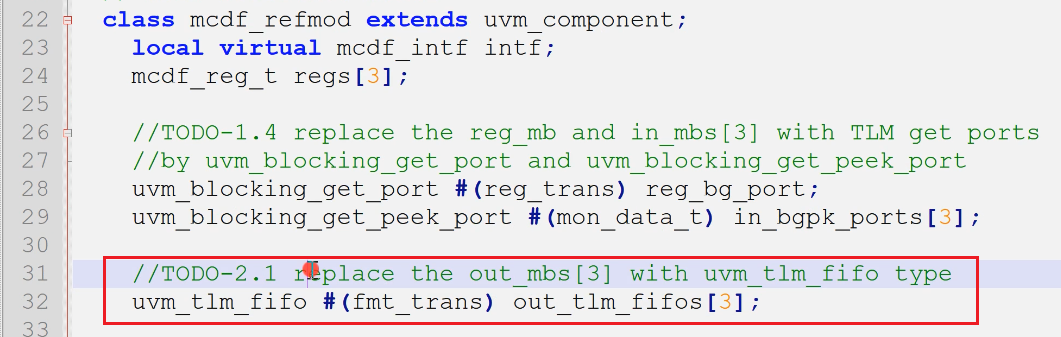
1.将原本在mcdf_refmod中的out_mb替换为uvm_tlm_fifo类型,并且完成例化,以及对应的变量名替换
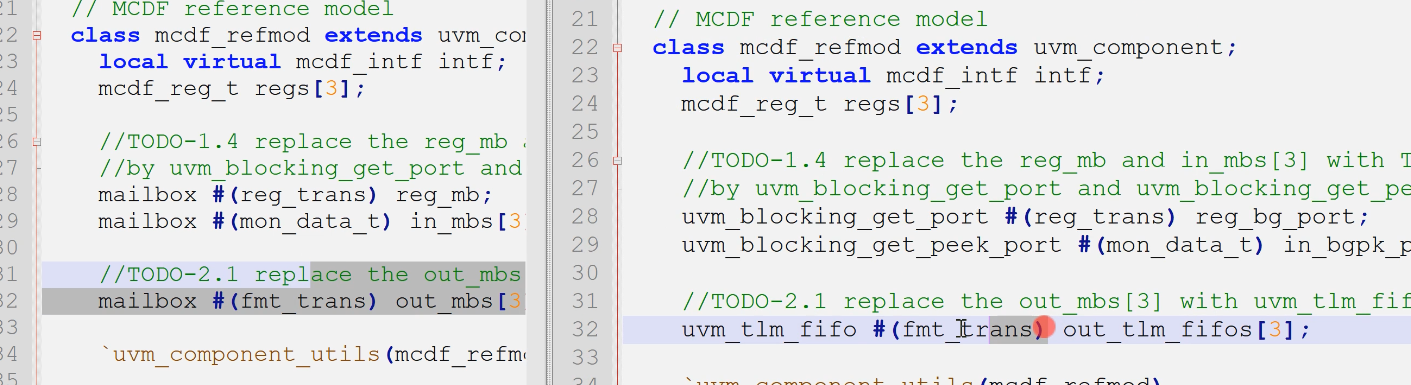
- 你不需要再为这些tlm_fifo再例化inport了
- 例化tlm_fifo,可以new也可以create,因为他是组件,且你不做override

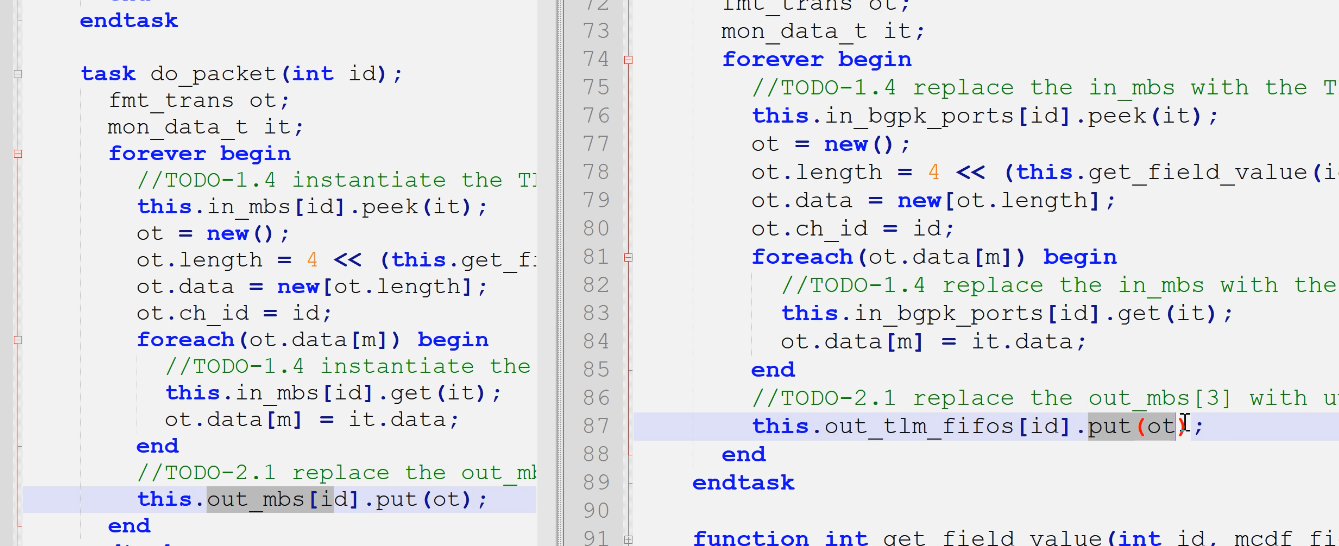
- mailbox的put改为tlm_fifo的put
2.将原本在mcdf_checker中的exp_mbs[3]的邮箱柄数组,替换为uvm_blocking_get_port类型柄数组,并且做相应的例化以及变量名替换
- 内容同上
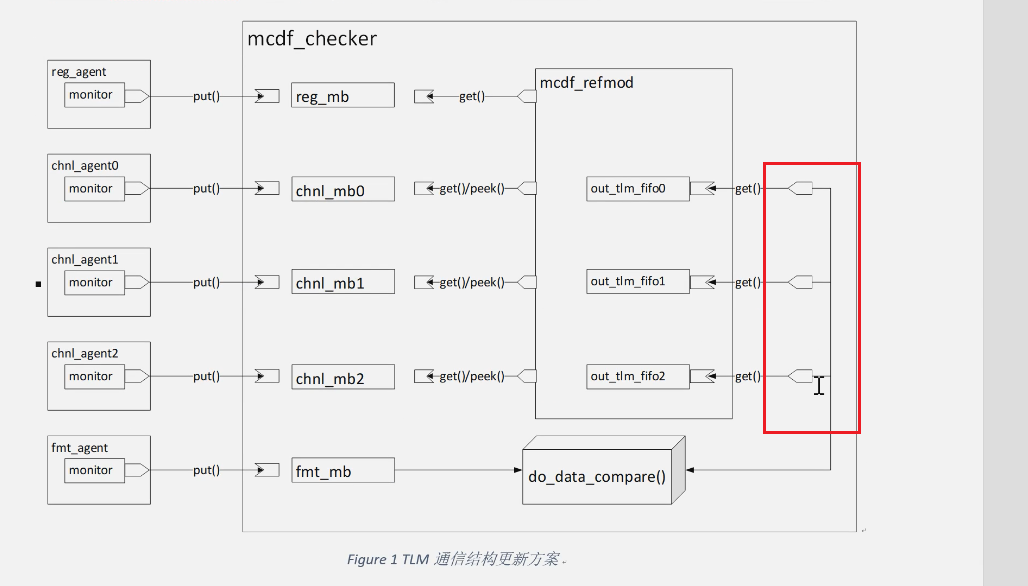
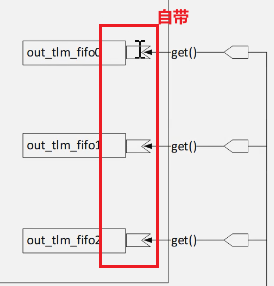
3.在mcdf_checker中,完成在mcdf_checker中的TLM port端口到mcdf_refmod中的uvm_tlm_fifo自带的blocking_get_expot端口的连接
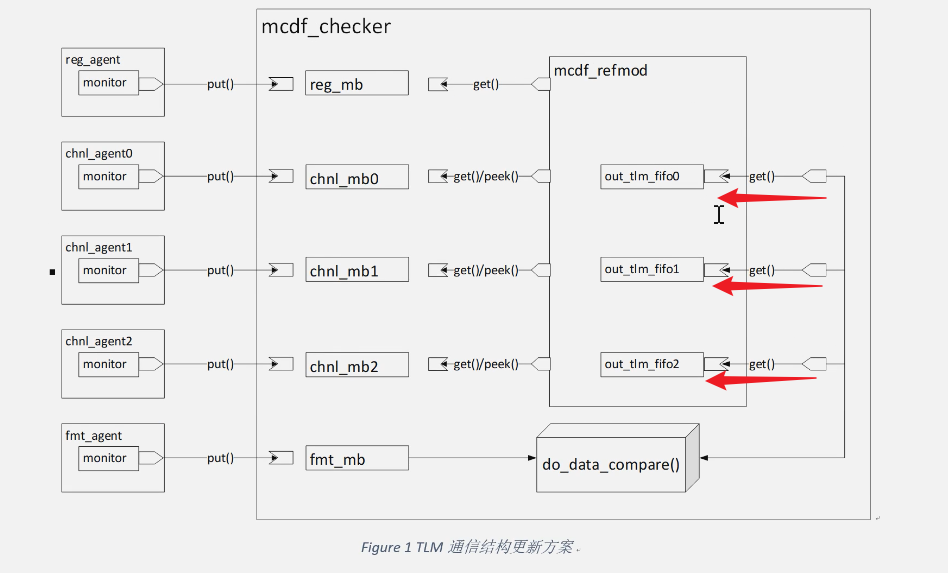

- 注意端口对应
在完成这个实验环节之后,请开始编译原有的仿真测试,进行仿真,检查仿真结果是否与实验2的结构保持一致。另外,请再思考,上述两个实验环节中,针对一般的数据存储和TLM端口连接,哪一种方式更为简便?
补充:为什么没有把这一部分也改成tlm_fifo?
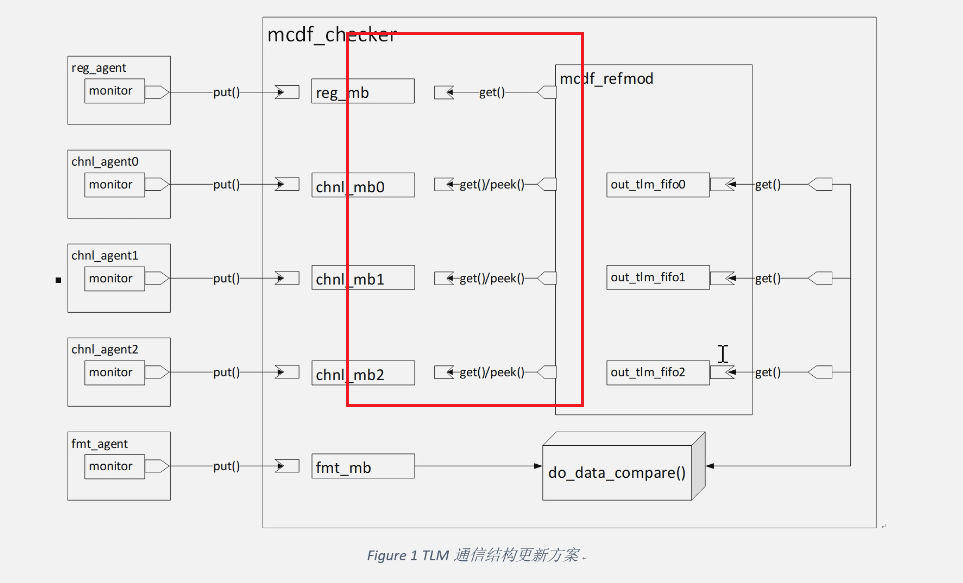
- 因为要练习mailbox做buffer如何自己实现方法
UVM回调类

内容:原有的测试用例是继承于mcdf_base_test,现在像用回调方式实现
原有的测试用例基于mcdf_base_test,自定义了:do_reg()、do_formatter()、do_data()
1.定义callback类,并预定义虚函数/任务

2.对base_test注册(绑定)

3.对base_test插入(3.2)
- 把callback里三个对应函数,插入进mcdf_base_test

4.定义测试用例的回调函数类,并预定义虚函数/任务
- 继承于第一步定义callback类
- 移植原有mcdf_data_consistence_basic中的三个
do_xxx()方法
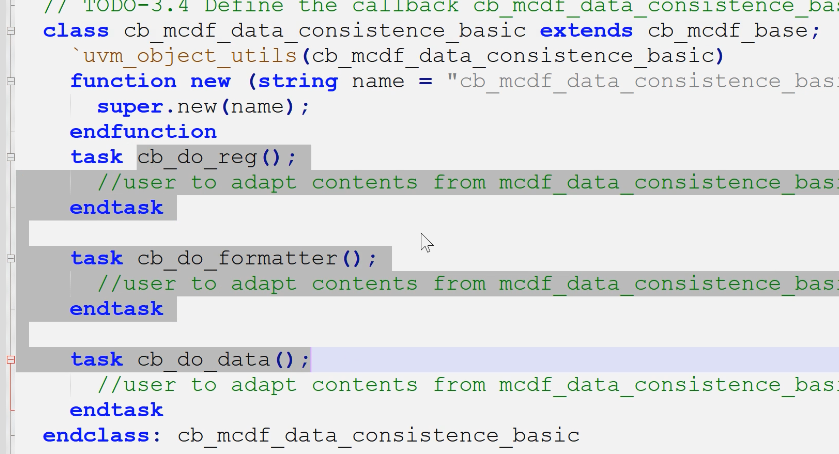
5.定义测试用例类,例化并添加回调类
- 父类为#参数
- 不用实现原有mcdf_data_consistence_basic中的三个
do_xxx()方法

UVM仿真控制方法

end_of_elaboration_phase九大phase之一,build、connect之后,run之前,作用是在环境运行之前再进行一些配置
查看mcdf_basic_test的end_of_elaboration_phase
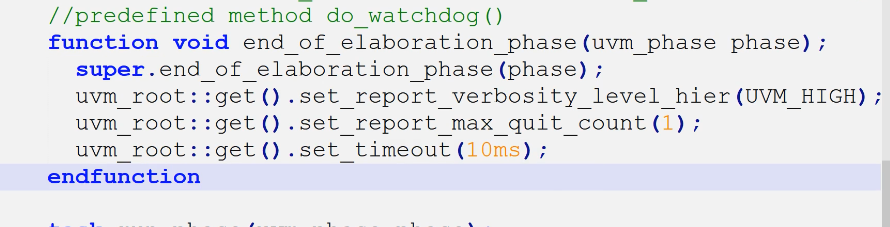
- 配置打印消息的冗余度
- 配置error最大退出消息次数
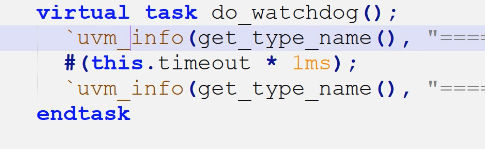
- timeout:代替do_watchdog(),watchdog()是检查仿真时间,如果超过设定阈值测退出,watch_dog()代码:
下一节
目前环境generator与driver仍然是mailbox,下一节讨论这几个通信:sequencer与driver、sequencer与sequence
lab3 TLM端口通信缓存与信箱的比较
TLM端口通信相比较信箱的三个优点:
1.可以不用缓存
考虑以下验证方案,其中monitor对scb和coverage model都是用analysis连接
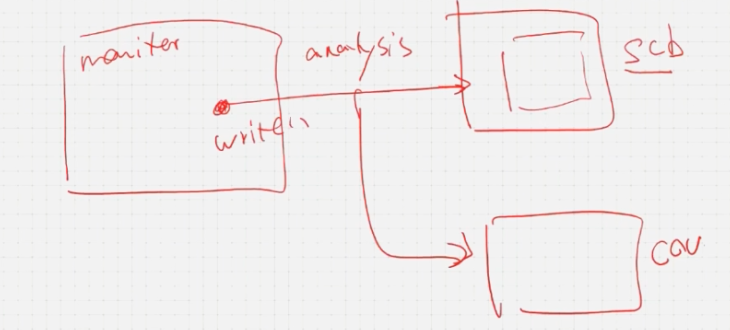
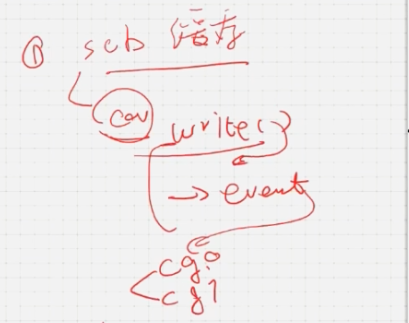
- 对于scb来说,需要从monitor来的数据进行缓存
- 对于coverage model来说,可能不需要进行缓存,而是调用write函数,write函数触发一个event,这个event让不同的covergounp进行采样
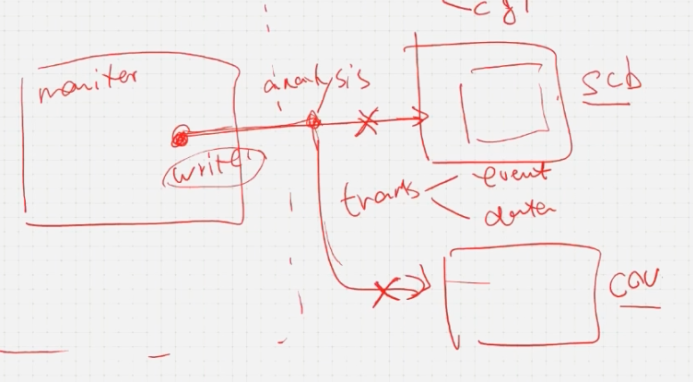
2.TLM端口支持空发送
同样以上面的验证环境为例,如果你不需要scb和coverage model大可以删除,monitor的端口可以空发;而mailbox不行,它的句柄为空会报错
3.跨层次问题
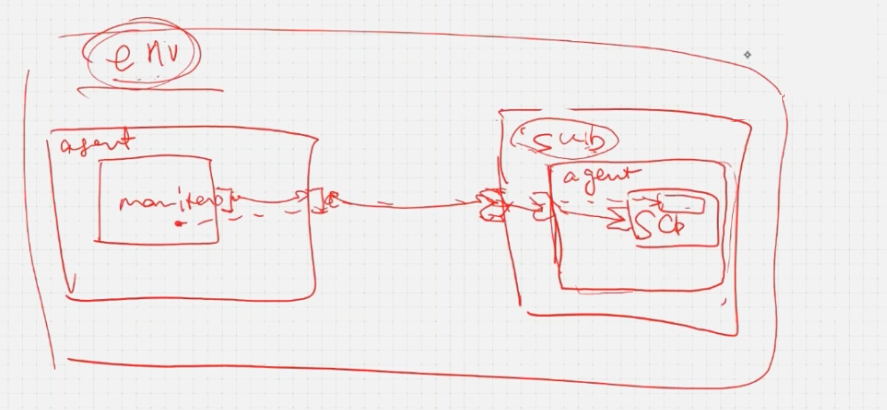
mailbox仍然是在顶层进行句柄的连接,这样如果sub组件外面嵌套另外一个组件时,需要改变顶层调用的路径
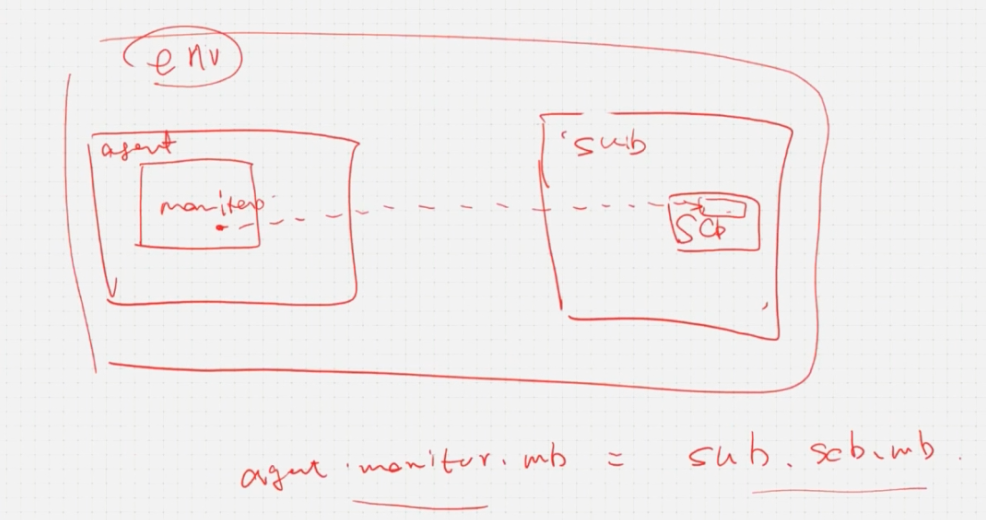
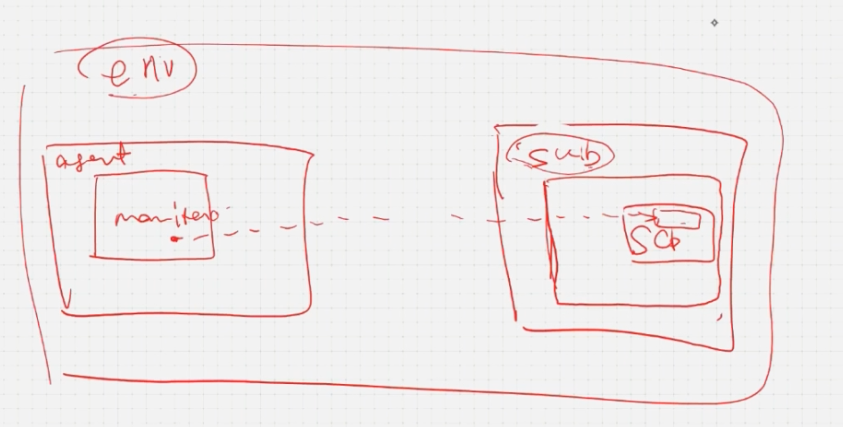
使用TLM组件,一层一层进行端口连接则不存在顶层修改路径的问题,只需要对新嵌套的组件进行连接即可
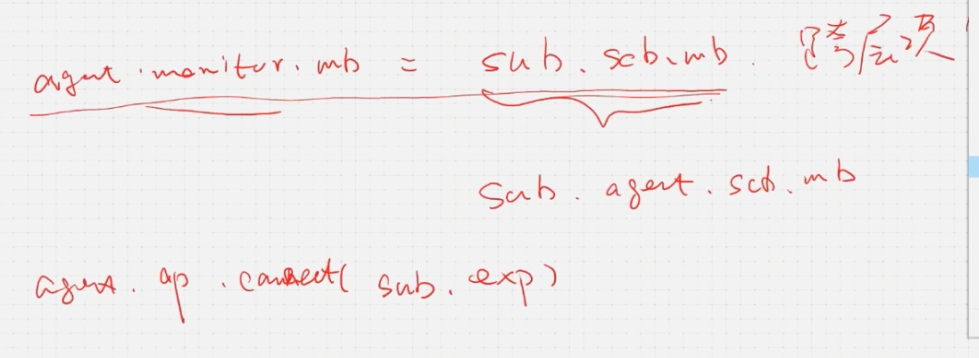
lab3 回调与继承的应用区别
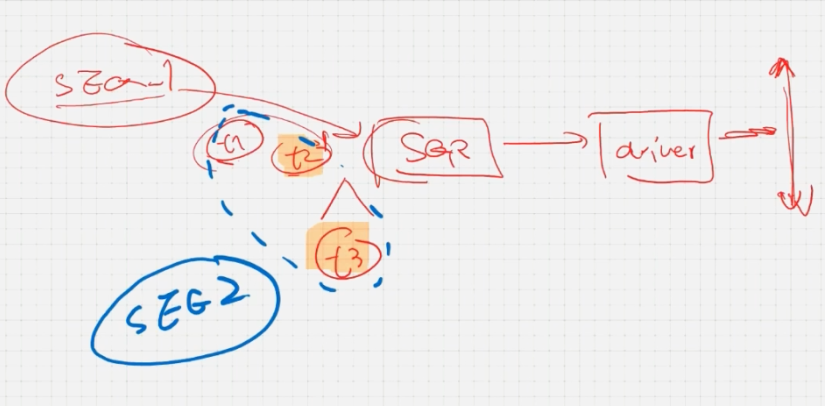
错误的插入,讲的很抽象
一般的错误插入方法,实际上我们不这么做:写错误的SEQ,其中涂橙色的是错误的transaction,SEQ1用于发送正常的trans,SEQ2用于发送错误的trans
实际的错误插入方法,更省事更易于复用的错误插入:通过使用uvm_callback
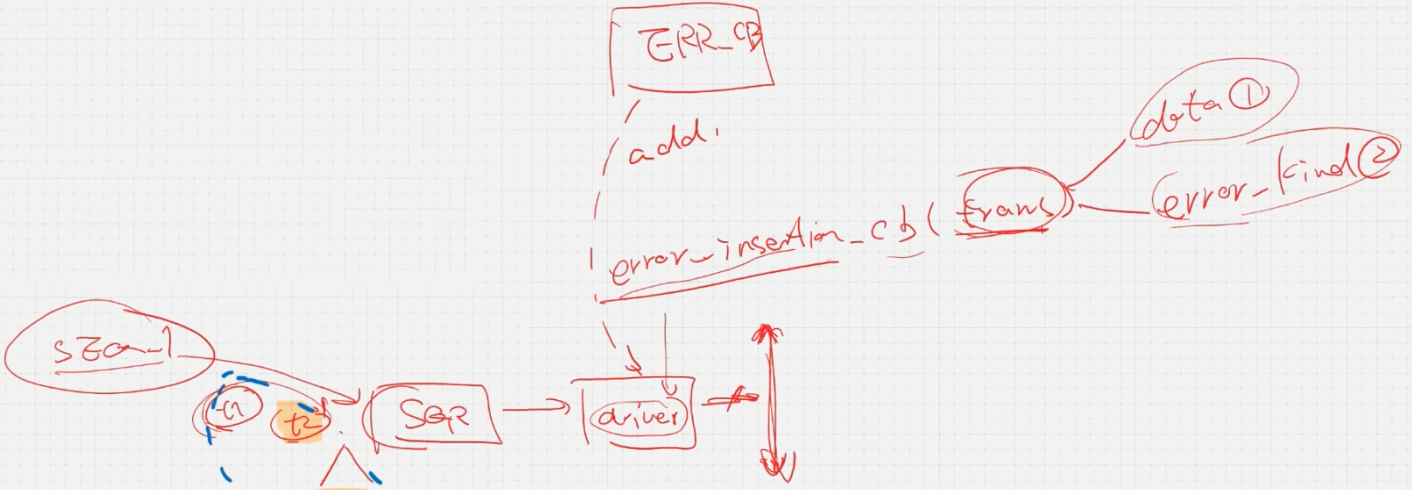
话说为什么我们要插入错误?当我们对安全性能要求较高的时候
其他体现回调的例子我没仔细听,路科也就随便一带
什么时候用callback?我需要做一些局部手术,不需要子类继承父类,去override写一大段,只是在原类添加代码
我们的实验例子没有体现callback的魅力
UVM入门和进阶实验4
介绍
在实验4中,我们将主要完成以下内容:
- 将产生transactian并且发送至 driver的generator组件,拆分为 sequence与sequencer
- 原generator产生+发送trans
- 现sequence产生trans/item,sequencer发送trans/item
- 在拆分的基础上,实现底层的sequence
- 完成sequencer与driver的连接和通信工作
- 构建顶层的virtual sequencer
- 将原有的mcdf base test拆分为mcdf_base_virtual_sequence与mcdf_base_test前者发挥产生序列的工作,后者只完成挂载序列的工作
- 将原有的mcdf_data_consistencebasic_test和mcdf_full_random_test继续拆分为对应的virtual sequence和轻量化的顶层test
内容
1.1-1.3 集中讲reg_pkg.sv,fmt_pkg与chnl_pkg类似
1.4主要在mcdf_pkg中
1.1 driver与sequencer的改建

driver不再需要mailbox句柄,而是seq_item_port的一个port(uvm_driver内部成员,自带)

以前利用req_mailbox拿到req,并通过rsp_mailbox发送rsq;
现在通过seq_item_port.get_next_item(req)拿到,通过item_done(rsq);返回
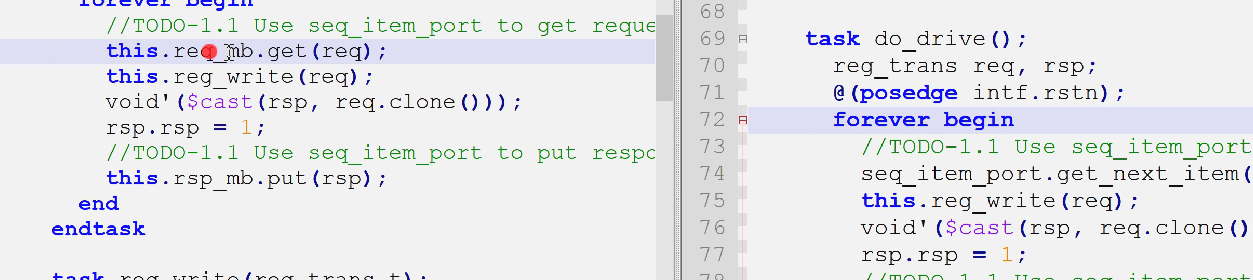
1.2 底层sequence的提取

原有的xxx_reg()是调用的generator来进行的操作,现在我们没有generator而是sequence,所以要有对应的sequence而移除generator
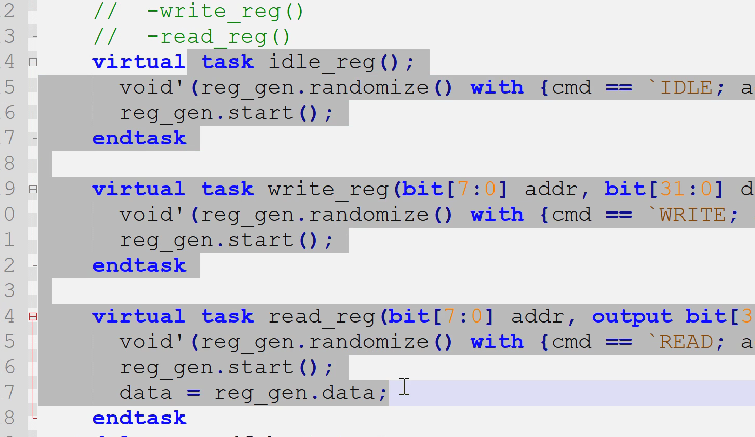
把generator修改为sqr与对应的seq
reg_sequencer

- sqr很简单,注意额外的参数类reg_trans
reg_base_sequence
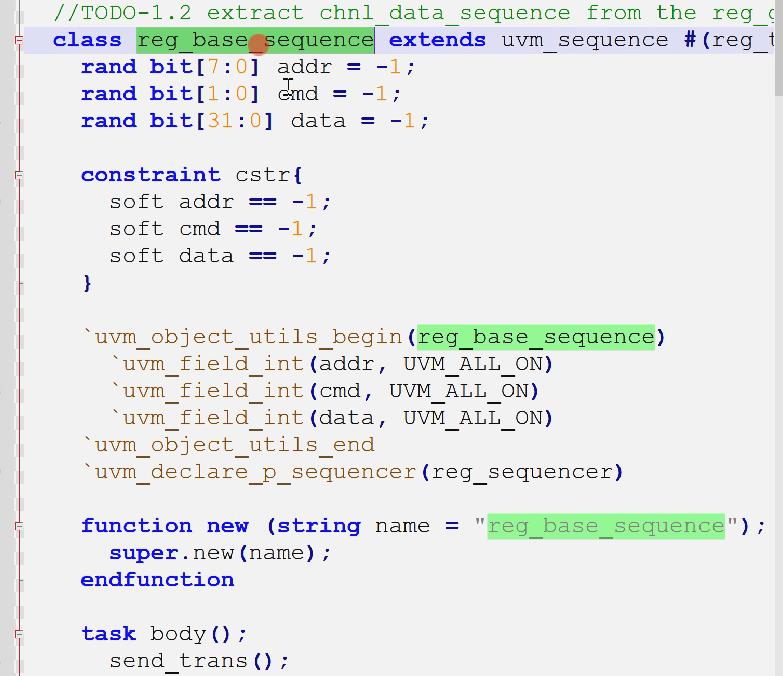

- seq包含随机的变量、约束、发送,实际上就是把generator的产生数据的部分搬过来了,只不过不再使用句柄创建mailbox了
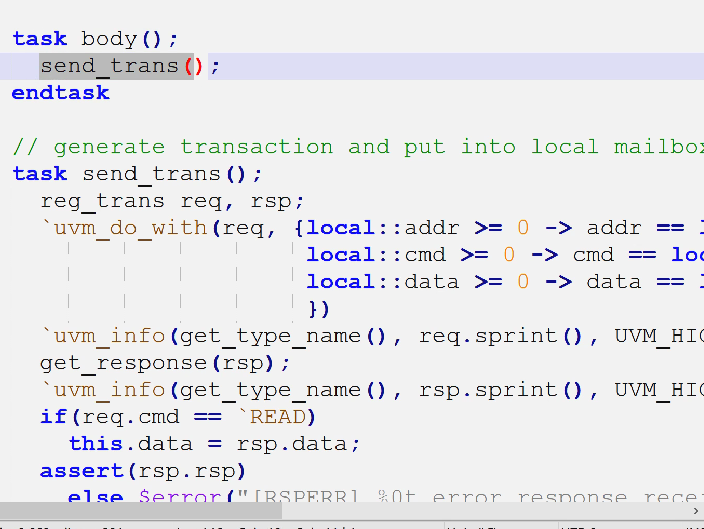
- 以前数据的握手是通过req = new(),req.randomize(),req_mb.put(req)与rsq_mb.get(rsq)
- 现在数据握手非常简单,通过uvm_do_with,即创建、又随机化、又发送,get_response获取响应
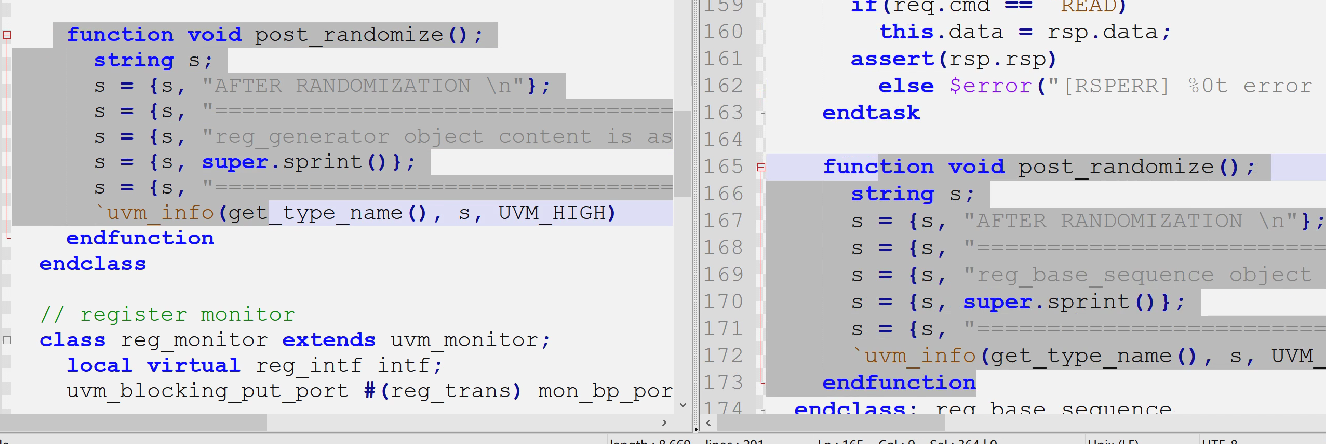
- post_randomize()没变
idle_reg_sequence

- 继承于reg_base_sequence
- 就是对cmd增加了
`IDLE限制
write_reg_sequence与read_reg_sequence


- 继承于reg_base_sequence
- 就是对cmd增加了限制
- 为什么没对addr增加约束?因为我们要在外部,调用write_reg_sequence与read_reg_sequence时,加以做约束
idle_reg_sequence,write_reg_sequence与read_reg_sequence
- 实际上就是generator中的这三个函数对应的sequence,进行了转化
1.3 sequencer的创建连接

在agent里面声明sqr句柄

在agent里面sqr的创建和连接

1.4 移除generator的踪迹

接下来的改动主要在mcdf_pkg中
以前的generator都在test里面,现在的sqr都在agent里面,所有的seq会被组合到vseq里面
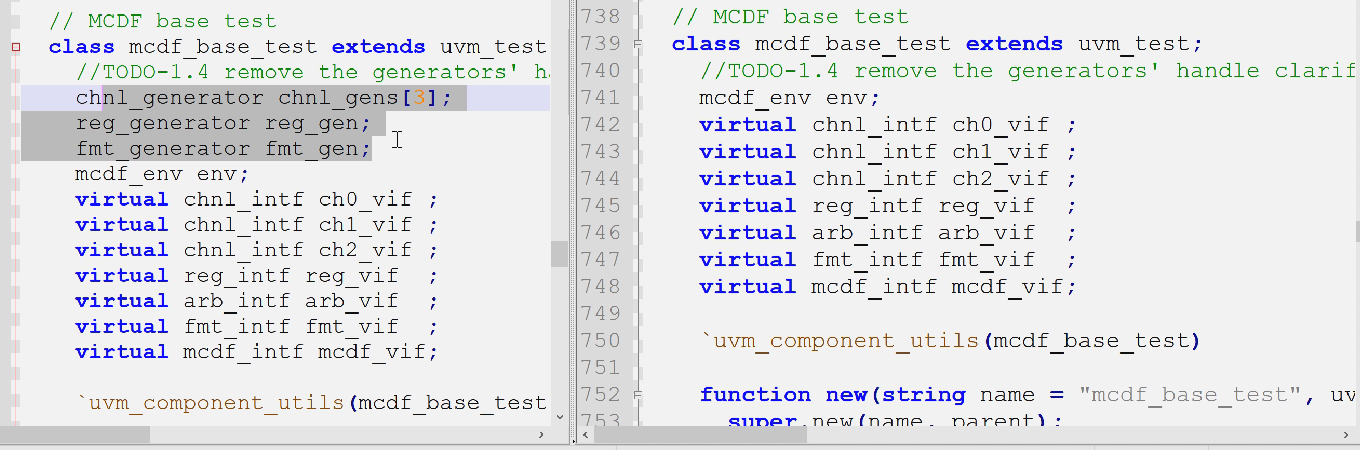
- 删除句柄(以前的generator都在test里面,现在的sqr都在agent里面,所有的seq会被组合到vseq里面)

- 删除例化
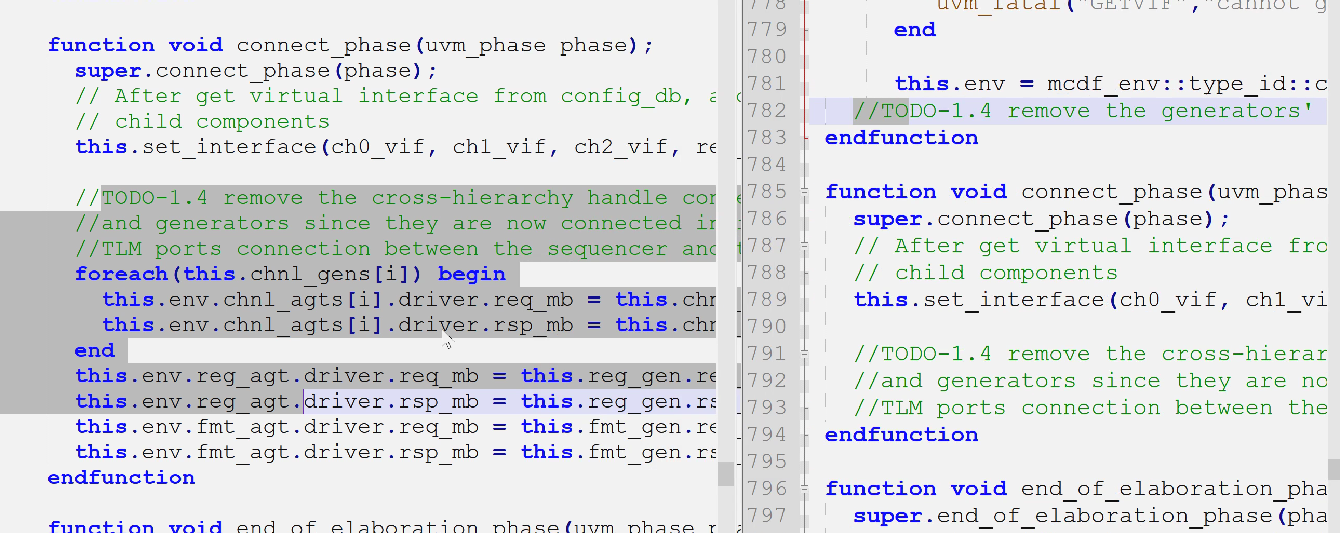
- 删除连接
1.5 移除uvm_base_test的transaction发送方法

以前uvm_base_test
- 既具有容器的性质例化env,例化各个generator
- 又具有例化场景描述的作用,协调各个generator进行do_reg、do_data,do_formatter
现在的uvm_base_test变成了容器的性质,它主要由mcdf_env,将来要添加的mcdf_config,以及被用来挂载的顶层virtual sequence构成。场景的描述由挂载的顶层virtual sequence实现
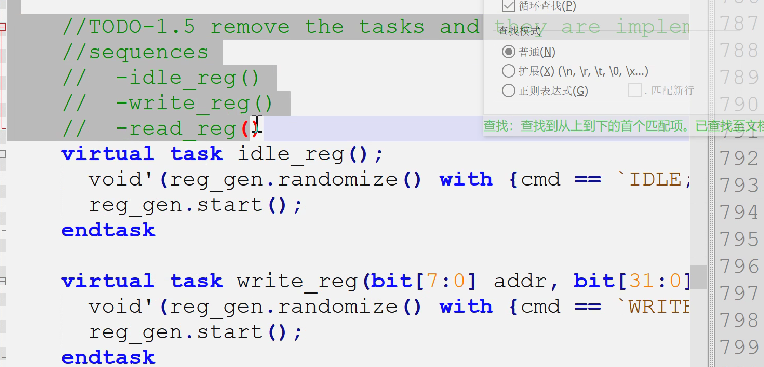
- 删除idle_reg,write_reg,read_reg(我们已经改造为对应的seq了)
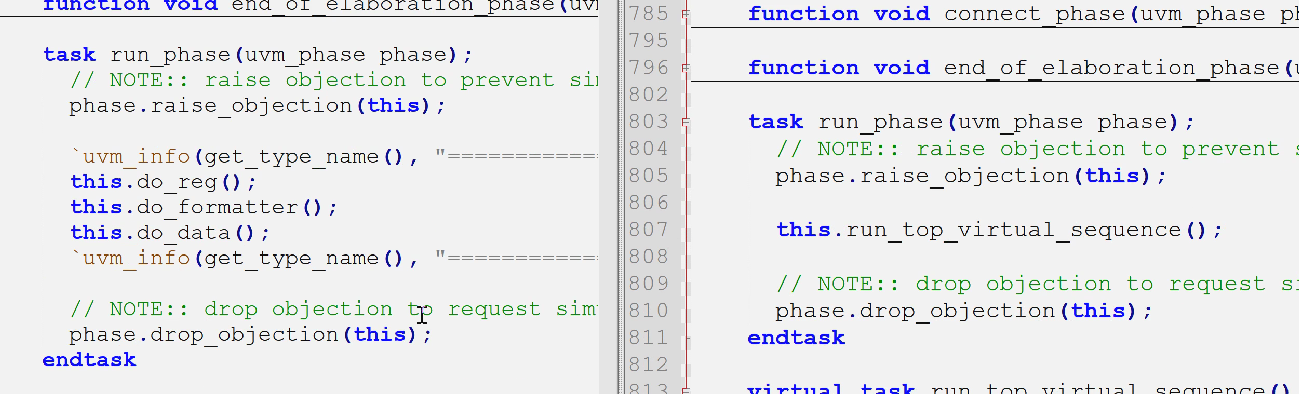
- run不一样了,不需要控制了,而是增加了一个run_top_virtual_sequence方法
- run_top_virtual_sequence作用就是挂载
- vsqr挂载、vseq挂载

- 三个do移除了
1.6-1.7 添加顶层的virtual sequencer

mcdf_virtual_sequencer

- 就是添加了各个sqr句柄



- mcdf_env中做声明、例化和连接
- 把各个底层的sqr句柄都赋值给顶层vsqr的句柄
1.8 重构mcdf_base_test

实际上是对mcdf_base_test的拆解:
- 我们之前把do_data,do_reg,do_config都删除,只定义了一个run_top_virtual_sequence()
- 场景描述主要在run_top_virtual_sequence里面
mcdf_base_virtual_sequence

- 对各个底层的seq进行声明
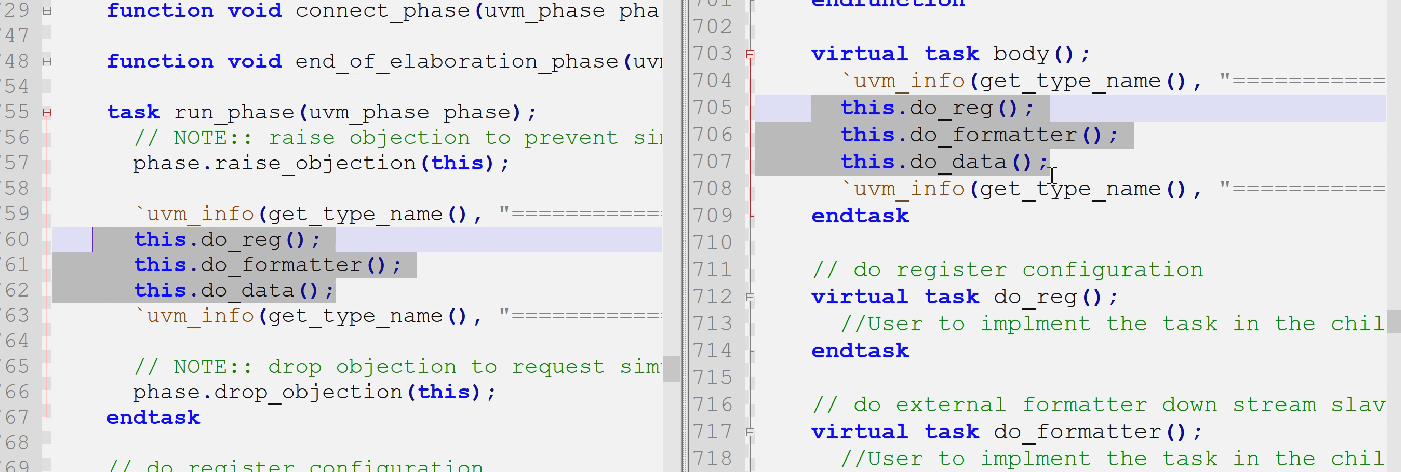
- body和base_test的run的任务一样
- 为什么mcdf_base_virtual_sequence的do_reg、do_formatter、do_data都是空的?因为要被继承的seq镜像描述
1.9 重构mcdf_data_consistence_basic_test

实际上是对mcdf_data_consistence_basic_test的拆解
mcdf_data_consistence_basic_virtual_sequence
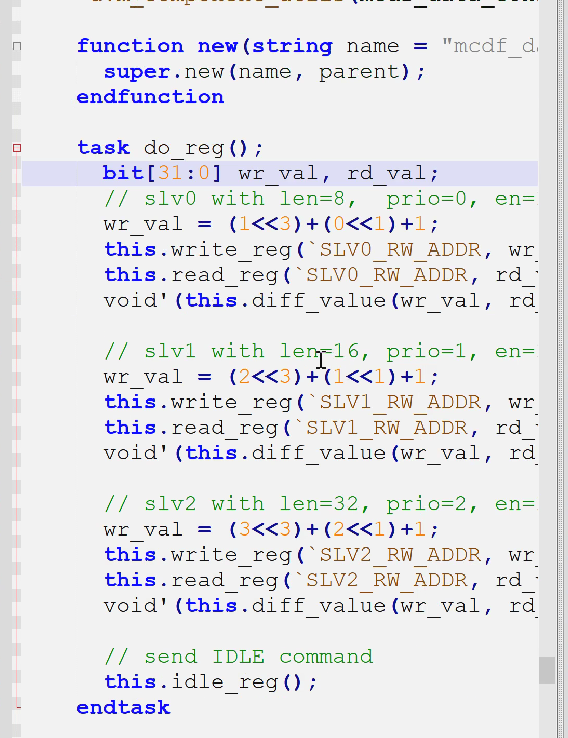
- 以前,分别调用了base_test的三个任务

- 现在,使用uvm_do_on_with,on挂载到对应sqr,并发送with的数据
mcdf_data_consistence_basic_virtual_sequence分别发送了属于不同sqr的seq
mcdf_data_consistence_basic_test

- 顶层的测试用例会非常清爽
- 做了例化:top_sqe = new()
- 做了挂载:top_seq.start(env.virt_sqr)
我们发现:往往一个virtual sequence会跟着一个名称一致的test
1.10 重构mcdf_full_random_test
mcdf_data_random_virtual_sequence
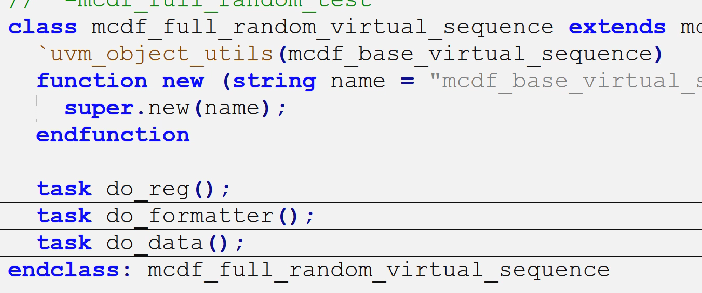
mcdf_data_random_test

小总结
实验4主要是把各个测试用例功能拆分,分为容器与场景的描述,其中
- 容器为uvm_test衍生类
- 场景描述为virual sequence,名称与uvm_test衍生类类似
virtual sequence不再使用write_reg、read_reg而是使用uvm_do_on_with
实验5主要是把以前对寄存器读写测试的部分,改造为利用寄存器模型,利用lay sequence不再利用reg的bus transaction,通过高抽象级的读写测试
结构小总结
目前结构:
顶层为衍生于base_test的测试用例,可以看作一个容器
- base_test主要内容:
- 创建env
- 获取intf,并连接到env内部各个组件
- 控制phase(run_phase,connect_phase,end_of_elaboration_phase)
- 特定测试用例功能
- 创建并启动特定的top_seq(vseq)
特定的top_seq,是一种vseq,衍生于base_vseq,主要是对验证场景进行描述
base_vseq主要内容
- 定义body结构,通过运行do_reg、do_config、do_data任务的结构完成整个验证场景
- 设置对应的vsqr
- 声明各种seq句柄
特定的top_seq主要内容
- 重载do_reg、do_config、do_data来实现具体内容
- 重载时需要启动不同的seq,并给这些seq指定sqr
- 这些seq,通过这种方式完成了从seq->vseq->vsqr->sqr的连接,最终由验证环境中的driver获取到并发送到总线接口
seq,vseq,vsqr,sqr分别在哪?
- seq在vseq中启动(同时也创建了)
- vseq在特定测试用例中启动(同时也创建了)
- vsqr在env中例化
- sqr在各个agnet中例化
如何连接的?
- vseq与vsqr:vseq在特定测试用例的启动中被指定了vsqr
- vsqr与sqr:在env中通过句柄进行连接
- seq与sqr:seq在vseq的启动中被指定了sqr
- sqr与drv:在agnent通过
seq_item_port.connect(sequencer.seq_item_export);进行连接 - drv与dut:通过接口连接
为什么在两个地方调用了`uvm_xxx系列宏
- 在vseq中调用了:
`uvm_do_on_with,主要是实现嵌套的启动seq,并且给这个seq添加了新的约束并绑定了p_seq - 在seq中调用了:
`uvm_do_with,主要是为了发送trans,并给这个trans添加了基础的约束
注意这两个约束的关系,vseq中的约束影响到的是seq中的rand变量约束,而这些变量又有一部分参与到seq中对trans约束的计算中了,从而完成了约束的传递
为什么声明了这么多seq?
1 | |
主要为了,通过sequence,对实现原来base_test的发送激励/获取响应行为,进行抽象
这些行为,有些是具备特定功能的如:
1 | |
有些则是单纯对generator的随机化与启动(其实这两个也可以封装成为像上面对reg的一样的函数,只不过源码都直接放在do_formatter与do_data任务里面了
1 | |
1 | |
为什么?因为我们现在的发送激励是通过seq进行的,seq承担了trans生成与发送的任务
lab4 测试场景为什么在序列而不在test
lab4 从SEQ到DRV的item传输类型转换
create_item
UVM入门和进阶实验5
介绍
寄存器模型是为我们提供便利的,因为对于硬件来说寄存器是结构化的,一定可以生成model,结构化的东西做一些内建化的测试序列,方便我们做测试,收集覆盖率,方便我们生成一些更好复用的sequence,也就是说现在没掌握好
在实验5中,我们将主要完成以下内容:
- 对uwm_reg的定义,以及uvm_reg_block的组织
- 对uvm_reg_adapter的定义,以及它与uvm_reg_block之间的关系
- 对uwm_reg_predictor的使用,以及它与uvm_reg_adapter和uvm_reg_block之间的关系
- 改造之前的寄存器发送序列,并以uvm_reg的操作方式去取代
- 应用内建的寄存器序列,做全面的寄存器测试
与之前实验内容的不同?
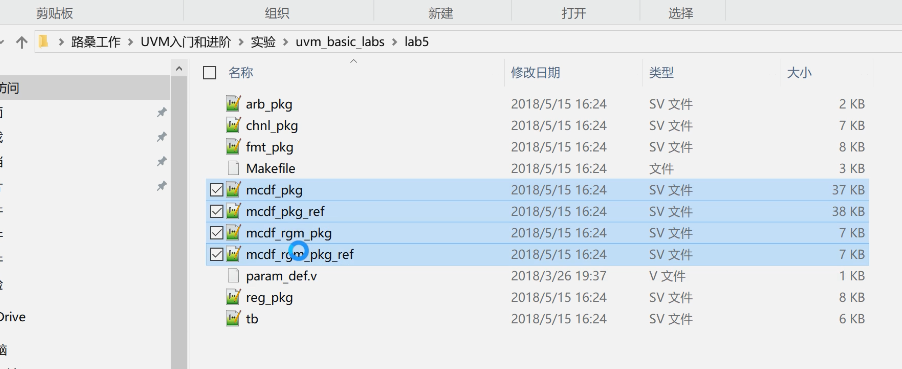
- 增加了mcdf_rgm_pkg
- 为了集成寄存器模型而对mcdf_pkg进行了修改
rgm的优先:
- 最主要是通过减少原来实现过程中sequence的使用,从而以一种更简单的方式访问寄存器
- rgm相比较其他访问寄存器的方式,提供了更多的功能,比如访问保证了可以在外部实时同步寄存器状态、同时不需要提供绝对路径进行后门访问,更规范化的路径和地址空间映射
- UVM其他的一些特性,使用UVM的内建方法进行寄存器测试使用UVM提供的方法收集寄存器覆盖率
内容
寄存器模型的完善和嵌入
1.0 uvm_reg和uvm_reg_block的定义已经完成



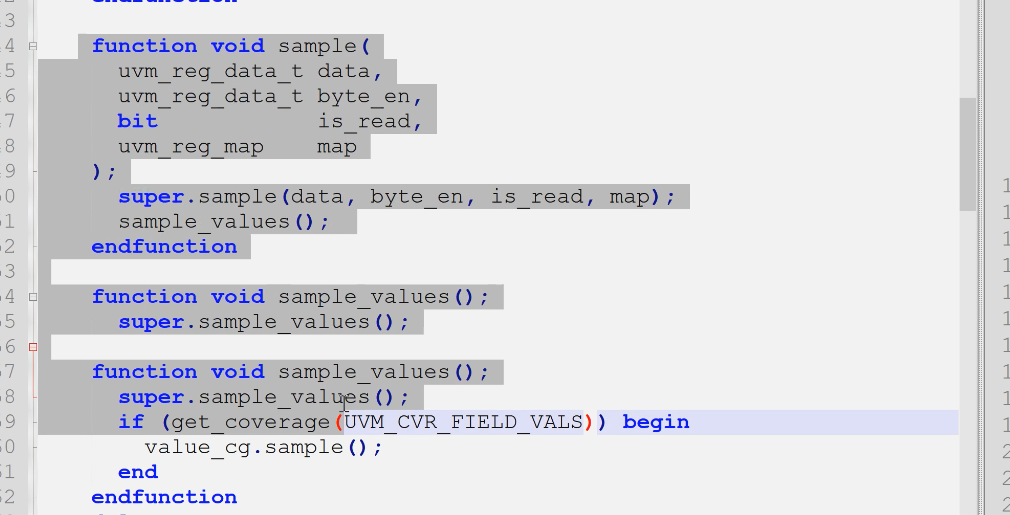
定义ctrl_reg、stat_reg:
- field
- covergroup
- 创建与config
- sample()与sample_values()

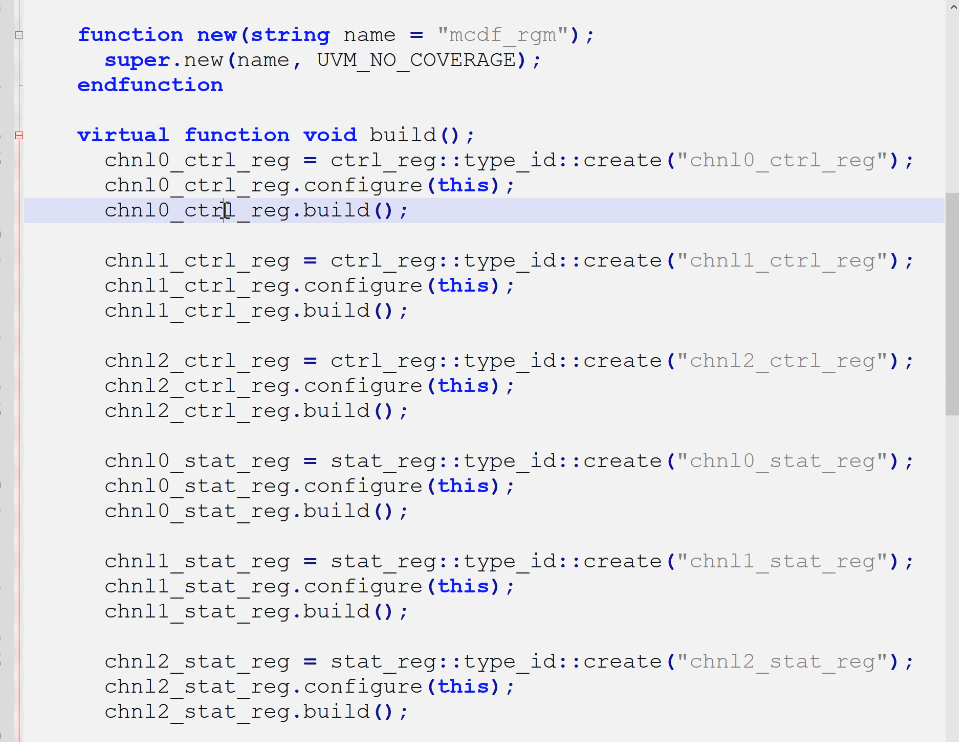
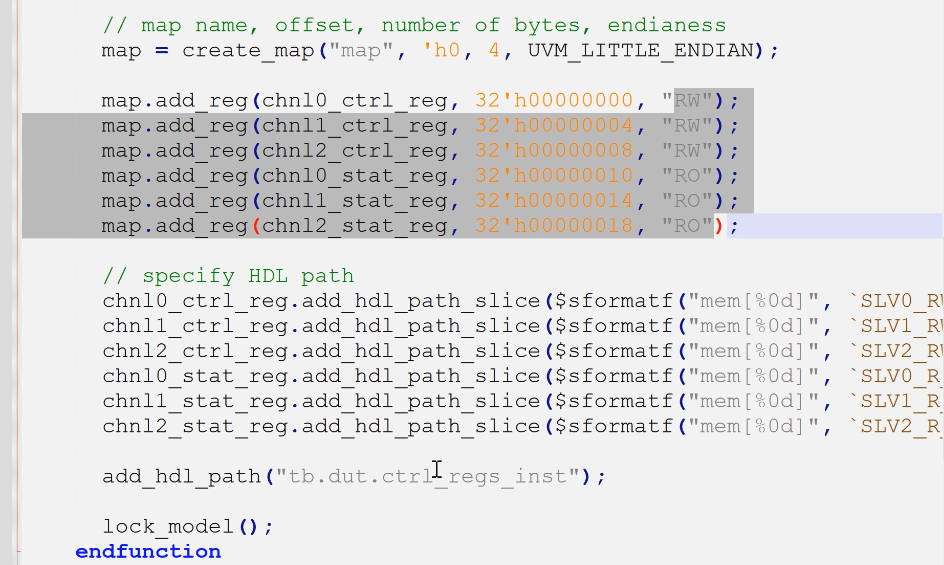
定义block:
- 6个reg
- build,调用每一个reg的创建与配置
- 添加default_map,与地址添加,field与block添加hdl路径
1.1 实现reg2bus以及bus2reg
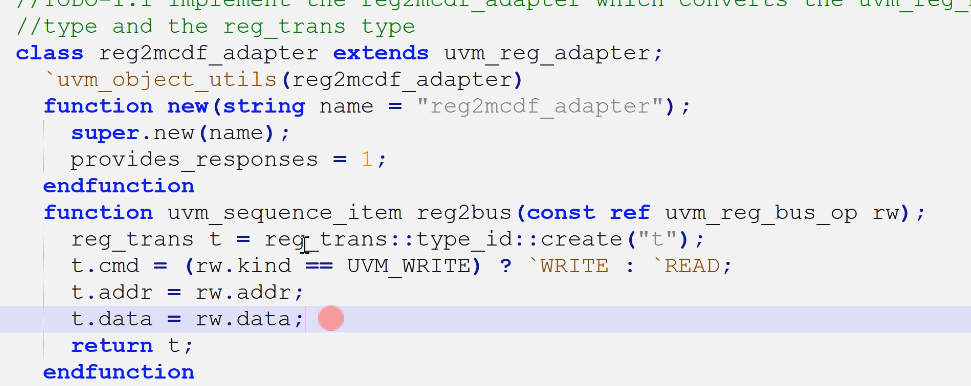
- reg2bus

- bus2reg
1.2 mcdf_env集成

- 声明rgm、adapter、predictor
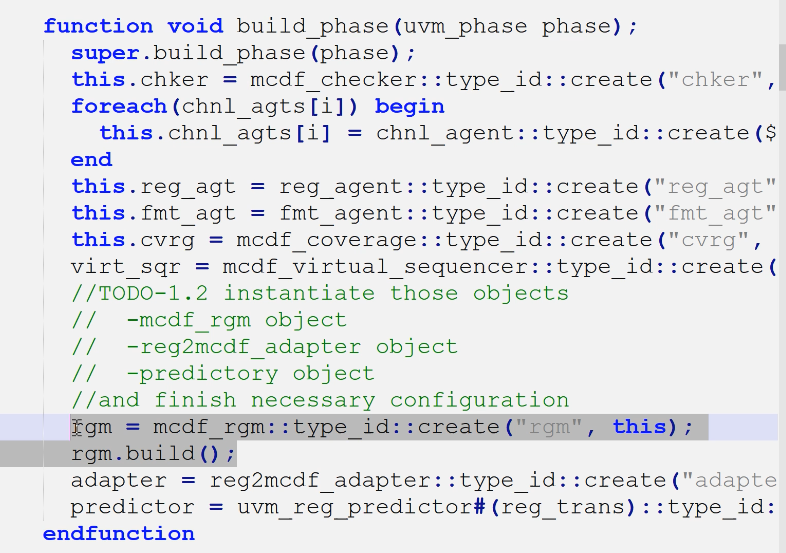
- 创建
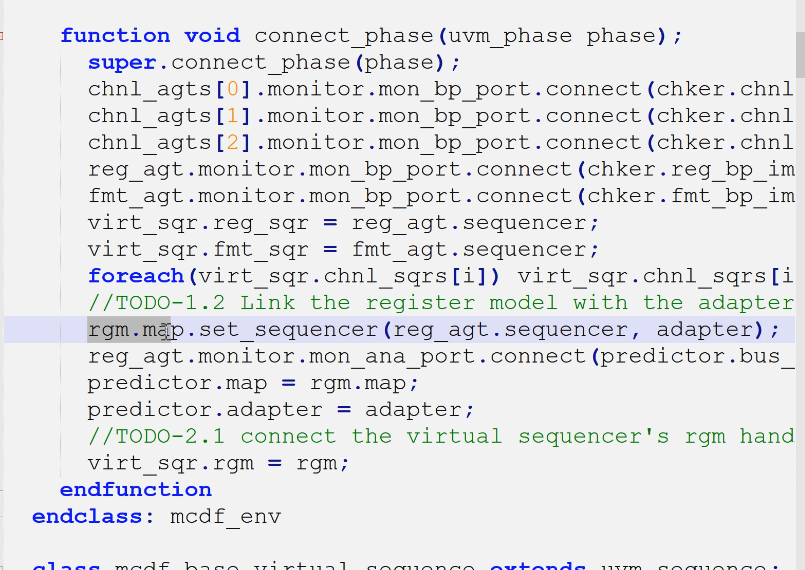
- 连接
- adapter需要map、sqr
- predictor需要ap
- predictor需要rgm
- predictor需要adapter
寄存器模型的使用

2.1 rgm句柄传递
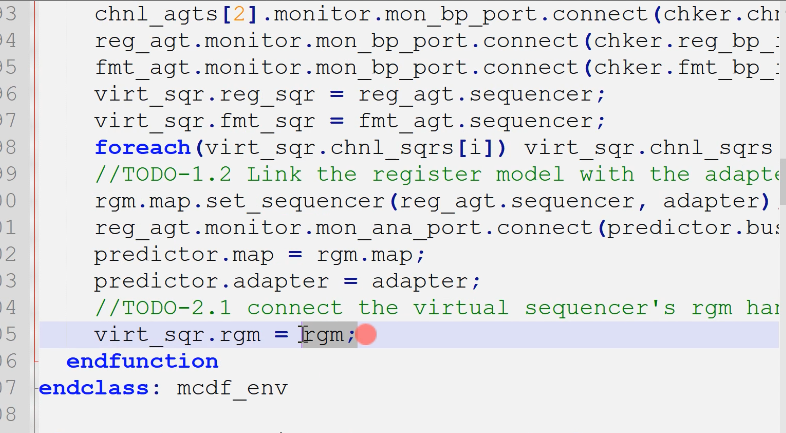
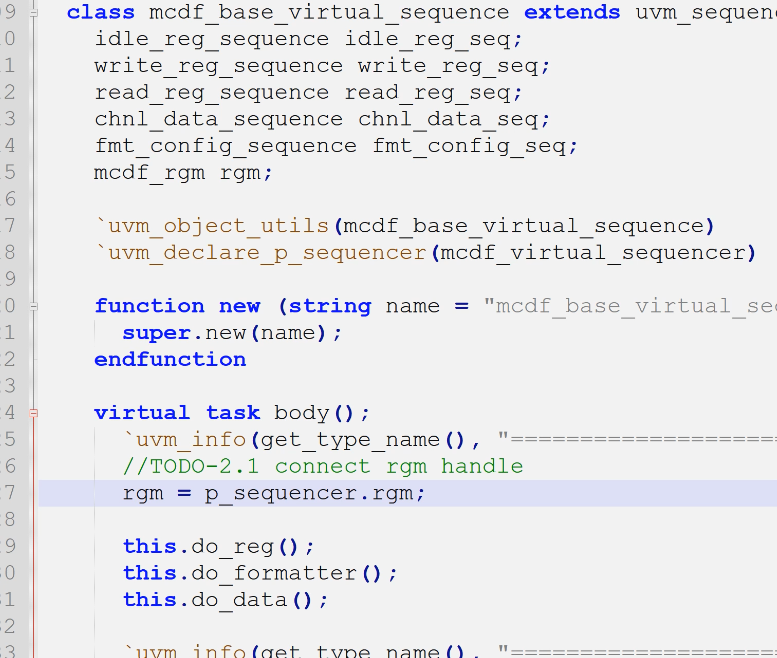
- vsqr需要rgm句柄(在env中连接获得)
- vseq需要rgm(从p_sequencer获取)
2.2 mcdf_data_consistence_basic_virtual_sequence改写为rgm实现寄存器读写

- 以前使用sequence
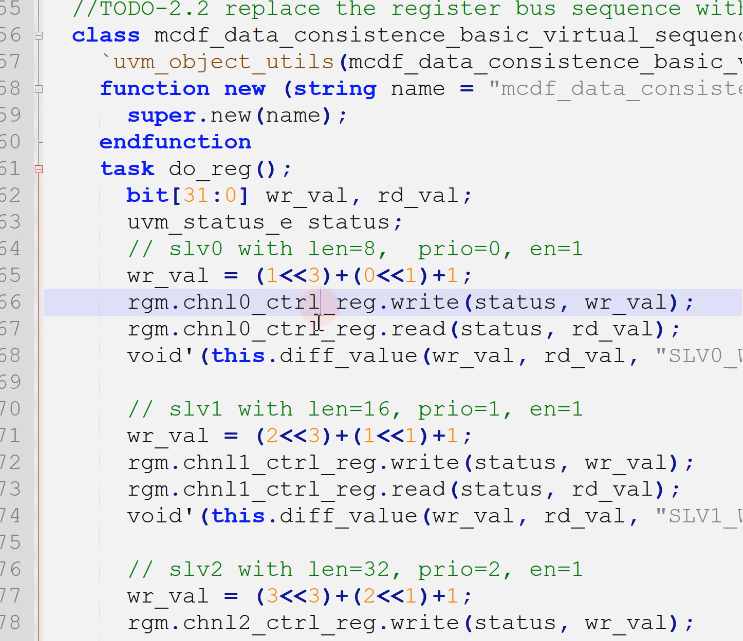
- 现在直接read/write
2.3 mcdf_full_random_virtual_sequence改写为rgm实现寄存器读写

- 2.3有点不一样,是为了让大家做更多的练习
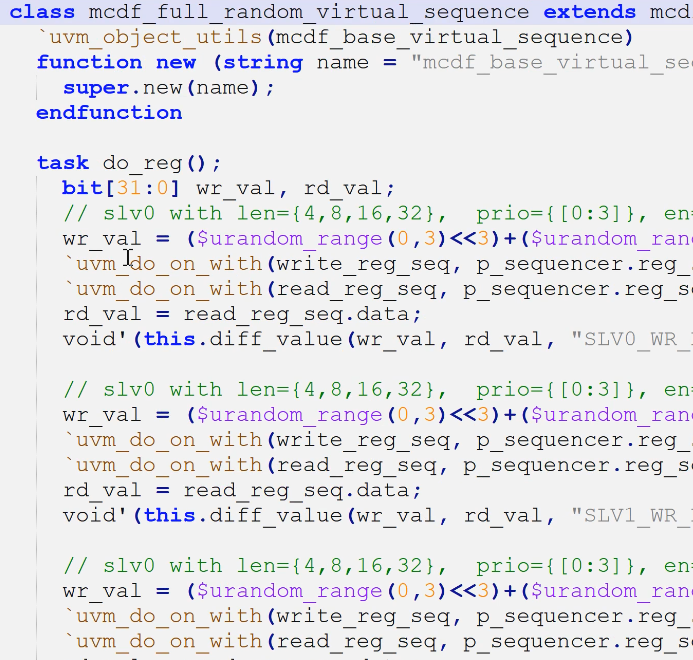
- 以前使用sequence

- 复位
- 设置期望值
- 更所有寄存器值
- 比较
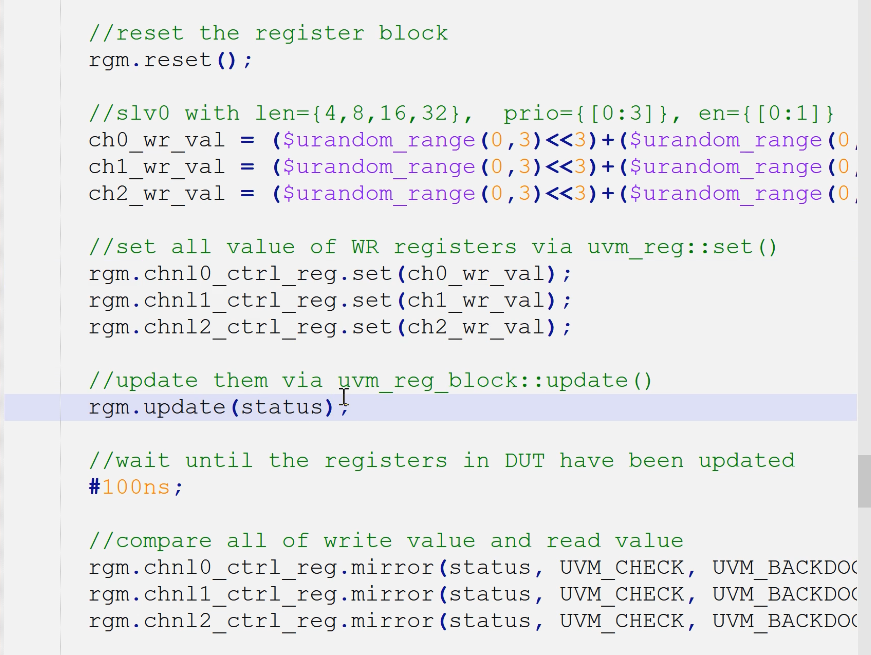
- 具体实现如上,注意检查是从后门直接检查
- 为什么只mirror控制寄存器,而不是状态寄存器?因为状态寄存器往往和rgm里面的不一样
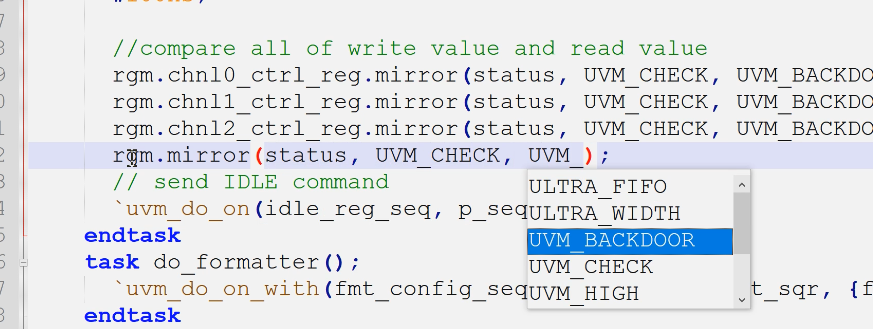
- 两种mirror方式:
- 第一种对寄存器mirror
- 第二种直接对block(这里是rgm)mirror
寄存器内建序列的应用

3.1 在自定义的新建sequence中使用rgm的几个内建seq完成检查

- 因为是对寄存器的检查,只需要实现do_reg()即可
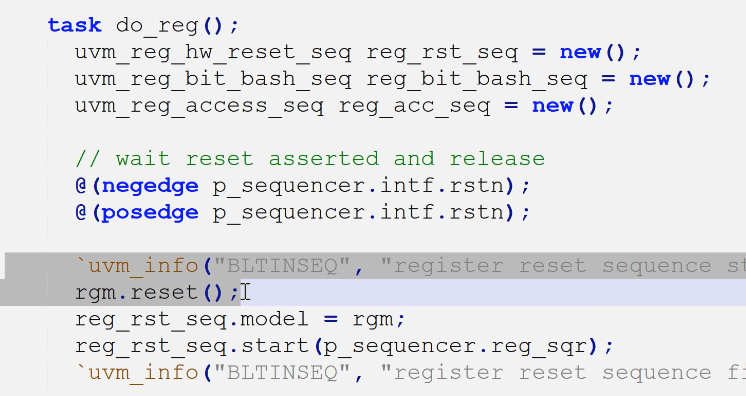
- 例化
- 复位
- rgm句柄传递
- 挂载到对应reg_sqr句柄上

- 第二次seq,同时在总线上对硬件进行了复位,也对rgm进行了复位

- 第三次seq
额外内容
有基础的同学可以在此基础上收集寄存器覆盖率
UVM新兵结束了!

全局实例
uvm_root
uvm_test_top
uvm_factory f = uvm_factory::get();
uvm_default_comparer
一些小函数
get_type_name():
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!