UVM实战 汇总与附录
时间:2022-11-21
第一章
主要介绍uvm发展史,验证内容
第二章
- autp predict验证平台组成
- 最简单的验证平台:my_driver与top_tb组成
第一章
1.2 学了UVM之后能做什么
- 使用sequence机制、factory机制、callback机制、寄存器模型(register model)等
- 验证基本常识
- 如何实现代码可重复性
机制索引
- phase机制(5.1)
- objection机制(5.2)
- sequence机制(2.4, 6)
- facory机制(8)
- file automation机制
- config_db机制
- callback机制(9)
特性检索
- TLM
- drain_time,撤销objection的延时(5.2.4)
- domain(5.3)
- register model
第二章
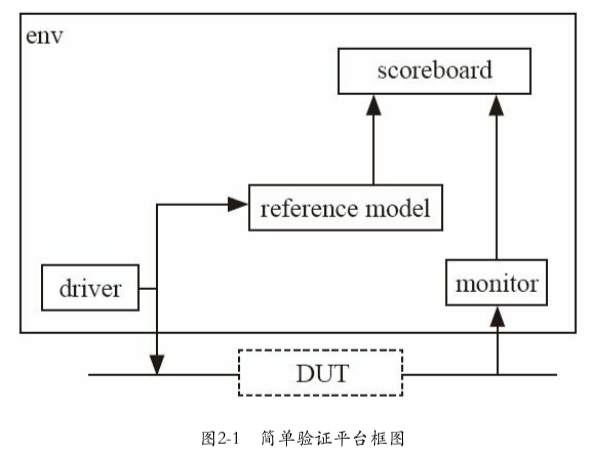
2.1 验证平台组成
验证用于找出DUT中的bug,这个过程通常是把DUT放入一个验证平台中来实现的
一个验证平台要实现如下基本功能:
- 激励的功能:driver
- 各种激励:正常激励、异常激励
- 判断是否符合预期:scoreboard/checker
- 收集DUT输出并传递给sb:monitor
- reference model
2.2 只有driver的验证平台
2.2.1 最简单的验证平台
1. driver是验证平台最基本的组件
如何搭建driver?
- UVM是一个库,在这个库中,几乎所有的东西都是使用类(class)来实现的,如:driver、 monitor、reference model、scoreboard等组成部分都是类
- 类有函数(function)和任务(task),通过这些函数和任务可以完成driver的输出激励功能
- 使用UVM的第一条原则是:验证平台中所有的组件应该派生自UVM中的类
2. 定义一个my_driver类
1 | |
new参数
- uvm_driver的类的new函数有两个参数(这两个参数是由uvm_component要求的),一个是string类型的name,一个是uvm_component类型的parent
- 每一个派生自uvm_component或其派生类的类在其new函数中要指明两个参数:name和parent
phase
- driver所做的事情几乎都在main_phase中完成
UVM由phase来管理验证平台的运行,这些phase统一以xxxx_phase来命名,且都有一个类型为uvm_phase、名字为phase的参数
可以简单地认为, 实现一个driver等于实现其main_phase
`uvm_info宏:与Verilog中display语句的功能类似,比display语句更加强大
- 三个参数,第一个参数是字符串,用于把打印的信息归类;第二个参数也是字符串,是具体需要打印的信息;第三个参数则是冗余级别
- 非常关键可设置为UVM_LOW,可有可无可设置为UVM_HIGH,介于两者之间是UVM_MEDIUM。UVM默认只显示UVM_MEDIUM或者UVM_LOW的信息,本书3.4.1节会讲
uvm_info打印内容
UVM_INFO my_driver.sv(20)@48500000:drv[my_driver]data is drived
- my_driver.sv(20):指明此条打印信息的来源,其中括号里的数字表示原始的uvm_info打印语句在my_driver.sv中的行号
- 48500000:表明此条信息的打印时间
- drv:这是driver在UVM树中的路径索引
- UVM采用树形结构,对于树中任何一个结点,都有一个与其相应的字符串类型的 路径索引。路径索引可以通过
get_full_name函数来获取,把下列代码加入任何UVM树的结点中就可以得知当前结点的路径索引:$display("the full name of current component is: %s", get_full_name());
- [my_driver]:方括号中显示的信息即调用uvm_info宏时传递的第一个参数
- data is drived:表明宏最终打印的信息
3. 实例化一对象
1 | |
`include uvm_macros.svh包含了众多的宏定义,只需要包含一 次import uvm_pkg::*;导入uvm_pkg库- new的时候第二个参数一般不为null
- 显示调用
main_phase $finish();结束仿真
2.2.2 加入factory机制
上节的实例化及main_phase的显式调用,只使用简单的SystemVerilog也可完成
本节介绍:自动创建一个类的实例并调用其中的函数(function)和任务(task)
1. 使用factory机制重写my_driver
1 | |
factory机制之宏
`uvm_component_utils这个宏所做的事情非常多,其中之一就是将my_driver登记在 UVM内部的一张表中
所有派生自uvm_component及其派生类的类都应该使用uvm_component_utils宏注册
这张表是factory功能实现的基础。只要在定义一个新的类时使用这个宏,就相当于把这个类注册到了这张表中。有关内容深入解释在后面
2. 使用factory机制重写top_tb
1 | |
运行top_tb后输出:
1 | |
并没有输出:”data is drived”,关于这个问题,牵涉UVM的objection机制
run_test("注册的类名")使用
run_test("注册的类名")代替my_driver实例化与显式调用
- run_test创建一个my_driver的实例,并且会自动调用my_driver的main_phase
2.2.3 加入objection机制
上一节只输出了“main_phase is called”,但是“data is drived”并没有输出,因为main_phase被杀死了
1. objection机制
UVM中通过objection机制来控制验证平台的关闭,在每个phase中,UVM会检查是否有objection被提起 (
raise_objection)。如果有,则等待这个objection被撤销(drop_objection)后停止仿真;如果没有,则马上结束当前phase
raise_objection和drop_objection总是成对出raise_objection语句必须在main_phase中第一个消耗仿真时间 [1]的语句之前所谓仿真时间,是指$time函数打印出的时间。与之相对的还有实际仿真中所消耗的CPU时间,通常说一个测试用例的运行时间 即指CPU 时间,为了与仿真时间相区分,本书统一把这种时间称为运行时间。
如
$display语句是不消耗仿真时间的,这些语句可 以放在raise_objection之前,但是类似@(posedge top.clk)等语句是要消耗仿真时间的。按照如下的方式使用raise_objection是无法
起到作用的
- 使用objection机制的my_driver
1 | |
2.2.4 加入virtual interrface
1. 绝对路径遇到的问题:
driver中等待时钟事件(@posedge top.clk)、给DUT中输入端口赋值(top.rx_dv<=1‘b1)都是使用绝对路径,绝对路径的使用大大减弱了验证平台的可移植性。一个最简单的例子就是假如clk信号的层次从top.clk变成了top.clk_inst.clk,那么就需要对driver中的相关代码做大量修改。因此,从根本上来说,应该尽量杜绝在验证平台中使用绝对路径
2. 解决方案①使用宏
使用`TOP代替上文中的top,但是如果clk_inst变了照样解决不了,还要改
3. 解决方法②使用接口
定义接口
1 | |
在top_tb中实例化DUT时,就可以直接使用接口
1 | |
4. 如何在driver(类)中使用接口
不能直接,这种方式只能在module模块中才能实现
1 | |
在类中应该使用虚接口virtual interface:
1 | |
替代后的全部my_driver代码如下,可见绝对路径已消除
1 | |
5. 如何链接top_tb的input_if与my_driver中的vif(config_db机制)
使用run_test进行实例化,从而无法直接引用my_driver实例
使用config_db机制
config_db机制:
config_db用来在端口间传递数据(端口级),分为set和get两步操作
uvm_config_db#(?)::set操作,可以简单地理解成是“寄信”uvm_config_db#(?)::get则相当于是“收信”
在top_tb中执行set操作:
1 | |
在my_driver中,执行get操作:
1 | |
build_phase
- 定义:与main_phase一样,build_phase也是UVM中内建的一个phase
- 执行顺序:当UVM启动后,会自动执行 build_phase,运行在new之后,main_phase之前
- 主要作用:主要通过config_db的set和get操作来传递一些数据, 以及实例化成员变量等
- 使用注意事项:需要在build_phase中调用
super.build_phase(phase),因为父类的build_phase中执行了一些必要的操作,这里必须显式调用并执行- 与main_phase不同:main_phase是任务,build_phase是函数不消耗仿真时间
`uvm_fatal宏
- 参数:两个与
`uvm_info前两个参数意义一样- 主要作用:表示验证平台出现了重大问题而无法继续下去,必须停止仿真并做相应的检查
- 与
`uvm_info不同:会调用$finish()结束仿真
config_db的参数
- config_db的set和get函数都有四个参数,且第三个参数必须完全一致
uvm_config_db::set
- 第二个参数表示的是路径索引(2.2.1节提到
`uvm_info中的路径索引)
- run_test创建的实例名为
uvm_test_top,无论传给run_test参数是什么创建的实例名都是uvm_test_top- 第四个参数表示要将哪个interface 通过config_db传递给my_driver
uvm_config_db::get
- 第四个参数表示把得到的interface传递给哪个my_driver的成员变量
参数化:
uvm_config_db#(virtual my_if)是一个参数化的类,其参数就是要寄信的类型- 如果要传递一个int类型:
uvm_config_db#(int)::set
2.3 为验证平台加入各个组件
2.2节的操作基于信号级,本节引入scoreboard、reference model、monitor这些组件是基于transaciton
2.3.1 加入transaction
transaction的概念:transaction就是用于模拟物理协议/以太网协议/…,一 笔transaction就是一个包
1. 一个简单的transaction定义
1 | |
uvm_sequence_itemmy_transaction的基类是uvm_sequence_item,uvm_sequence_item的祖先是
uvm_object
uvm_object_utils
- 不使用
uvm_component_utils而使用` uvm_object_utils的原因:
- transaction不同于driver等组件,具有生命周期,这种类一般派生自uvm_object或uvm_object的派生类
post_randomize
post_randomize是SystemVerilog中提供的一个函数,
当某个类的实例的randomize函数被调用后,post_randomize会紧随其后无条件地被调用
2. driver驱动transaction
1 | |
流程:
① 随机化:main_phase中执行transactin的randomize()
② 数据入列:main_phase执行数据入列函数,把transaction压入data_q
SystemVerlog提供的流操作符实现
IEEE Standard for SystemVerilog—Unified Hardware Design,Specification,and Verification Language 的11.4.14章
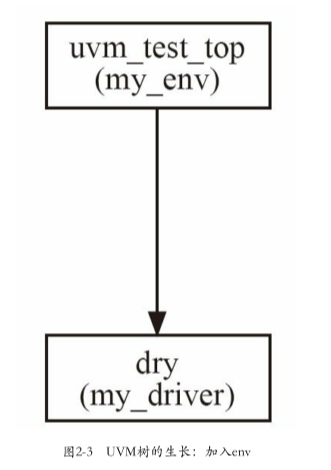
2.3.2 加入env
我们在哪对各种组件例化?
- (不可行)top_tb中使用run_test不行,因为run_test只能实例化一个实例
- (不可行)top_tb中直接new不行,这样run_test没意义了
- (正确的)引入一个容器类,在这个类里面例化各种组件,此时run_test的参数不再是my_driver而是容器类。uvm中使用继承自
uvm_env的子类,来表示这个容器类
1. 定义my_env
1 | |
类名::type_id::create
- factory机制带来的独特的实例化方式,只有factory注册过的类可以这种方式例化(代替new)
- 好处:后面可以用到factory中强大的重载功能
2. 树形结构——回顾my_driver参数2
1 | |
- name:实例名称
- parent:由于是在uvm_env例化,则my_driver的drv实例是my_env
- 建立了树形结构
3. build_phase顺序
build_phase的执行遵照从树根到树叶的顺序,当把整棵树的build_phase都执行完毕后,再执行后面的phase
因此,先执行my_env的build_phase,再执行my_driver的build_phase
4. 修改config_db
树根始终是run_test创建的uvm_test_top,这里uvm_test_top对象代表了一个my_env类
我们为啥要修改config_db?
答:我们加了一个env,你忘了吗
假如在my_env中实例化一个my_driver为my_drv:
1 | |
则在top_tb.sv中修改为:
1 | |
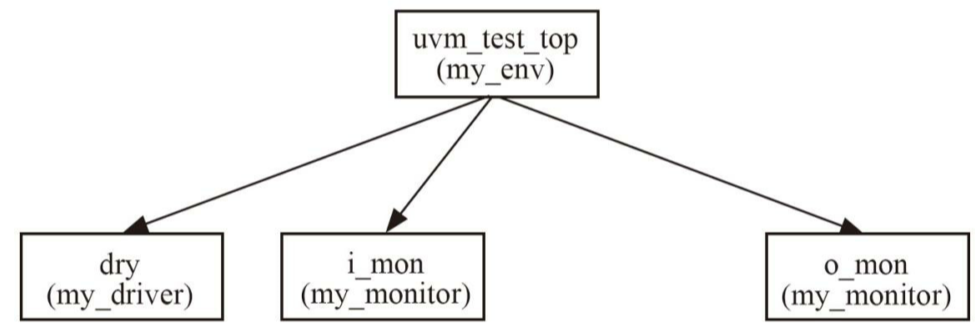
2.3.3 加入monitor
monitor作用:收集DUT行为
monitor内容:收集DUT端口数据,转换为transaction后交给后续组件(与driver相反)
driver内容:把transaction数据变为DUT端口级别,并驱动到DUT
1 | |
流程:
数据入列:main_phase执行数据入列函数,把transaction压入data_q
永不停歇
由于monitor需要时刻收集数据,永不停歇,所以在main_phase中使用
while(1)来实现对比monitor中的collect_one_pkt与driver中的drv_one_pkt:
- 两者代码非常相似
- 当收集完一个transaction后, 通过my_print函数将其打印出来
- my_printf在my_transaction中定义
transaction中定义的my_printf:
1 | |
env中对组件的例化:
1 | |
实例化两个monitor
- 一个用于检测DUT输入
- 一个用于检测DUT输出
为什么输入也monitor?
这个答案仁者见仁,智者见智。这里还是推荐使用monitor,原因是:
- 第一,在一个大型的项目中,driver根据某一协议发送数据,而 monitor根据这种协议收集数据,如果driver和monitor由不同人员实现,那么可以大大减少其中任何一方对协议理解的错误
- 第二,在后文将会看到,在实现代码重用时,使用monitor是非常有必要的
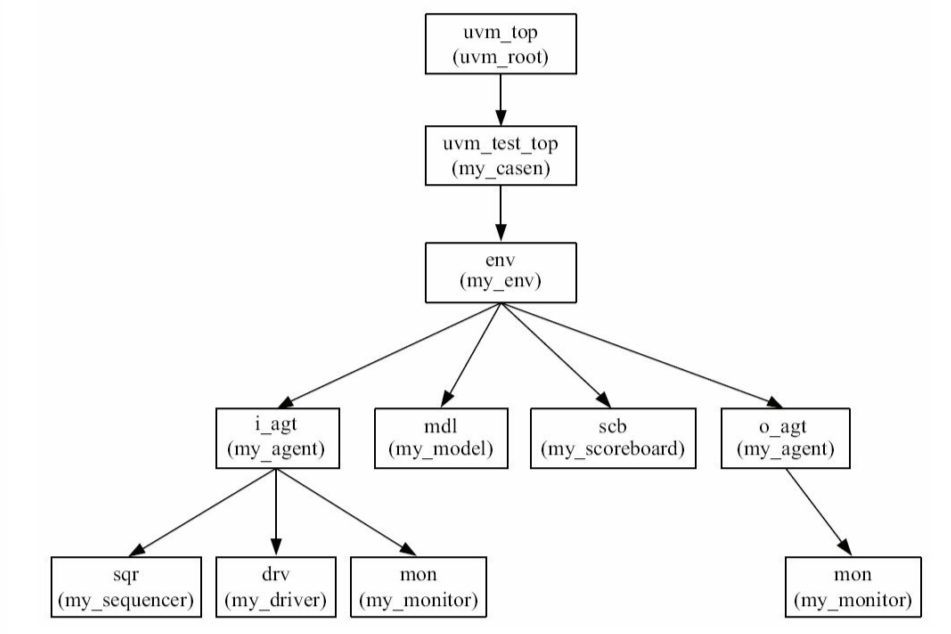
2. 现在的树结构
3. top_tb中config_db修改
使用config_db将input_if和output_if传递给两个monitor,从而完成端口连接
1 | |
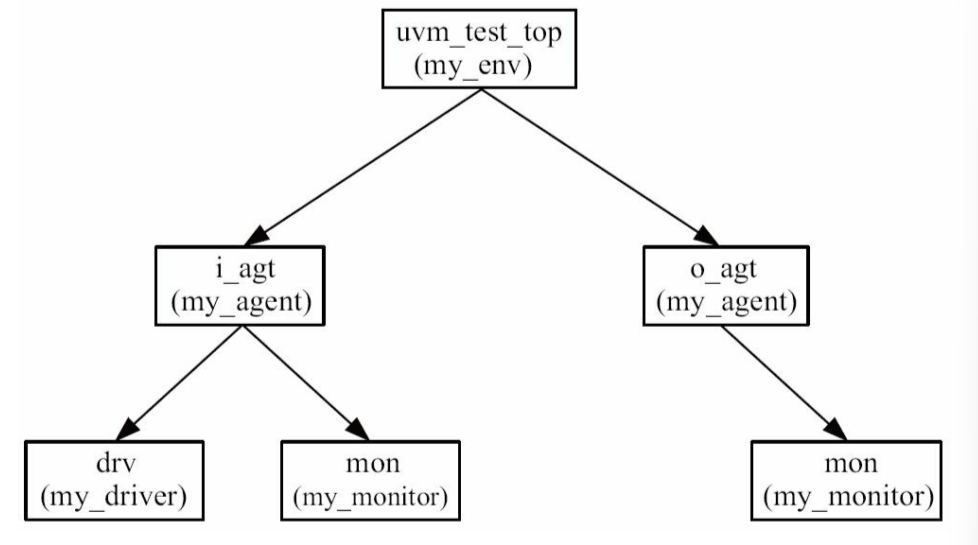
2.3.4 封装成agent
driver与monitor代码相似(本质处理同一种协议)
因此UVM常把二者封装在一起,成为agent
不同的agent就代表了不同的协议
1. my_agent定义
1 | |
uvm_agent
- 所有agent派生自此类
is_active
is_active是uvm_agent的一个成员变量,类型为uvm_active_passive_enum是一个枚举类型- 默认为
UVM_PASSIVE
uvm_active_passive_enum:
typedef enum bit { UVM_PASSIVE=0, UVM_ACTIVE=1 } uvm_active_passive_enum;UVM_PASSIVE:意味着输入端口,无需驱动任何信号,只做检查信号(即只要monitor不要driver)UVM_ACTIVE:意味着输出端口,需驱动任何信号
2. 修改env中对driver和monitor的实例化(同时配置is_active)
1 | |
3. 目前树结构
4. config_db修改端口连接
1 | |
(补充)5.用config_db也可以传is_active
背景:使用new实例化时,无法传递is_active。此时使用config_db机制可以传递is_active
注意!:UVM中约定俗成的还是在build_phase中完成实例化工作。因此,强烈建议仅在build_phase中完成实例化
1 | |
2.3.5 加入reference model
作用:完成与DUT相同功能
输出:被scoreboard接收
1. 定义my_model
1 | |
此reference model就是单纯使用transaction中的my_copy函数,复制一份从i_agt得到的transaction,再传递到后级的scoreboard
reference和其他组件一样,再env中被实例化
2. 目前的树结构
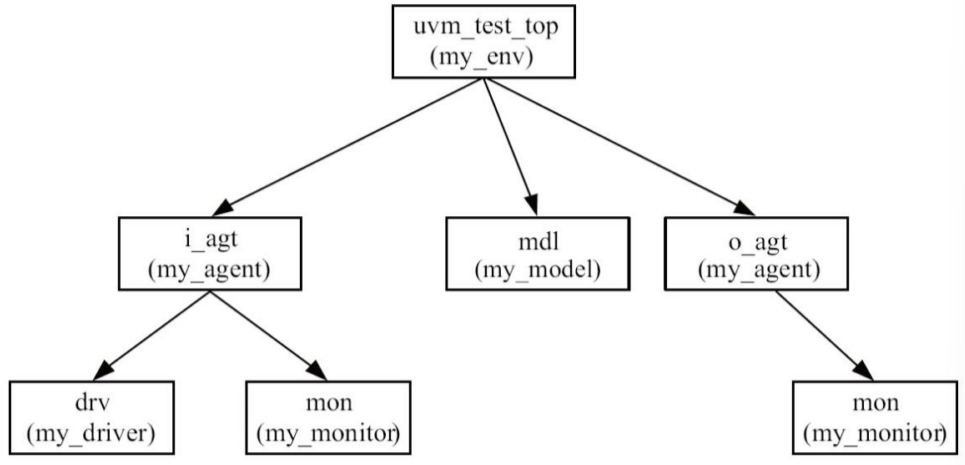
3. transaction的传输
目前传输:
i_agt -> ref -> scoreboard
i_agt -> dut(目前还没提到DUT模块在哪)
TLM(Transaction Level Modeling)
UVM一般使用TLM(Transaction Level Modeling)实现component之间的transaction通信
TLM有多种实现方式:
- 发送的其中一种方法使用
uvm_analysis_port- 接收的其中一种方法使用
uvm_blocking_get_port- 连接:在此基础上还需要再env上定义一个
uvm_tlm_analysis_fifo(一个fifo)将二者连在一起
uvm_analysis_port是TLM发送的实现方式的一种
- 定义:
uvm_analysis_port #(my_transaction) ap;- 参数化的类,参数为需要传递数据的类型(本节中为my_transaction)
- 通过调用内建函数
write完成发送- 非阻塞的
uvm_blocking_get_port是TLM接收的实现方式的一种
- 定义:
uvm_blocking_get_port #(my_transaction) port;- 参数化的类,参数为需要传递数据的类型(本节中为my_transaction)
- 通过调用内建函数
get完成接收
uvm_tlm_analysis_fifo是TLM连接的实现方式的一种
- 定义:
uvm_tlm_analysis_fifo #(my_transaction) agt_mdl_fifo;参数化的类,参数为需要传递数据的类型(本节中为my_transaction)
具体连接方法:
- 通过在connect_phase中,分别层次化调用monitor中的
uvm_analysis_port与model中的uvm_blocking_get_port两种port的内建函数connect完成发送与接收的连接- 连接时,需要调用
uvm_tlm_analysis_fifo中用于指示端口类型的成员变量:analysis_export与blocking_get_export为什么需要一个fifo?为啥不直接把monitor中的analysis_port和model中的blocking_get_port连接?
- analysis_port是非阻塞性质的,ap.write函数调用完成后马上返回,不会等待数据被接收。假如当write函数调用时, blocking_get_port正在忙于其他事情,而没有准备好接收新的数据时,此时被write函数写入的my_transaction就需要一个暂存的位置,这就是fifo
connect_phase
- 在build_phase之后马上执行
- 与build_phase的同级执行顺序不同,connect_phase从树叶到叶根(从小到大)
- 即:先执行driver和monitor的connect_phase,再执行agent的connect_phase,最后执行env的connect_phase
- 这样做有利于在实例化组件之后,进行层次化连接(见本节总结)
4. 使用uvm_analysis_port发送
my_monitor中:
- 定义一个
uvm_analysis_port类型的port - 在build_phase中实例化
- 当准备好一个transaction后,在main_phase中写入该port
- 写入port通过调用它的内建函数
write实现
- 写入port通过调用它的内建函数
如下:
1 | |
1 | |
5. 使用uvm_blocking_get_port接收
在model中:
- 定义一个
uvm_blocking_get_port类型的port - 在build_phase中实例化
- 不断读取i_agt从此port发送来的transaction
- 从port读取通过调用它的内建函数
get实现
- 从port读取通过调用它的内建函数
如下:
1 | |
1 | |
6. 使用uvm_tlm_analysis_fifo连接
在env中:
- 定义一个
uvm_tlm_analysis_fifo类型的fifo,一个 - 在build_phase中实例化
uvm_tlm_analysis_fifo- 注意:无需对env中的ap和port例化,他俩在monitor和model中已经被例化过了,这里只是做调用
- 在connect_phase中进行连接
- 发送这么连接到fifo:
i_agt.ap.connect(agt_mdl_fifo.analysis_export); - 接收这么连接到fifo:
model.port.connect(agt_mdl_fifo.blocking_get_export);agt_mdl_fifo:一个uvm_tlm_analysis_fifo
- 发送这么连接到fifo:
如下:
1 | |
1 | |
6. 总结一下
- 主要目的:model需要得到从i_agt来的transaction
方式:
- i_agt发送
- model接收
- env建立fifo并连接
实例化位置:
- i_monitor发送,因此
uvm_analysis_port在i_monitor中实例化 - i_agt实例化i_monitor,为了方便引用,因此在这里定义了一个指向i_monitor.ap的指针
- model中接收,因此
uvm_blocking_get_port在model中实例化 - env中实例化一个
uvm_tlm_analysis_fifo,并实例化各种组件,通过层次化引用到ap和port
- i_monitor发送,因此
- 重要执行顺序:
- env在build_phase中实例化agent
- agent在build_phase中实例化i_monitor
- agent在connect_phase中引用i_monitor.ap
- env在conncet_phase中引用i_monitor.ap和model.port,并进行连接
为什么是i_monitor发送?
- 因为driver是给到dut的,基于信号级;model是基于transaction,因此需要i_monitor转换后的
2.3.6 加入scoreboard
用于比较dut与ref的输出
1.scoreboard定义
1 | |
流程:
- 建立两个进程
- 进程1:接收
exp_port(ref)一个trans到队列expect_queue中- 进程2:
- 从
act_port(dut)接收一个trans为get_actual- expect_queue弹出一个trans到tmp_tran
- 调用get_actual.compare函数
数据:
scoreboard比较的数据:
- 来自reference model的port,通过端口exp_port获取
- 来自monitor的o_agt,通过端口act_port获取
- 你可能好奇为什么DUT是通过monitor的o_agt获取到scoreboard的?你个笨蛋!DUT是直接和o_agt连接的,把数据打包为事务级(driver相反,把事务级转为端口级)
端口与对应组件(2.3.5)
- scoreboard:act_port, exp_port
- monitor:o_agt
- reference model:port
2.实例化scoreboard
在my_env中实例化scoreboard
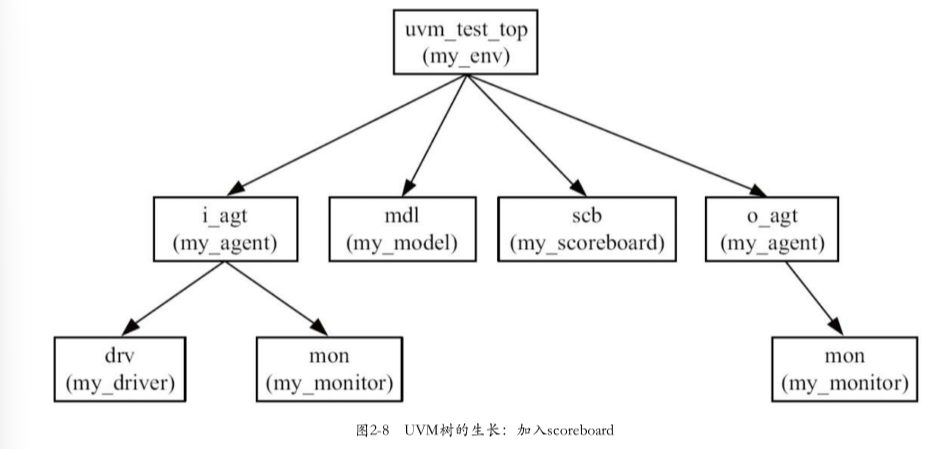
2.3.7 加入field_automation机制
用于在transaction中定义变量,从而可以用到uvm的transaction函数
1.my_transaction定义修改
1 | |
file_automation机制>
流程:
uvm_object_utils_begin与`uvm_object_utils_end划定file_automation定义的范围- 针对不同数据类型调用不同宏进行变量定义
uvm_field_intuvm_field_array_int经过以上步骤,可以直接调用定义了这些变量的类的方法:
copycomparepack_bytesunpack_bytes
2.my_model与scoreboard中直接调用file_automation带来的方法
1 | |
1 | |
3.引入file_automation的好处/driver与monitor的定义简化
好处:引入field_automation机制的另外一大好处是简化了driver和monitor。在2.3.1节及2.3.3节中,my_driver的drv_one_pkt任务和 my_monitor的collect_one_pkt任务代码很长,但是几乎都是一些重复性的代码
使用field_automation机制后,drv_one_pkt任务可以 简化为:
1 | |
pack流程:
- 直接调用
pack_bytes对比:
- pack_bytes将tr中所有的字段变成byte流放入data_q中
- 在2.3.1节中是手工地将所有字段放入data_q中的。 pack_bytes极大地减少了代码量
my_monitor的collect_one_pkt可以简化成:
1 | |
unpack流程,括号内表示解释:
- 定义一个接收data_q的动态数组,用作
unpack_bytes函数参数(unpack_bytes函数的输入参数必须是一个动态数组,所以需要先把收集到的、放在data_q中的数据复制到一个动态数组中,这里使用到的是data_array)- 由于tr在定义字段的时候使用到了一个动态数组字段,这里的需要指定大小后才能接收到tr的字段里,讲道理我感觉可以在main_phase就指定了(由于在tr中的pload是一个动态数组,所以需要在调用
unpack_bytes之前指定其大小,这样unpack_bytes函数才能正常工作)- 调用
unpack_bytes打包成的数据流顺序:
在把所有的字段变成byte流放入data_q中时,字段按照uvm_field系列宏书写的顺序排列
在上述代码中是先放入dmac,再依次放入smac、ether_type、pload、crc
2.4 UVM的终极大作:sequence机制
2.4.1 在验证平台中加入sequencer
功能:sequence机制用于产生激励
区别:前面的例子中激励都是在driver中产生的,但是在一个规范化的UVM验证平台中,driver只负责驱动transaction,不负责生产transaction
sequence机制两大组成部分:
- sequence
- sequencer
1.定义一个sequencer
1 | |
流程:
uvm_sequencer是一个参数化的类,参数为自定义的transaction- 派生自
uvm_sequencer- 使用
`uvm_component_utils进行注册与其他组件的关系:
- sequencer产生transaction
- driver接收transaction
2.有关派生自参数化的类
my_driver定义修正
之前定义的my_driver时都是直接从
uvm_driver派生的,即class my_driver extends uvm_driver;,这是种不常见的写法因为
uvm_driver也是一个参数化的类,应该在定义时指明driver要驱动的transaction类型,这么写是正确的class my_driver extends uvm_driver#(my_transaction);使用参数的好处
可以直接使用
uvm_driver中的某些预先定义好的成员变量如
uvm_driver中有成员变量req,它的类型就是传递给uvm_driver的参数,在这里就是my_transaction,可以直接使用req
参数定义后的my_driver中,带来的好处(req直接使用),注:这里依然是在driver中产生激励,下一节从driver中移除
1 | |
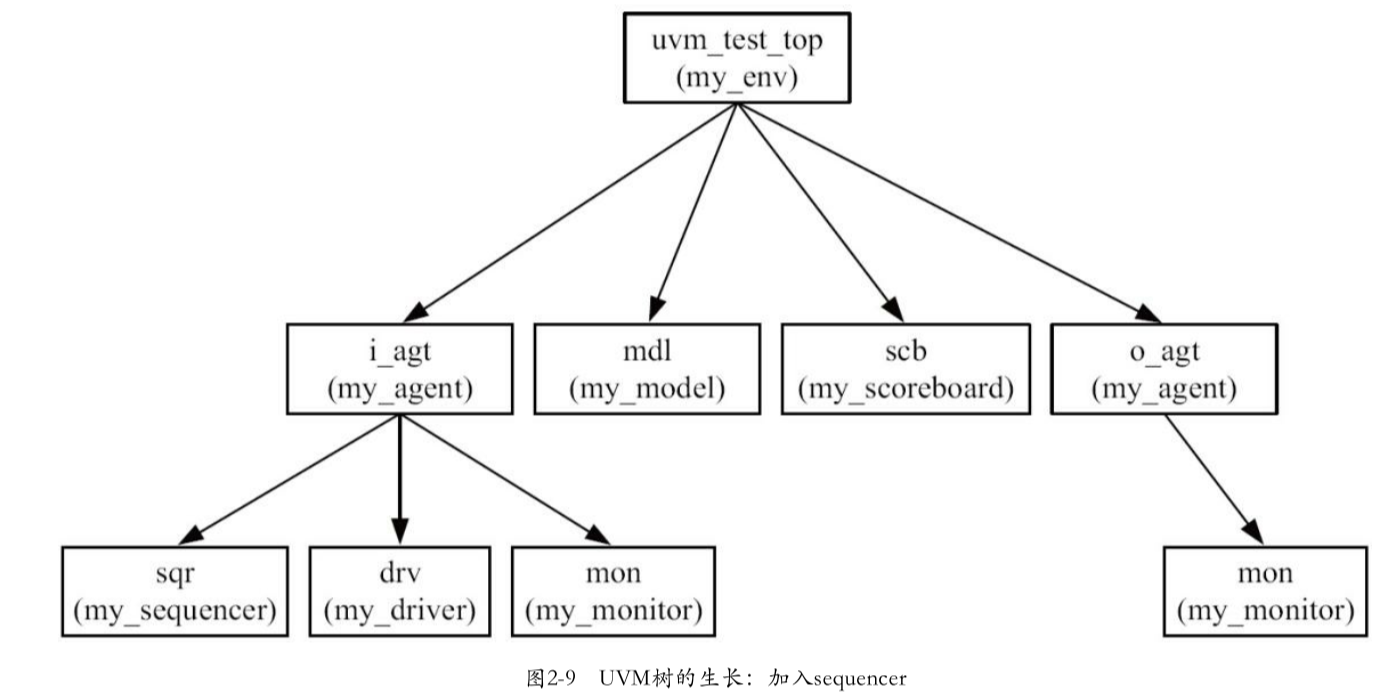
3.把sequencer放入到agent中
在完成sequencer的定义后,由于sequencer与driver的关系非常密切,因此要把其加入agent中
1 | |
4.加入sequencer后的UVM树结构图
2.4.2 sequence机制
sequence不属于验证平台的任何一部分,但是它与sequencer之间有密切的联系
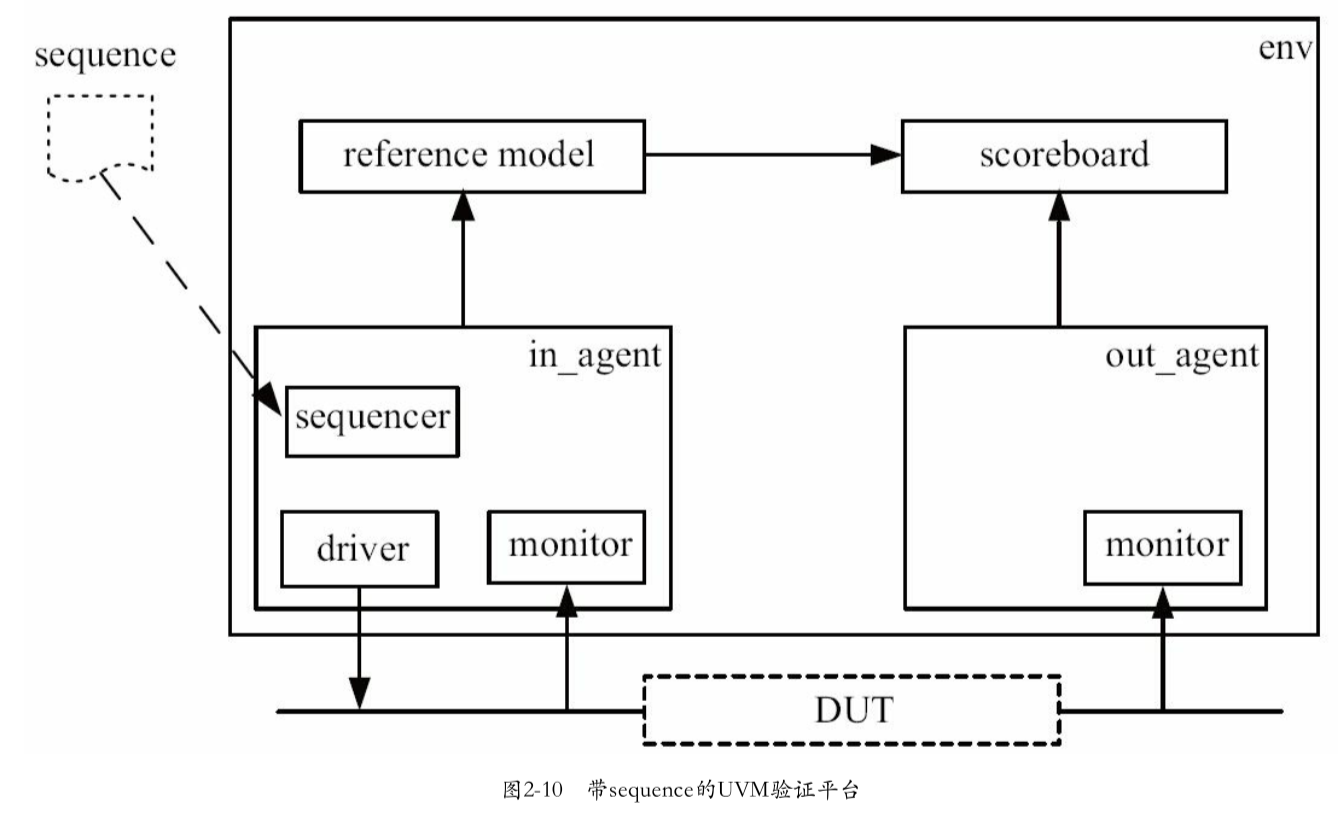
sequencer与sequence的关系
- 只有在 sequencer的帮助下,sequence产生出的transaction才能最终送给driver
- sequencer只有在sequence出现的情况下才能体现其价值
一个奇怪的比喻
- sequence就像是一个弹夹,里面的子弹是transaction
- 而sequencer是一把枪
- 弹夹只有放入枪中才有意义,枪只有在放入弹夹后才能发挥威力
sequencer与sequence的不同
- sequencer是一个
uvm_component- sequence是一个
uvm_object,与transaction一样具有生命周期,比my_transaction生命周期要长一些,其内的transaction全部 发送完毕后,它的生命周期也就结束了- sequence使用
`uvm_object_utils宏注册到factory中
1.一个sequence的定义
1 | |
定义流程:
- 派生自
uvm_sequence,参数为transaction类型- 定义
body,每一个sequence都有一个body任务,当一个sequence启动之后,会自动执行body中的代码
`uvm_do这是UVM中最常用的宏之一,作用:
- 将一个my_transaction的变量m_trans实例化
- 将m_trans随机化
- 将m_trans送给sequencer
如果不用
`uvm_do宏,也可以直接使用start_item与finish_item的方式产生transaction什么时候返回:等待driver的
item_done
2.sequence与sequencer的交互
交互:
- 一个sequence在向sequencer发送transaction前,要先向sequencer发送一个请求
- sequencer把这个请求放在一个仲裁队列中
sequencer的具体工作:
- 检测仲裁队列里是否有某个sequence发送transaction的请求
- 检测driver是否申请transaction
sequencer检测细节:
- 如果仲裁队列里有发送请求,但是driver没有申请trans:一直等待driver
- 如果仲裁队列中没有发送请求,但是driver向sequencer申请新的trans:sqr进入等待seq状态
- 如果仲裁队列中有发送请求,同时driver也在向sequencer申请新的trans:直接同意并移交
3.driver如何向sequencer申请transaction
- 在agent的
connect函数中,把drv中的变量seq_item_port与sqr中的seq_itemu_export连接,代码如下:
1 | |
- 连接好之后,就可以在driver中通过
get_next_item或try_next_item任务向sequencer申请新的trans,代码如下:
使用get_next_item
1 | |
使用try_next_item
1 | |
my_driver代码解析:
- 使用while(1),因为需要不断驱动
- 通过
get_next_item任务得到一个trans,或者try_next_item- 通过
item_done任务告知sequencer为什么会有一个
item_done?
- 一种握手机制
- 可以用来返回response(6.7.1)
- sqr内部保存的同一trans会不断发送,直到调用了
item_done相比于
get_next_item,try_next_item的行为更加接近真实driver的行为:当有数据时,就驱动数据,否则总线将一直处于空闲状 态
4.启动seq(在哪里实例化seq)
启动可以在不同组件的main_phase中(sqr/env),但在实际应用中, 使用最多的还是通过default_sequence的方式启动sequence见2.4.3节
在my_env中启动:
1 | |
在my_sqr中启动
1 | |
流程:
- 声明一个seq变量
- seq工厂机制实例化
- 调用seq的
start方法,入参为sqr指针(如果不指明则不知道匹配的sqr是谁)objection机制与结束仿真
在UVM中,objection一般伴随着sequence,通常只在sequence出现的地方才提起和撤销 objection。如前面所说,sequence是弹夹,当弹夹里面的子弹用光之后,可以结束仿真了
sqr与env中启动的不同:唯一区别是seq.start的参数变为了this
2.4.3 default_sequence的使用
sequence是在my_env的main_phase中手工启动的,作为示例使用这种方式足够了,但在实际应用中, 使用最多的是通过default_sequence的方式启动sequence
1.如何在default_sequence中启动seq
使用default_sequence的方式非常简单,只需要在某个component(如my_env)的build_phase中进行一行设置
在my_env中启动default_sequence的代码:
1 | |
config_db的使用:这是除了在top_tb中通过config_db设置virtual interface后再一次用到config_db参数一:
- 与在top_tb中不同的是,这里set函数的第 一个参数由null变成了this,而第二个代表路径的参数则去除了
uvm_test_top- 事实上,第二个参数是相对于第一个参数的相对路径,由于上述代码是在my_env中,而my_env本身已经是uvm_test_top了,且第一个参数被设置为了this,所以第二个参数中就不需要uvm_test_top
- 在top_tb中设置virtual interface时,由于top_tb不是一个类,无法使用this指针,所以设置set的第一个参数为null,第二个参数使用绝对路径uvm_test_top.xxx
参数二:在第二个路径参数中,出现了
main_phase。这是UVM在设置default_sequence时的要求。由于除了main_phase外,还存在其他任务phase,如configure_phase、reset_phase等,所以必须指定是哪个phase,从而使sequencer知道在哪个phase启动这个sequence参数三、参数四、参数类型:至于set的第三个和第四个参数,以及
uvm_config_db#(uvm_object_wrapper)中为什么是uvm_object_wrapper而不是uvm_sequence或者其他,则纯粹是由于UVM的规定,用户在使用时照做即可为什么这里只用设置一次
config_dbconfig_db通常都是成对出现的,如:在top_tb中通过set设置virtual interface,而在driver或者monitor中通过get函数得到virtual interface
那么在这里是否需要在sequencer中手工写一些get相关的代码呢?答案是否定的。UVM已经做好了这些,读者无需再把时间花在这上面
也可以在top_tb中启动default_sequence:
1 | |
形参设置:
第一个参数和第二个参数应该改变一下
也可以在其他的组件内,如my_agent的build_phase
1 | |
形参设置:
只需要正确地设置set的第二个参数即可(相对于my_env的)
3.default_sequence如何提起和撤销objection
在上一节手动启动sequence前后,分别提起和撤销objection,此时使用default_sequence自动启动,又如何提起和撤销objection呢?
方法:使用继承自uvm_sequence中的变量starting_phase,在sequence中使用starting_phase进行提起和撤销objection
sequence定义代码如下:
1 | |
sequencer在启动default_sequence时会自动做如下相关操作:
1 | |
UVM1.2貌似优化了starting_phase功能,使用方式有所改变
2.5 建造测试用例
2.5.1 加入base_test
1.前情提要
UVM使用的是一种树形结构,在本书的例子中:
- 最初这棵树的树根是
my_driver - 由于要放置其他component,树根变成 了
my_env - 但是在一个实际应用的UVM验证平台中,my_env并不是树根,通常来说,树根是一个基于
uvm_test派生的类
本节先讲述base_test,真正的测试用例都是基于base_test派生的一个类
1.定义base_test
1 | |
定义流程:
- 派生自
uvm_test- 使用
`uvm_component_utils宏注册到工厂中- 在
build_phase中实例化my_env- 在
build_phase中设置default_sequence,以后都在这里设置default_sequencebase_test一般做什么
- base_test中做的事情在根据不同的验证平台及不同的公司而不同,没有统一的答案
- 此例用到了report_phase,用于根据
UVM_ERROR数量打印不同信息,除此之外一些工具可以根据打印信息判断DUT是否通过了某个测试用例的检查- 设置整个验证平台的超时退出时间
- 通过config_db设置验 证平台中某些参数的值
report_phase
report_phase也是UVM内建的一个phase,它在main_phase结束之后执行
2.加入base_test后的UVM树
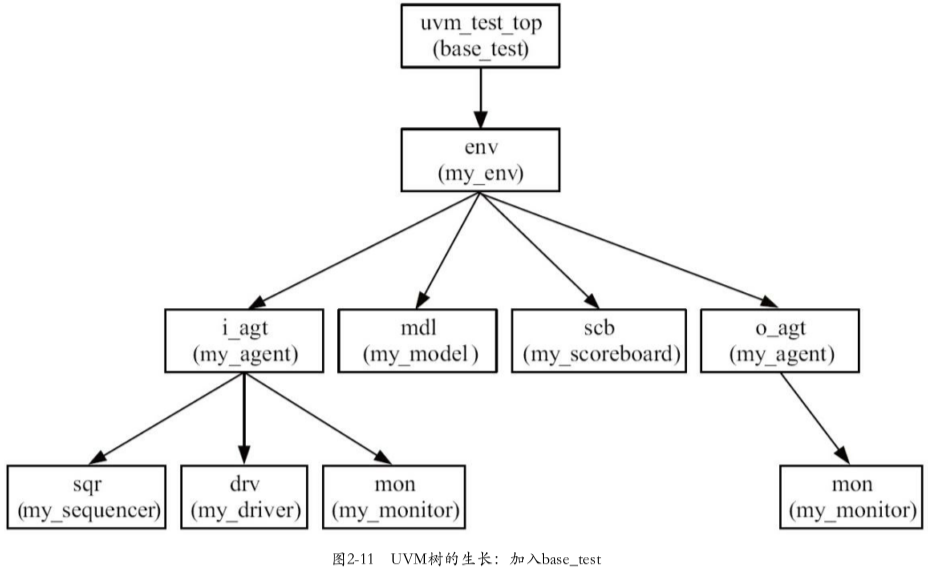
3.top_tb模块修改run_test的env为base_test
1 | |
2.5.2 UVM中测试用例的启动
测试用例=测试向量=pattern
1.如何启动两个(多个也行)不同的测试用例
不同测试用例需要修改default_sequence,从而需要多个base_test
方法1:修改run_test参数
- 启动my_case0,需要在top_tb中更改run_test的参数:
1 | |
- 启动my_case1,需要在top_tb中更改run_test的参数:
1 | |
需要不断编译!
当my_case0运行的时候需要修改代码,重新编译后才能运行;当my_case1运行时也需如此,这相当不方便
方法2:使用命令行
UVM提供对不加参数的run_test的支持
- 直接run_test
1 | |
在这种情况下,UVM会利用
UVM_TEST_NAME从命令行中寻找测试用例的名字,创建它的实例并运行
- 命令行运行时需要添加参数
1 | |
2.测试用例流程启动与验证平台执行流程总结
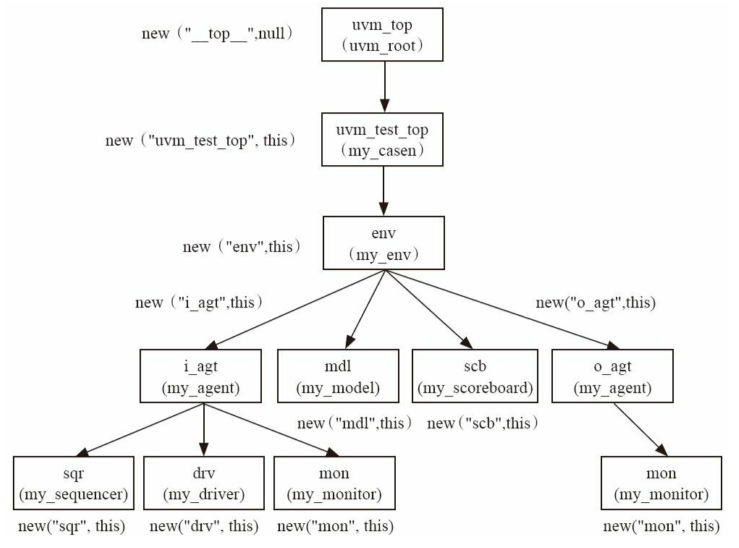
启动后UVM树的结构如图
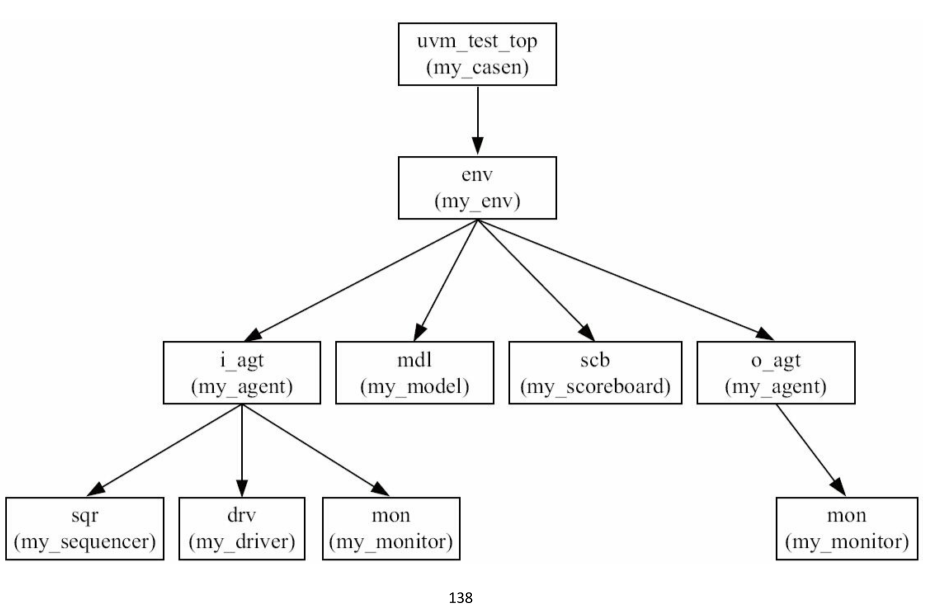
UVM树与上一节的不同:
把base_test替换为my_casen(说明有好几个测试用例)
3.测试用例定义细节
my_case0与case0_sequence:
1 | |
my_case1与case1_sequence:
1 | |
`uvm_do_with宏是
`uvm_do系列宏中的一个,用于在随机化时提供对某些字段的约束
2022-11-22
第三章UVM基础
3.1 uvm_object与uvm_component
3.1.1 uvm_component派生自uvm_object
- 要点一:
uvm_object是UVM中最基本的类,几乎所有类都继承自uvm_object - 要点二:
uvm_component派生自uvm_object - 要点三:
uvm_object派生出两个分支 - 要点四:UVM树的所有结点都是
uvm_component(下图左分支不可能出现在UVM树上)
uvm_component独立于uvm_object的两条特性:
- 能在new的时候指定parent参数来形成一种树形的组织结构
- 能phase的自动执行
UVM中常用类的继承关系
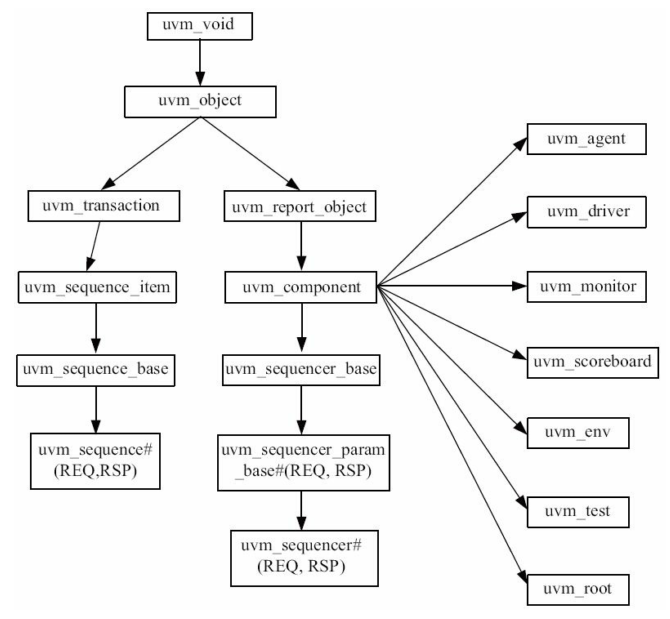
3.1.2 常用的uvm_object派生类
uvm_sequence_item:用于派生transaction,transaction就是封装了一定信息的一个类uvm_transaction:UVM中不能从uvm_transaction派生一个transaction,而要从uvm_sequence_item派生uvm_sequence:用于派生所有的sequence,sequence直接与sequencer打交道config:用于规范验证平台的行为方式,- 如规定driver在读取总线时 地址信号要持续几个时钟,片选信号从什么时候开始有效等
- 这里要注意config与config_db的区别。在上一章中已经见识了使用 config_db进行参数配置,这里的config其实指的是把所有的参数放在一个object中,如10.5节所示。然后通过config_db的方式设置给所有需要这些参数的component
uvm_reg_item、uvm_reg_map、uvm_mem、uvm_reg_field、uvm_reg、uvm_reg_file、uvm_reg_block等与寄存器相关的众多的类,用于register modeluvm_phase:用为控制uvm_component的行为方式,使得uvm_component平滑地在各个不同的 phase之间依次运转- 其他还有很多并不那么重要,这里不再一一列出
3.1.3 常用的uvm_component派生类
合集:
继承关系:
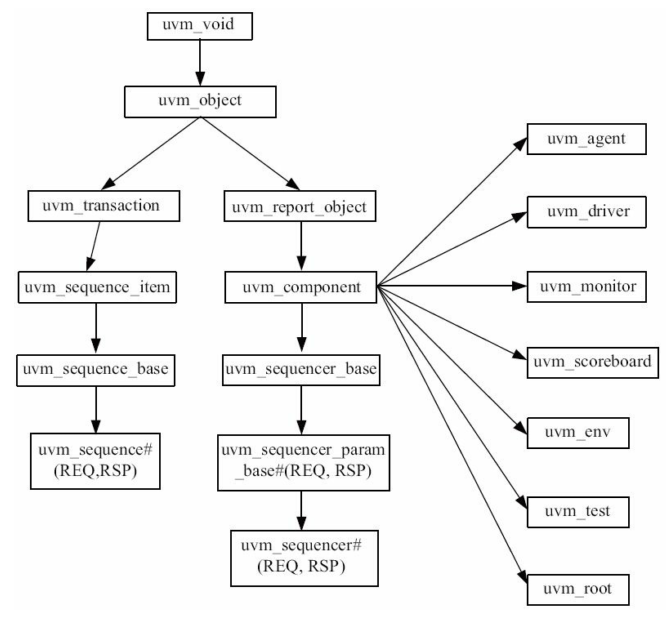
路径图:
3.4总结图
uvm_driver:派生driver
driver的功能主要就是向sequencer索要sequence_item(transaction),并将sequence_item里的信息驱动到DUT的端口上- driver完成了从transaction级别到DUT能够接受的端口级别信息的转换
- 与
uvm_component相比多的成员变量:
uvm_seq_item_pull_port #(REQ, RSP) seq_item_port;uvm_seq_item_pull_port #(REQ, RSP) seq_item_prod_if; // aliasuvm_analysis_port #(RSP) rsp_port;REQ req;RSP rsp;- 在函数/任务上,与
uvm_component相比没有做过多的扩展
uvm_monitor:派生monitor
monitor从DUT的pin上接收数据,并把接收到的数据转换成
transaction级的sequence_item,再把转换后的数据发送给scoreboard,供其比较与driver相反
- 与
uvm_component相比,uvm_monitor几乎没有做任何扩充- 几乎没有做任何扩展
- 理论上来说所有的monitor要从
uvm_monitor派生,但是实际上如果从uvm_component派生,也没有任何问题
uvm_sequencer:派生sequencer
- sequencer的功能就是组织管理
sequence,当driver要求数据时, 它就把sequence生成的sequence_item转发给driver- 与
uvm_component相比,uvm_sequencer做了相当多的扩展,在第六章介绍
uvm_scoreboard:派生scoreboard
- scoreboard的功能就是比较
reference model和monitor分别发送来的数据,根据比较结果判断DUT是否正确工作- 与
uvm_component相比,uvm_scoreboard几乎没有做任何扩充- 几乎没有做任何扩展
- 理论上来说所有的monitor要从
uvm_scoreboard派生,但是实际上如果从uvm_component派生,也没有任何问题reference model:
UVM中并没有针对reference model定义一个类,reference model都是直接派生自
uvm_componentreference model的作用就是模仿DUT
uvm_agent:派生agent
- 只是把driver和monitor封装在一起,根据参数值来决定是只实例化monitor还是要同时实例化driver和monitor
- 主要作用是重构性
- 与
uvm_component相比,uvm_agent的最大改动在引入了一个变量is_active
uvm_env:派生env
- env将验证平台上用到的固定不变的component都封装在一 起
uvm_env几乎没有做任何扩展- 加入寄存器模型,包括reg model与adapt,并进行相应连接,在
uvm_test中添加寄存器模型更常用
uvm_test:所有的测试用例要派生自uvm_test或其派生类,不同的测试用例之间差异很大,所以从uvm_test派生出来的类各不相同
- 任何一个派生出的测试用例中,都要实例化
env,只有这样,当测试用例在运行的时候,才能把数据正常地发给DUT,并正常接收DUT数据- uvm_test_top是一个
run_test("注册的类名")生成的注册类名的实例,实例名固定为uvm_test_topuvm_test几乎没有做任何扩展- 用法
- 例化env
- 控制打印信息
- 控制objection(5.1.7)
- 启动seq(2.5.2)
- 通过config_db设置seq(6.6)
- 加入寄存器模型,包括reg model与adapt,并进行相应连接(7.2.2)
- reg_predictor
base_test:
- print_topology(8.2.4 factory机制的调试)
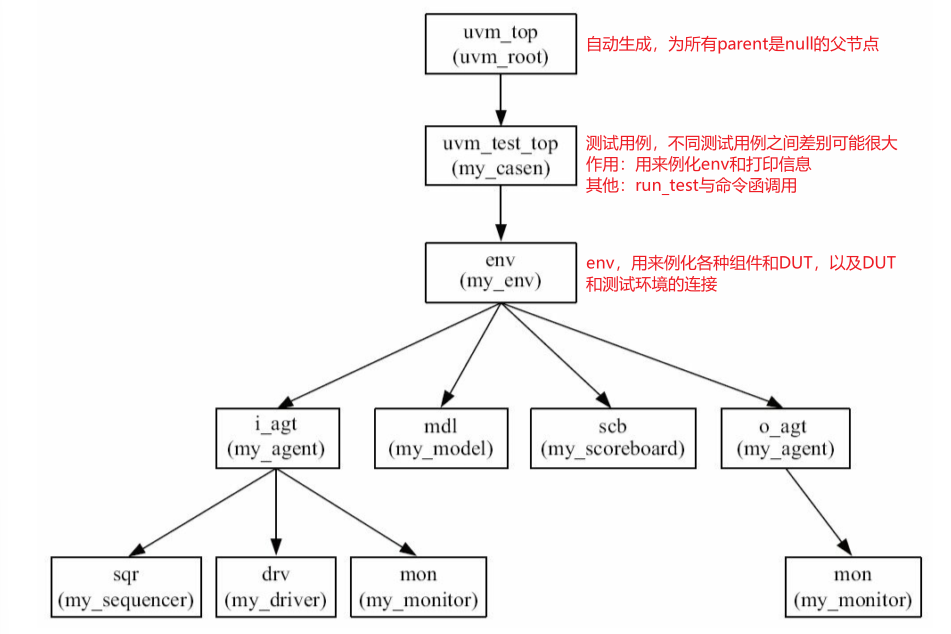
uvm_root
uvm_top是一个全局变量,它是uvm_root的一个实例(而且也是唯一的一个实例,设计模式中鼎鼎)- UVM中所有parent为null的component的父节点
uvm_top的名字是__top__,但是在显示路径的时候,并不会显示出这 个名字,而只显示从uvm_test_top开始的路径- UVM默认生成,你不用管
- 作用:为了确保整个验证平台中只有一棵树,所有节点都是uvm_top子节点
testbench模块
import uvm_pkg::*;和`include "uvm_macros.svh"和`include “自定义的各种uvm组件.sv”- 运行
run_test();,有关run_test();的内容参考2.5.2- 产生其他信号(clk,rstn)
- 用于例化DUT,virtual interface
- 将DUT与virtual interface直接连接
- 通过
config_db将virtual interface与uvm_test_top.env?中各个组件进行连接
其他扩展:
在哪控制objection?
- scoreboard或sequence中启动,详见5.2.3
- 存在virtual sequence在最顶层virtual sequence中启动,详见6.5.4
全局变量
factory
- 来源:8.2.2
- 作用:用于uvm_component外调用重载函数
3.1.4 uvm_object相关宏
uvm_object相关的factory宏有如下几个:
`uvm_object_utils:注册object到factory中`uvm_object_param_utils:注册参数化的object到factory中`uvm_object_utils_begin:对成员变量使用field_automation机制`uvm_object_param_utils_begin:参数化的对成员变量使用field_automation机制`uvm_object_utils_end:结束注册,与uvm_object_*_begin成对出现
3.1.5 uvm_component相关宏
uvm_component相关的factory宏有如下几个:
`uvm_component_utils:注册component到factory中`uvm_component_param_utils:注册参数化的component到factory中`uvm_component_utils_begin:对成员变量使用field_automation机制`uvm_component_param_utils_begin:参数化的对成员变量使用field_automation机制`uvm_object_utils_end:结束注册,与uvm_object_*_begin成对出现
在类似于my_transaction这种类中使用field_automation机制可以让人理解,可是在component中使用field_automation机制有必要吗?
uvm_component派生自uvm_object,可以直接使用object的compare、print等方法- 可以自动地使用config_db来得到某些变量的值。具体的可以参考3.5.3节的介绍
3.1.6 copy与clone,comp的一些限制
由于uvm_component是作为UVM树的结点存在的,使它失去了uvm_object的某些特征
1.无法使用clone方法
uvm_object的clone方法使用方式:
1 | |
上述
clone函数无法用于uvm_component中,因为一旦使用后,新clone出来的类,其parent参数无法指定
2.可以使用copy方法
clone=new+copy:
- 在使用copy前,目标实例必须已经使用new函数分配好了内存空间
- 使用clone函数时,目标实例可以只是一个空指针
uvm_component无法使用clone函数,但是可以使用copy函数。因为在调用copy之前,目标实例已经完成了实例化,其 parent参数已经指定了
3.禁止子节点同名
位于同一个父结点下的不同的component,在实例化时不能使用相同的名字
如下的方式中都使用名字a1是会出错的:
1 | |
3.1.7 uvm_component与uvm_object的二元结构
这本书在讲尬的…
3.2 UVM的树形结构
3.2.1 uvm_component中的parent参数
uvm_component在new的时候,需要指定一个类型为uvm_component的变量parent
1 | |
一般使用时,parent通常是this
为什么要有parent这个参数?直接
new(string name)不好吗
- 书中写了一堆废话。。
- 最主要是要解决如何找到所有UVM节点的问题,加入了parent句柄,在new之后分别在对象与嵌套对象中维护一个m_children数组,从而能够知道一共几个
- 我的补充:讲道理,这应该是语言的基本特性。。。讲的这么复杂多少有点。。。
3.2.2 UVM树真正的根:uvm_top
UVM中真正的树根是一个称为uvm_top的东西,完整的UVM树如下:
uvm_top哪来的?
uvm_top是一个全局变量,它是uvm_root的一个实例(而且也是唯一的一个实例,设计模式中鼎鼎)- UVM中所有parent为null的component的父节点
- UVM默认生成,你不用管
- 作用:为了确保整个验证平台中只有一棵树,所有节点都是uvm_top子节点
总结一下:
补充:
UVM顶层:uvm_test_top是一个自动生成的
uvm_root的实例,所有parent为null的组件的父节点(即上级),实例名为uvm_top测试用例:uvm_test_top是一个
run_test("注册的类名")生成的注册类名的实例,实例名固定为uvm_test_top用法
- 例化env
- 控制打印信息
- 控制objection(5.1.7)
- 启动seq(2.5.2)
如何得到uvm_top句柄?
1 | |
3.2.3 层次结构相关函数
extern virtual function uvm_component get_parent();函数,用于得到当前实例的parentextern function uvm_component get_child(string name);函数,用于得到childextern function void get_children(ref uvm_component children[$]);函数,用于得到所有childextern function int get_first_child(ref string name);:函数,得到第一个child的名字extern function int get_next_child(ref string name);:函数,得到下一个child的名字extern function int get_num_children();函数,返回当前component所拥有的child的数量
遍历所有child的方法1(使用get_children)
1 | |
遍历所有child的方法2(使用get_child、get_first_child、get_next_child)
1 | |
3.3 field automation机制
一般用于类的内部成员变量定义
3.3.1 field automation机制相关宏
uvm_field_*系列宏:
1 | |
枚举类型示例(它有三个参数,所以单独拿出来说下):
2
3
4
5typedef enum {TB_TRUE, TB_FALSE} tb_bool_e;
…
tb_bool_e tb_flag;
…
`uvm_field_enum(tb_bool_e, tb_flag, UVM_ALL_ON)基本和数组/队列的不同
- 多了
*_real和*_event*_enum多了一个参数联合数组是SystemVerilog中定义的一种非常有用的数据类型,在验证平台中经常使用
在与联合数组有关的uvm_field系列宏中, 出现的第一个类型是存储数据类型,第二个类型是索引类型,如
uvm_field_aa_int_string中的_int_string用于声明那些存储的数据是int,而其索引是string类型的联合数组
3.3.2 field automation机制常用功能
field automation功能非常强大
extern virtual function uvm_object clone();完全复制实例,不用提前实例化,参考3.1.6extern function void copy(uvm_object rhs);复制实例,把A实例复制到B实例中,使用B.copy(A)。使用此函数前,B实例必须已经使用new函数分配了内存空间extern function bit compare(uvm_object rhs, uvm_comparer comparer=null);比较实例,比较A与B使用A.compare(B),一致返回1,否则0extern function int pack_bytes(ref byte unsigned bytestream[], input uvm_packer packer=null);用于将所有字段打包为byte流,参考第二章extern function int unpack_bytes(ref byte unsigned bytestream[], input uvm_packer packer=null);用于把byte流恢复到某个类的实例中extern function int pack(ref bit bitstream[], input uvm_packer packer=null);与pack_bytes类似extern function int unpack(ref bit bitstream[], input uvm_packer packer=null);与unpack_bytes类似extern function int pack_ints(ref int unsigned intstream[], input uvm_packer packer=null);用于恢复一个int流print用于打印所有字段
除此之外,field automation提供自动得到使用config_db::set设置的参数的功能,这点请参照3.5.3节
3.3.3 field automation机制中的标志位(flag)
flag用于field automation定义变量的功能
1 | |
UVM_ALL_ON的值是'b000000101010101,表示打开该变量的copy、compare、print、record、pack功能UVM_ALL_ON|UVM_NOPACK的结果是'b000001101010101,这样UVM在执行pack操作时,首先检查bit9,发现其为1,直接忽略bit8所代表的UVM_PACK
3.3.4 field automation中宏与if的结合
这本书中又讲了一个让人摸不着头脑的例子
简单来说,就是field_automation可以这么用:
1 | |
使用if来决定field_automation:
1 | |
3.4 UVM中打印信息的控制
一般在测试用例中设置,测试用例主要做打印信息的控制与仿真结束的控制(断点/rasie/error等待)以及default_sequence,env主要做组件例化和uvm_port连接
3.4.1 打印信息冗余度(uvm_verbosity)
UVM通过冗余度级别的设置提高了仿真日志的可读性
- 在打印信息之前,UVM会比较要显示信息的冗余度级别与默认的冗余度阈值,如果小于等于阈值显示,否不显示
- 默认的冗余度阈值是
UVM_MEDIUM,所有低于等于UVM_MEDIUM(如UVM_LOW)的信息都会被打印出来
对不同的component设置不同的冗余度阈值非常有用。在芯片级别验证时,重用了不同模块(block)的env。由于个人习惯的不同,每个人对信息冗余度的容忍度也不同,有些人把所有信息设置为UVM_MEDIUM,也有另外一些人喜欢把所有的信息都设置为UVM_HIGH。通过设置不同env的冗余度级别,可以更好地控制整个芯片验证环境输出信息的质量。
1.以组件为单位的函数
get_report_verbosity_level得到某个component的冗余度阈值:
2
3virtual function void connect_phase(uvm_phase phase);
$display("env.i_agt.drv's verbosity level is %0d", env.i_agt.drv.get_report_verbosity_level ());
endfunction返回值:
uvm_verbosity
2
3
4
5
6
7
8typedef enum {
UVM_NONE = 0,
UVM_LOW = 100,
UVM_MEDIUM = 200,
UVM_HIGH = 300,
UVM_FULL = 400,
UVM_DEBUG = 500
} uvm_verbosity;
set_report_verbosity_level设置某个特定component的默认冗余度阈值,使用代码如下
2
3
4virtual function void connect_phase(uvm_phase phase);
env.i_agt.drv.set_report_verbosity_level(UVM_HIGH);
...
endfunction
set_report_verbosity_level调用phase:
- 需要牵扯到层次引用,所以需要在
connect_phase及以后的phase才能调用这个函数- 如果不牵扯到任何层次引用,可以在
connect_phase之前调用
set_report_verbosity_level只对某个特定的component起作用
set_report_verbosity_level_hier递归设置某component及其子节点的默认冗余度阈值,使用代码如下:
env.i_agt.set_report_verbosity_level_hier(UVM_HIGH);
2.组件内以ID为单位的函数
set_report_id_verbosity函数来区分不同的ID的冗余度阈值,使用示例:
2
3
4
5
6//某组件中
`uvm_info("ID1", "ID1 INFO", UVM_HIGH)
`uvm_info("ID2", "ID2 INFO", UVM_HIGH)
//env中
env.i_agt.drv.set_report_id_verbosity("ID1", UVM_HIGH);
//经过上述设置后“ID1INFO”会显示,但是“ID2INFO”不会显示
set_report_id_verbosity_hier递归设置某component及其子节点的某ID的默认冗余度阈值,使用代码如下:
env.i_agt.set_report_id_verbosity_hier("ID1", UVM_HIGH);
3.在命令行中设置
UVM支持在命令行中设置冗余度阈值:
2
3><sim command> +UVM_VERBOSITY=UVM_HIGH
>或者:
><sim command> +UVM_VERBOSITY=HIGH
- 这两个命令行参数是等价的,即可以把冗余度级别的前缀
UVM_省略- 上述的命令行参数会把整个验证平台的冗余度阈值设置为UVM_HIGH。相当于是在base_test中调用
set_report_verbosity_level_hier函数,把base_test及以下所有component的冗余度级别设置为UVM_HIGH
3.4.2 重载打印信息的严重性
UVM默认有四种信息严重性:UVM_INFO、UVM_WARNING、UVM_ERROR、 UVM_FATAL
1.重载打印信息的严重性
重载是深入到UVM骨子里的一个特性
这四种严重性可以互相重载
set_report_severity_override重载严重性
2
3
4//如果要把driver中所有的`UVM_WARNING显示为`UVM_ERROR,可以使用如下的函数
virtual function void connect_phase(uvm_phase phase);
env.i_agt.drv.set_report_severity_override(UVM_WARNING, UVM_ERROR); //env.i_agt.drv.set_report_severity_id_override(UVM_WARNING, "my_driver", UVM_ERROR);
endfunction不提供递归重载,与设置冗余度不同
严重性重载用的较少,一般的只会对某个component内使用,不会递归的使用
针对某个component的特定ID重载严重性:
env.i_agt.drv.set_report_severity_id_override(UVM_WARNING, "my_driver", UVM_ERROR);命令行中实现重载严重性:
2
3<sim command> +uvm_set_severity=<comp>,<id>,<current severity>,<new severity>
# 如果要把driver中所有的`UVM_WARNING显示为`UVM_ERROR,可以使用如下的函数(替代set_report_severity_override中的示例)
><sim command> +uvm_set_severity="uvm_test_top.env.i_agt.drv,my_driver,UVM_WARNING,UVM_ERROR"若要设置所有的ID,可以在id处使用
_ALL_:
<sim command> +uvm_set_severity="uvm_test_top.env.i_agt.drv,_ALL_,UVM_WARNING,UVM_ERROR"
3.4.3 严重性与结束仿真
UVM_FATAL出现时,表示出现了致命错误,仿真会马上停止
在end_of_elaboration_phase及其前的phase中,如果出现了一个或多个UVM_ERROR,那么UVM就认为出现了致命错误,会调用uvm_fatal结束仿真(5.1.6节提到),其他情况UVM_ERROR默认不会结束(最后一句不会结束我瞎猜的)
1.设置UVM_ERROR退出阈值
UVM_ERROR达到一定数量时也可以结束仿真
- 这个功能非常有用。对于某个测试用例,如果出现了大量的
UVM_ERROR,根据这些错误已经可以确定bug所在了,再继续仿真下去意义已经不大,此时就可以结束仿真,而不必等到所有的objection被撤销
set_report_max_quit_count设置UVM_ERROR退出阈值,使用函数示例
2
3
4
5function void base_test::build_phase(uvm_phase phase);
super.build_phase(phase);
env = my_env::type_id::create("env", this);
set_report_max_quit_count(5);
endfunction
get_max_quit_count查询当前的UVM_ERROR退出阈值,如果返回值为0则表示无论出现多少个UVM_ERROR都不会退出仿真在命令行中设置退出阈值:
+UVM_MAX_QUIT_COUNT=6,NO第一个参数6表示退出阈值,而第二个参数NO表示此值是不可以被后面的设置语句重载,其值还可以是YES
2.设置其他严重性退出
set_report_severity_action把其他严重性加入计数目标,下面的代码把UVM_WARNING加入计数目标:
2
3
4
5virtual function void connect_phase(uvm_phase phase);
…
set_report_max_quit_count(5);
env.i_agt.drv.set_report_severity_action(UVM_WARNING, UVM_DISPLAY|UVM_COUNT);
endfunction
set_report_severity_action:递归设置
env.i_agt.set_report_severity_action_hier(UVM_WARNING, UVM_DISPLAY| UVM_COUNT);
3.针对ID计数退出
除了针对严重性进行计数外,还可以对某个特定的ID进行计数
set_report_id_action:下面代码把ID为my_drv的所有信息加入计数退出
env.i_agt.drv.set_report_id_action("my_drv", UVM_DISPLAY| UVM_COUNT)
set_report_id_action_hier递归设置
env.i_agt.set_report_id_action_hier("my_drv", UVM_DISPLAY| UVM_COUNT);
4.联合ID与严重性计数退出
除了分别对严重性和ID进行设置外,UVM还支持把它们联合起来进行设置
2>set_report_severity_id_action
env.i_agt.drv.set_report_severity_id_action(UVM_WARNING, "my_driver", UVM_DISPLAY| UVM_COUNT);
set_report_severity_id_action_hier:递归形式
env.i_agt.set_report_severity_id_action_hier(UVM_WARNING, "my_driver", UVM_DISPLAY| UVM_COUNT);命令行中设置:
2
3
4
5<sim command> +uvm_set_action=<comp>,<id>,<severity>,<action>
#如
<sim command> +uvm_set_action="uvm_test_top.env.i_agt.drv,my_driver,UVM_NG,UVM_DISPLAY|UVM_COUNT"
#针对所有ID时,用_ALL_代替ID
<sim command> +uvm_set_action="uvm_test_top.env.i_agt.drv,_ALL_,UVM_WARNING,UVM_DISPLAY|UVM_COUNT"
3.4.5 UVM的断点功能
断点功能需要从仿真器的角度进行设置,不同仿真器的设置方式不同。为了消除这些设置方式的不同,UVM支持内建的断点功能,当执行到断点时,自动停止仿真,进入交互模式
1.具体实现
- 把3.4.4节介绍的函数中
UVM_COUNT替换为UVM_STOP就可以实现断点功能,函数目录:
1 | |
- 命令行中也可以设置断点:
1 | |
2.使用示例
使用set_report_severity_action函数,当env.i_agt.drv中出现UVM_WARNING时,立即停止仿真,进入交互模式
1 | |
3.4.6 将输出信息导入文件中
各个仿真器提供将显示在标准输出的信息同时输出到一个日志文件中的功能,但是这个日志文件混杂了所有的UVM_INFO、UVM_WARNING、UVM_ERROR及UVM_FATAL
UVM提供将特定信息输出到特定日志文件的功能
1 | |
代码总结
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28//严重性
env.i_agt.drv.set_report_severity_file(UVM_INFO, info_log);
env.i_agt.drv.set_report_severity_file(UVM_WARNING, warning_log);
env.i_agt.drv.set_report_severity_file(UVM_ERROR, error_log);
env.i_agt.drv.set_report_severity_file(UVM_FATAL, fatal_log);
env.i_agt.drv.set_report_severity_action(UVM_INFO, UVM_DISPLAY | UVM_LOG);
env.i_agt.drv.set_report_severity_action(UVM_WARNING, UVM_DISPLAY | UVM_LOG);
env.i_agt.drv.set_report_severity_action(UVM_ERROR, UVM_DISPLAY | UVM_COUNT | UVM_LOG);
env.i_agt.drv.set_report_severity_action(UVM_FATAL, UVM_DISPLAY | UVM_EXIT | UVM_LOG);
//严重性递归
env.i_agt.set_report_severity_file_hier(UVM_INFO, info_log);
env.i_agt.set_report_severity_file_hier(UVM_WARNING, warning_log); env.i_agt.set_report_severity_file_hier(UVM_ERROR, error_log); env.i_agt.set_report_severity_file_hier(UVM_FATAL, fatal_log);
env.i_agt.set_report_severity_action_hier(UVM_INFO, UVM_DISPLAY| UVM_LOG); env.i_agt.set_report_severity_action_hier(UVM_WARNING, UVM_DISPLAY| UVM_LOG); env.i_agt.set_report_severity_action_hier(UVM_ERROR, UVM_DISPLAY| UVM_COUNT |UVM_LOG);
env.i_agt.set_report_severity_action_hier(UVM_FATAL, UVM_DISPLAY| UVM_EXIT | UVM_LOG);
//id
env.i_agt.set_report_id_file_hier("my_driver", driver_log); env.i_agt.set_report_id_file_hier("my_drv", drv_log); env.i_agt.set_report_id_action_hier("my_driver", UVM_DISPLAY| UVM_LOG);
env.i_agt.set_report_id_action_hier("my_drv", UVM_DISPLAY| UVM_LOG);
//id递归
env.i_agt.set_report_severity_id_file_hier(UVM_WARNING, "my_driver", driver_log); env.i_agt.set_report_severity_id_file_hier(UVM_INFO, "my_drv", drv_log); env.i_agt.set_report_id_action_hier("my_driver", UVM_DISPLAY| UVM_LOG);
env.i_agt.set_report_id_action_hier("my_drv", UVM_DISPLAY| UVM_LOG);
//严重性与id组合
env.i_agt.drv.set_report_severity_id_file(UVM_WARNING, "my_driver", driver_log);
env.i_agt.drv.set_report_severity_id_file(UVM_INFO, "my_drv", drv_log);
env.i_agt.drv.set_report_id_action("my_driver", UVM_DISPLAY| UVM_LOG);
env.i_agt.drv.set_report_id_action("my_drv", UVM_DISPLAY| UVM_LOG);
//严重性与id组合递归
env.i_agt.set_report_severity_id_file_hier(UVM_WARNING, "my_driver", driver_log); env.i_agt.set_report_severity_id_file_hier(UVM_INFO, "my_drv", drv_log); env.i_agt.set_report_id_action_hier("my_driver", UVM_DISPLAY| UVM_LOG);
env.i_agt.set_report_id_action_hier("my_drv", UVM_DISPLAY| UVM_LOG);
3.4.7 控制打印行为
UVM中的打印信息的行为uvm_action_type:
1 | |
多行为可叠加(类似field automation中的标志位):
1 | |
默认严重级对应的行为:
1 | |
3.5 config_db机制
一般在build_phase中使用
3.5.1 UVM中的路径
- 使用
get_full_name()函数得到component路径 - 使用
comp::get()得到某componet的句柄
1.路径分析
UVM中的路径图(new函数而不是factory中的create是为了方便)
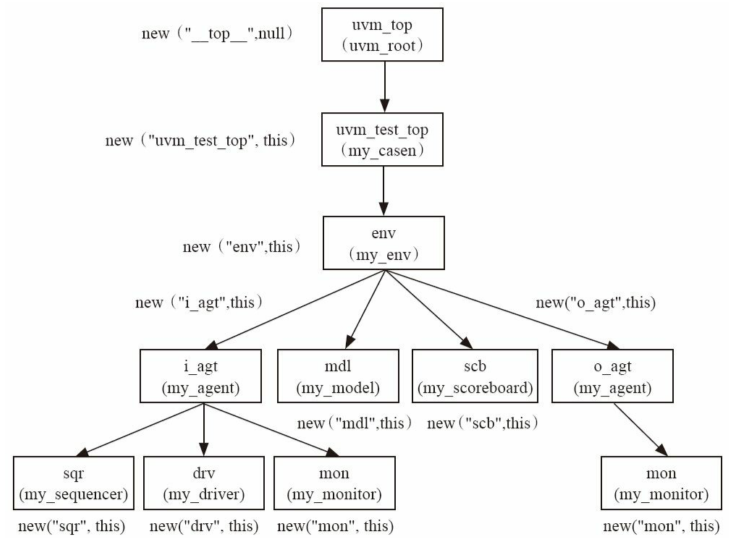
1 | |
打印值为
uvm_test_top.env.i_agt.drv
uvm_top:
uvm_top的名字是__top__,但是在显示路径的时候,并不会显示出这 个名字,而只显示从uvm_test_top开始的路径
uvm_test_top:
uvm_test_top实例化时的名字是uvm_test_top,这个名字是由UVM在run_test时自动指定的路径与层次:
- 路径是
create或new传递的名字组成- 层次结构是由组件句柄的引用
尽量保持保持组件句柄与实例时传递名称统一,否则:
2
3如果drv在new时指定的名字不是drv,而是driver,即:
drv = my_driver::type_id::create("driver");
那么drv在my_casen看来,层次结构依然是env.i_agt.drv,但其路径变为了env.i_agt.driver
3.5.2 set与get函数的参数
config_db用于在UVM验证平台间传递参数,通常成对出现(但是在某些情况下可以只有set而没有get语句,即省略get语句3.5.2节):
- get收信
- set寄信
1.在某个casen的build_phase中可以使用如下方式寄信:
1 | |
第一个和第二个参数联合起来组成目标路径,与此路径符合的目标才能收信
第一个参数
cntxt必须是一个uvm_component实例的指针set第一个参数若为null,UVM会自动把第一个参数替换为代码
uvm_root::get(),即uvm_top第一个参数应该尽量使用
this。在无法得到this指针的情况下(如在top_tb中),使用null或者uvm_root::get()
第二个参数
inst_name是相对此实例的路径第三个参数
field_name表示一个记号,用以说明这个值是传给目标中的哪个成员的第四个参数是要设置的值
2.在driver中的build_phase使用如下方式收信:
1 | |
- 第一个参数和第二个参数联合起来组成路径
第一个参数
cntxt也必须是一个uvm_component实例的指针cntxt- get第一个参数若为null,UVM会自动把第一个参数替换为代码
uvm_root::get(),即uvm_top - 第一个参数应该尽量使用
this。在无法得到this指针的情况下(如在top_tb中,或者seq中),使用null或者uvm_root::get()
- get第一个参数若为null,UVM会自动把第一个参数替换为代码
第二个参数
inst_name是相对此实例的路径(使用组件cntxt作为起始搜索点 ,获取inst_name中field_name的值,如果cntxt是配置对象适用的实例,则inst_name可以是空字符串)- 第三个参数
field_name就是set函数中的第三个参数,这两个参数必须严格匹配 - 第四个参数则是要设置的变量
3.默认句柄:
- set/get第一个参数为null,UVM会自动把第一个参数替换为代码
uvm_root::get(),即uvm_top,以下两种写法是完全等价的:
1 | |
4.set参数也可以这么写
既然set函数的第一个和第二个参数联合起来组成路径,那么在castn的build_phase中可以通过如下的方式设置env.i_agt.drv中pre_num_max的值:
1 | |
- 第一个参数把
this替换为了this.env - 第二个参数是
my_driver相对于env的路径
5.get参数也可以这么写
get函数的参数
1 | |
这些写法都是可以的,只是它们相对于本节最开始的写法没有任何优势。所以还是提倡使用最开始的写法。但是这种写法也 并不是一无是处,在3.5.6节中会介绍它们的一种应用
6.常用写法
- get中用于接收此comp的:参数1:
null或uvm_root::get(),参数2:get_full_name()或从uvm_test_top开始的绝对路径字符串 - set中一般用
this:参数1:this,参数2:子节点的相对路径字符串
3.5.3 省略get语句
set与get函数一般都是成对出现,但是在某些情况下,是可以只有set而没有get语句,即省略get语句
某些情况:指的给在component中使用field automation机制注册的变量传值时,收信方在build_phase中调用super.build_phase()后就可以省略config_db::get直接读取了
示例如下:
1 | |
原理:
这里的关键是build_phase中的super.build_phase语句,当执行到driver的super.build_phase时,会自动执行get语句
这种做法的前提是:
- 组件(这里是my_driver)必须使用
`uvm_component_utils宏注册 - 收信参数(这里是pre_num)必须使用
`uvm_field_int宏注册 - 在调用set函数的时候,set函数的第三个参数必须与要get函数中变量的名字相一致(这里是pre_num)
- 所以上节中,虽然说这两个参数可以不一致,但是最好的情况下还是一致
3.5.4-3.5.5 多重设置
在前面的所有例子中,都是设置一次(config_db#(T)::set),获取一次config_db#(T)::get。但是假如设置多次,而只获取一次,最终会得到哪个值呢?
- 跨层次->组件判断
- 同层次->时间判断(最后优先级最高)
1.跨层次的多重设置
UVM规定层次越高,那么它的优先级越高。这里的层次指的是在UVM树中的位置,越靠近根结点uvm_top,则认为其层次越高。
如何判断set是哪一层的?
- 通过第一个参数:
uvm_config_db#(int)::set(this, "env.i_agt.drv", "pre_num", 100); - 如果第一个参数不是
this而是uvm_root::get(),则都是从uvm_top树根设置,需要进行同层次时间判断 - 因此,无论如何,在调用
set函数时其第一个参数应该尽量使用this。在无法得到this指针的情况下(如在top_tb中),使用null或者uvm_root::get()
2.同层次的多重设置
处于同一层次时,是时间优先,例如下面两个语句同时出现在测试用例的build_phase中时,driver最终获取到的值将会是109:
1 | |
像上面的这种用法看起来完全是胡闹,没有任何意义
3.5.6 非直线与直线的设置与获取
直线设置:在被设置的树干的某个节点组件上设置
非直线设置:在其他节点组件设置
直线获取:在被设置的节点组件上获取
非直线获取:从别的被设置的节点组件那里获取
举例:
在图3-4所示的UVM树中,driver的路径为
uvm_test_top.env.i_agt.drv
- 在
uvm_test_top,env或者i_agt中,对driver中的某些变量通过config_db机制进行设置,称为直线设置- 但是若在其他
component,如scoreboard中,对driver的某些变量使用config_db机制进行设置,称为非直线设置
- 在
my_driver中使用config_db::get获得其他任意component设置给my_driver的参数,称为直线的获取- 假如要在其他的
component,如在reference model中获取其他component设置给my_driver的参数的值,称为非直线的获取
非直线设置的危险:
在UVM树中,build_phase是自上而下执行的,UVM并没有明文指出同一级别的build_phase的执行顺序。所以当my_driver在获取参数值时,my_scoreboard的build_phase可能已经执行了,也可能没有执行,所以,这种非直线的设置,会有一定的风险,应该避免这种情况的出现
非直线获取的便捷(一次设置,多个获取):
非直线的获取可以在某些情况下避免config::set的冗余。上面的例子在reference model中获取driver的pre_num的值,如果不这样做,而采用直线获取的方式,那么需要在测试用例中通过config_db::set分别给reference model和driver设置pre_num的值。 同样的参数值设置出现在不同的两条语句中,这大大增加了出错的可能性。因此,非直线的获取可以在验证平台中多个组件(UVM树结点)需要使用同一个参数时,减少config_db::set冗余
3.5.7 config_db机制对通配符的支持(使用星号)
在config_db::set操作时,其第二个参数都提供了完整的路径,但实际上也可以不提供完整的路径而使用通配符*代替
1.举例说明
2.5.2节的top_tb.sv中,使用完整路径设置virtual interface的代码可以写成这样:
1 | |
3.5.8 检查字符串路径(检查config_db参数二)
1 | |
config_db机制一个致命缺点是,其set函数的第二个参数是字符串,如果字符串写错,那么根本就不能正确地设置参数值,而且SystemVerilog的仿真器也不会给出任何参数错误提示
1.解决方法
UVM提供了一个函数check_config_usage:
- 它可以显示出截止到此函数调用时有哪些参数是被设置过但是却没有被获取过
- 由于config_db的set及get语句一般都用于build_phase阶段,所以此函数一般在connect_phase被调用
使用示例
1 | |
default sequence也会被检查出来:是因为default sequence是设置给main_phase的,它在main_phase的时候被获 取,而main_phase是在connect_phase之后执行的
3.5.9 set_config与get_config
UVM1.2发布,set_config与get_config被从UVM标准中移除,成为过时的用法
1.介绍
1 | |
config_db比set/get_config强大的地方在于,它设置的参数类型并不局限于以上三种。常见的枚举类型、virtual interface、bit类 型、队列等都可以成为config_db设置的数据类型
2.使用示例
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20//文件:src/ch3/section3.5/3.5.9/my_case0.sv
function void my_case0::build_phase(uvm_phase phase);
super.build_phase(phase);
uvm_config_db#(uvm_object_wrapper)::set(this,
"env.i_agt.sqr.main_phase",
"default_sequence",
case0_sequence::type_id::get());
set_config_int("env.i_agt.drv", "pre_num", 999);
set_config_int("env.mdl", "rm_value", 10);
endfunction
//文件: src/ch3/section3.5/3.5.9/my_model.sv
>function void my_model::build_phase(uvm_phase phase);
int rm_value;
super.build_phase(phase);
port = new("port", this);
ap = new("ap", this);
void'(get_config_int("rm_value", rm_value));
`uvm_info("my_model", $sformatf("get the rm_value %0d", rm_value), UVM_LOW)
endfunction命令行使用:
UVM提供命令行参数来对它们进行设置
2<sim command> +uvm_set_config_int=<comp>,<field>,<value>
<sim command> +uvm_set_config_string=<comp>,<field>,<value>在设置int型参数时,可以在其前加上如下的前缀:’b、’o、’d、’h,分别表示二进制、八进制、十进制和十六进制的数据。如果不加任何前缀,则默认为十进制
3.5.10 config_db的调试
chech_config_usage(void):显示出截止到函数调用时,系统中有哪些参数被设置过但是没有被读取过print_config(int num):参数为1表示递归的查询,若为0则只显示当前component的信息,用于找出哪些被设置过的信息对于它们是可见的(不会列出default sequence的相关设置)UVM_CONFIG_DB_TRACE命令行参数
无论哪种方式,如果set函数的第二个参数设置错误,都不会给出错误信息。
本书会在10.6.3节提供一个函数,它会检查set函数的第二个参数,如果不可达,将会给出UVM_ERROR的信息。
第四章UVM中的TLM1.0通信
4.1 TLM1.0
UVM中通信主要有两种方案:
- 方案1:使用IMP直连(4.1-4.2)
- 方案2:使用FIFO连接
方案1直连需要在例化IMP的类中实现相关的功能任务/函数;一定需要一个IMP;在一个类中具有多个IMP时需要使用特殊的宏进行声明,不然会导致该功能函数/任务重载
方案2使用FIFO,可以看作一块缓存加两个IMP,因此不必要实现相关任务,只需要专注于数据
4.1.1 验证平台内部的通信
如果要在两个uvm_component之间通信,如一个monitor向一个scoreboard传递一个数据(如图所示)有哪些方法呢?
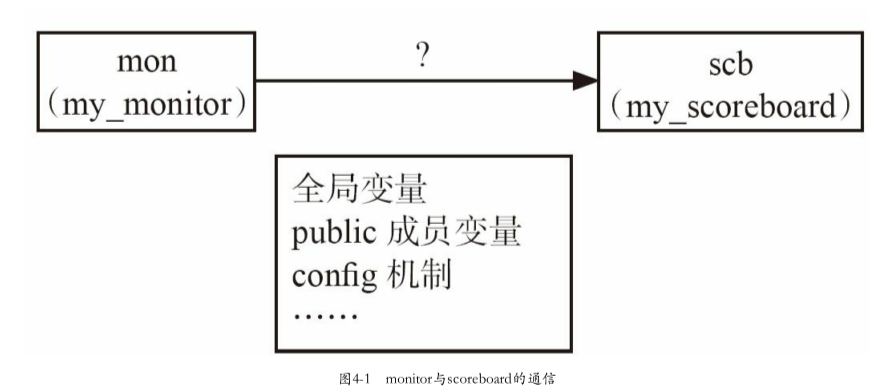
方法一:全局变量
使用全局变量,最简单的方法。在monitor里对此全局变量进行赋值,在scoreboard里监测此全局变量值的改变。这种方法 简单、直接,不过要避免使用全局变量,滥用全局变量只会造成灾难性的后果
方法二:从外部访问类的内部成员变量
从外部访问类的内部成员变量。在scoreboard中有一个变量,这个变量设置为外部可以直接访问的,即public类型的,在monitor中对此变量赋值。这个方法的问题在于,整个scoreboard里面的所有非local类型的变量都对monitor是可见的,而假如monitor的开发人员不小心改变了scoreboard中的一些变量,那么后果将可能会是致命的
方法三:config_db机制,设置与接收
uvm_object.步骤:
- 从
uvm_object派生出一个参数类config_object,在此类中有monitor要传给 scoreboard的变量- 在
base_test中,实例化这个config_object,并将其指针通过config_db#(config_object):set传递给scoreboard和monitor- 当monitor要和scoreboard通信时,只要把此
config_object中相应变量的值改变即可。scoreboard中则监测变量值的改变, 监测到之后做相应动作这种方法比上面的两种方法都要好,但是仍然显得有些笨拙:
- 一是要引入一个专门的config_object类
- 二是一定要有
base_test这个第三方的参与。在大多数情况下,这个第三方是不会惹麻烦的。但是永远不能保证某一个从base_test派生而来的类会不会改变这个config_object类中某些变量的值。也就是说,依然存在一定的风险方法四:最佳方案
使用TLM
为什么不用sv中的机制?
这些问题使用现行的SystemVerilog中的一些机制,如Semaphore、Mailbox,再结合其他的一些技术等都能实现,但是这其中的问题在于这种通信显得非常复杂,用户需要浪费大量时间编写通信相关的代码
解决办法:使用UVM的各种端口
UVM中的各种端口就可以实现这种功能:在monitor和scoreboard之间专门建立一个通道,让信息只能在这个通道内流动,scoreboard也只能从这个通道中接收信息
- 可以保证scoreboard中的信息只能从monitor中来,而不能从别的地方来;
- 同时赋予这个通道阻塞或者非阻塞等特性
4.1.2 TLM的定义
TLM是Transaction Level Modeling(事务级建模)的缩写,起源于SystemC的一种通信标准。
其他内容请参考《UVM入门进阶5(了解):TLM2与同步通信元件》
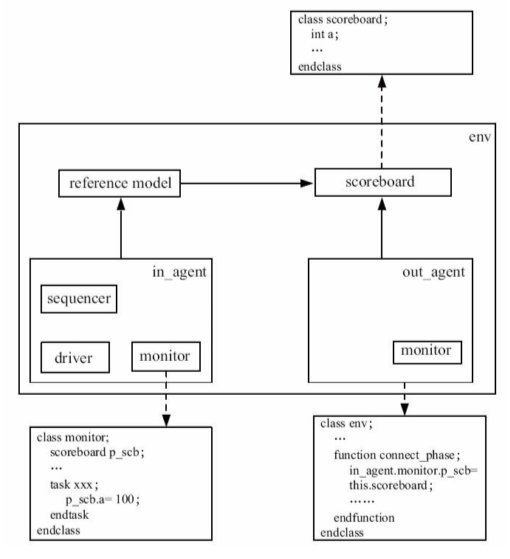
TLM通信常用术语:
put操作,通信的发起者A把一个transaction发送给Bget操作,A向B索取一个transactiontransport操作/requeset-response操作,相当于一次put操作加一次get操作,这两次操作的”发起者”都是A,目标都是B(现实世界中, 相当于是A向B提交了一个请求request,而B返回给A一个响应response。所以这种transport操作也常常被称做request-response操作)
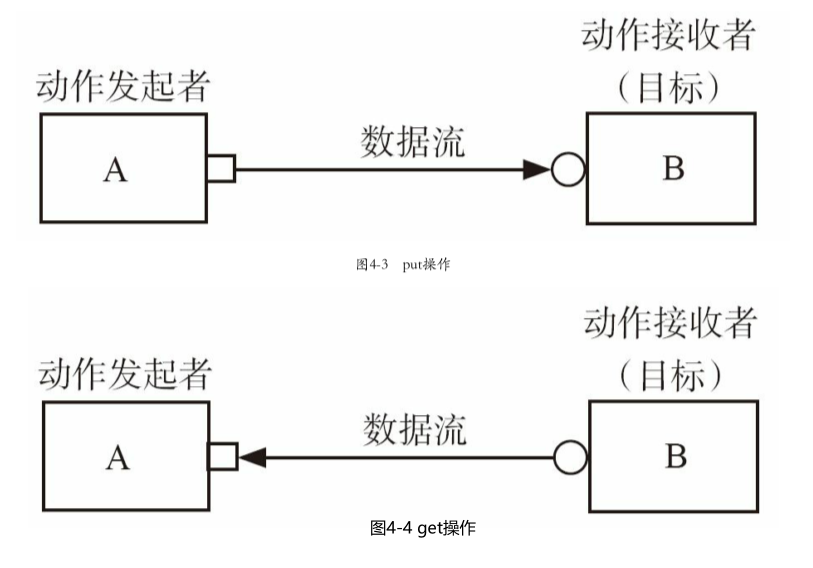
TLM中一共有三种端口:
- PORT
- EXPORT
- IMP(见4.2.2)
上面三种端口的控制流优先级为:PORT>EXPORT>IMP,在调用connect函数时只能高优先级调用,低优先级的端口作为入参
方框为PORT,圆圈为EXPORT,三角为IMP,PORT和EXPORT体现的是控制流而不是数据流
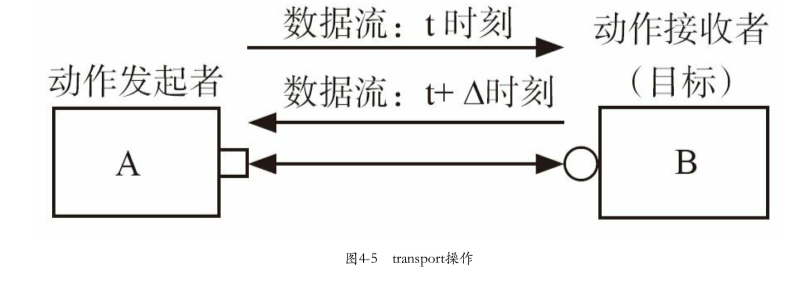
4.1.3 PORT与EXPORT
对应于不同的操作,有不同的PORT与EXPORT
UVM中常用的15个PORT有:
1 | |
UVM中常用的15个EXPORT,与上面15PORT一一对应:
1 | |
参数:
T:这个PORT/EXPORT中的数据流类型REQ, RSP:发起请求时传输的数据类型,返回的数据类型
blocking、nonblocking
- 都没有表示端口既可以用作是阻塞的,也可以用作是非阻塞的
blocking表示该端口只能用作阻塞nonblocking表示该端口只能用作非阻塞- 补充:这种划分方法可以看出,UVM把一个端口固定为只能执行某种操作(如对于
uvm_blocking_put_port#(T),它只能执行阻塞的put操作,想要执行非阻塞的put操作是不行的,想要执行get操作,也是不行的)
4.2a 直连通信
- 4.2.1节至4.2.6节以
blocking_put系列端口为例介绍PORT,EXPORT及IMP之间的互相连接 - 4.2.7节介绍
blocking_get系列端口的连接 - 4.2.8节介绍
blocking_transport系列端口的连接
4.2.1 PORT与EXPORT的连接
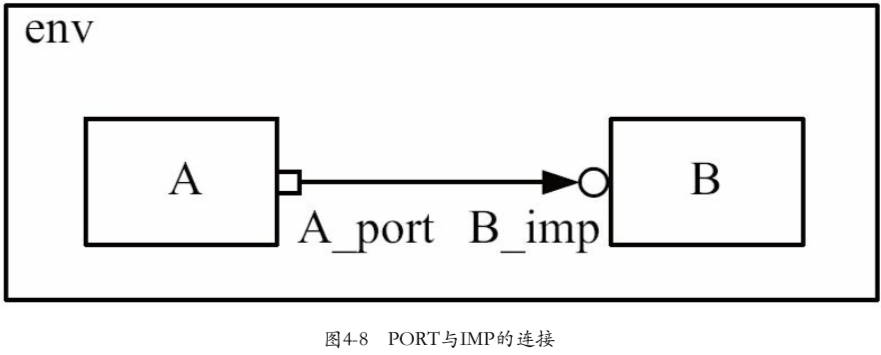
1.UVM中使用connect函数来建立连接
如A要和B通信(A是发起者)则使用A.port.connect(B.export),但不能写成B.export.connect(A.port)。(因为在通信的过程中,A是发起者,B是被动承担者。这种通信时的主次顺序也适用于连接时,只有发起者才能调用connect函数,而被动承担者则作为connect的参数)
2.代码示例:A,B定义
类A的定义(PORT)
1 | |
port实例化参数:
2
3
4function new(string name,
uvm_component parent,
int min_size = 1;
int max_size = 1);
- 参数
name是该PORT名字- 参数
parent是uvm_component父节点变量- 参数
min_size是必须连接到这个PORT的下级端口数量的最小值- 参数
max_size是必须连接到这个PORT的下级端口数量的最大值- 补充:如果不看参数
min_size与max_size,new函数实际上是一个uvm_component的new函数
类B的定义(EXPORT)
1 | |
EXPORT实例化参数:
参考PORT
3.直接建立A_port与B_export的实例变量连接是错误的
我们将在下一节讨论IMP中实现A,B的连接,这节先说明直接连接是错误的
env中A,B错误的直接连接:
1 | |
运行上述代码,可以看到仿真器给出如下的错误提示:
1 | |
解释:A_port,B_export相当于两道门,直接相连没有数据存储,这笔transaction一定要由B_export后续的某个组件进行处理。在UVM中,完成这种后续处理的也是一种端口:IMP
4.2.2 UVM中的IMP
IMP是UVM中的精髓,承担了UVM中TLM的绝大部分实现代码,它的作用:完成接收数据后的处理工作,在UVM中这种后续处理也是端口,即IMP
按照控制流的优先级排序,UVM中三种端口顺序为:PORT、EXPORT、IMP。IMP的优先级最低,一个PORT可以连接到一个IMP,并发起三种操作,反之则不行
UVM中的IMP示例(这15种IMP与15种PORT和15种EXPORT一一对应):
1 | |
参数:
- T是这个IMP传输的数据类型
- IMP为实现这个接口的一个
component
IMP参数怎么理解?
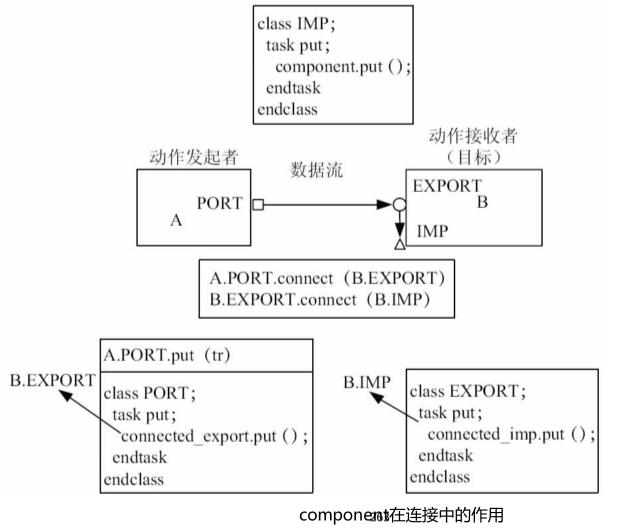
以blocking_put端口为例,在下图中,
A_port被连接到B_export,而B_export被连接到B_imp。当写下A.A_port.put(transaction)时,此时B.B_imp会通知B有transaction过来了,这个过程是如何进行的呢?可以简单理解成A.A_port.put(transaction)这个任务会调用B.B_export的put,B.B_export的put(transaction)又会调用B.B_imp的put(transaction),而B_imp.put最终又会调用B的相关任务,如B.put(transaction)。所以关于A_port的操作最终会落到B.put这个 任务上,这个任务是属于B的一个任务,与A无关,与A的PORT无关,也与B的EXPORT和IMP无关也就是说,(重要)这些put操作最终还是要由B这个component来实现,即要由一个component来实现接口的操作。所以每一个IMP要和一个component相对应。
总结,处理程序调用顺序:
调用A_port.put时的过程:
A_port.put-调用->B_export.put-调用->B_imp.put-调用->B.put重点!
理解下图中A连接到B_export,B_export连接到B_imp这个过程
2.代码示例
1 | |
连接解释:
A_port连接到B_export,B_export连接到B_imp(参考本节第一部分)
如果不实现B的put函数/任务没有实现,则运行代码会报错(为什么要实现B的put,请参考【IMP参数怎么理解?】)
4.2.3 PORT/EXPORT与IMP的连接
TLM中一共有三种端口:
- PORT
- EXPORT
- IMP(见4.2.2)
上面三种端口的控制流优先级为:PORT>EXPORT>IMP,在调用connect函数时只能高优先级调用,低优先级的端口作为入参
1.实现PORT与IMP的连接
背景:有三个component:A、B和env,其中env是A和B的父结点,现在要把A中的PORT和B中的IMP 连接起来实现通信
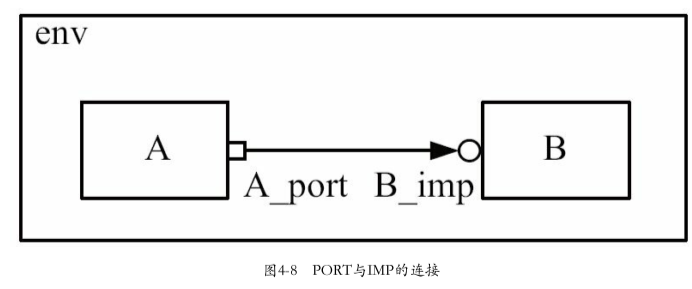
主要步骤:
第一步:A,B中的端口声明
A中采用了
uvm_blocking_put类型的PORT,因此B中IMP相应的类型是uvm_blocking_put_imp补充:参数解释
uvm_blocking_put_imp#(T, IMP)的参数T和IMP:T(要传输的transaction),IMP(实现接口功能的uvm_comonent,这里时B_imp所在的uvm_component B)第二步:功能接口实现:
B中的关键是定义一个任务/函数put,A_port的put操作最终要落到B的put上
补充:功能函数的名称要求
- A_port与B_imp是
blocking_put时B内需要定义1个成员:B.put任务/函数- A_port与B_imp是
nonblocking_put时B内需要定义2个成员:B.try_put函数,B.can_put函数- A_port与B_imp是
put时B内需要定义3个成员:B.put任务/函数,B.try_put函数,B.can_put函数
- A_port与B_imp是
blocking_get时B内需要定义1个成员:B.get任务/函数- A_port与B_imp是
nonblocking_get时B内需要定义2个成员:B.try_get函数,B.can_get函数- A_port与B_imp是
get时B内需要定义3个成员:B.get任务/函数,B.try_get函数,B.can_get函数
- A_port与B_imp是
blocking_peek时B内需要定义1个成员:B.peek任务/函数A_port与B_imp是
nonblocking_peek时B内需要定义2个成员:B.try_peek函数,B.can_peek函数A_port与B_imp是
peek时B内需要定义3个成员:B.peek任务/函数,B.try_peek函数,B.can_peek函数
- A_port与B_imp是
blocking_get_peek时B内需要定义2个成员:B.peek任务/函数,B.get任务/函数A_port与B_imp是
nonblocking_get_peek时B内需要定义4个成员:B.try_peek函数,B.can_peek函数,B.try_get函数,B.can_get函数A_port与B_imp是
get_peek时B内需要定义6个成员:B.peek任务/函数,B.try_peek函数,B.can_peek函数,B.get任务/函数,B.try_get函数,B.can_get函数
- A_port与B_imp是
blocking_transport时B内需要定义1个成员:B.transport任务/函数- A_port与B_imp是
nonblocking_transport时B内需要定义1个成员:B.nb_transport函数- A_port与B_imp是
transport时B内需要定义2个成员:B.transport任务/函数,B.nb_transport函数在前述的这些规律中,对于所有
blocking系列的端口可以是任务,也可以是函数。但是对于nonblocking系列端口来说,只能定义函数。第三步:连接
一定要在connect_phase中调用
connect进行连接,具体实现如下
2
3
4function void my_env::connect_phase(uvm_phase phase);
super.connect_phase(phase);
A_inst.A_port.connect(B_inst.B_imp);
endfunction(可选)第四步调用put:
A发送数据到B调用
put函数,具体实现如下(也是上一节A定义的代码):
2
3
4
5
6
7
8
9
10//文件:src/ch4/section4.2/4.2.3/my_env.sv
task A::main_phase(uvm_phase phase);
my_transaction tr;
repeat(10) begin
#10;
tr = new("tr");
assert(tr.randomize());
A_port.put(tr);//调用了十次put
end
endtask
2.EXPORT与IMP的连接
除了端口声明不同,其他与PORT和IMP连接完全一样(与4.2.2相比,这里export作为起点,而不是中间点),示例代码如下:
1 | |
4.2.5 不同层次之间的连接(PORT与PORT,EXPORT与EXPORT)
1.PORT与PORT的连接
- 在前面的连接中,都是不同类型的端口之间连接(PORT与IMP、PORT与EXPORT、EXPORT与IMP),且不存在层次的关系。在UVM中,支持带层次的连接关系,如下图所示
- PORT与PORT之间的连接不只局限于两层,可以有无限多层
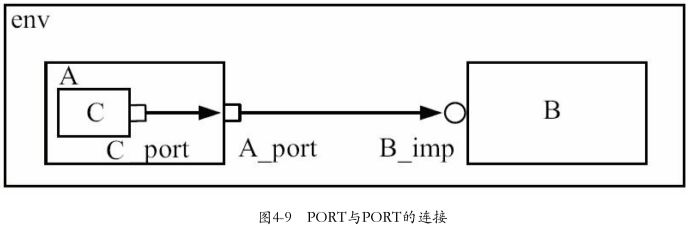
代码片段如下:
1 | |
隐含了控制流关系,内层port调用
connect
2.EXPORT与EXPORT的连接
除了支持PORT与PORT之间的连接外,UVM同样支持EXPORT与EXPORT之间的连接,如下图所示
EXPORT与EXPORT之间的连接也不只局限于两层,也可以有无限多层
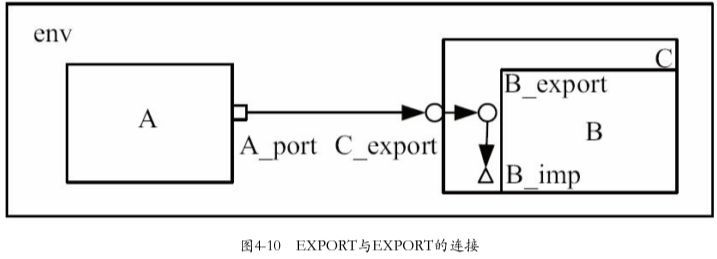
A中是PORT,B与C中是EXPORT,B中还有一个IMP。UVM支持C的EXPORT连接到B的EXPORT,并最终连接 到B的IMP
示例代码如下:
1 | |
隐含了控制流方向,所以是外层调用内层
4.2b 其他功能系列
4.2.7 get
前面几节中都是以blocking_put系列端口为例进行介绍,本节介绍blocking_get系列端口的应用
get系列端口与put系列端口在某些方面完全相反,若要实现下图从A到B的通信,使用blocking_get系列端口的框图
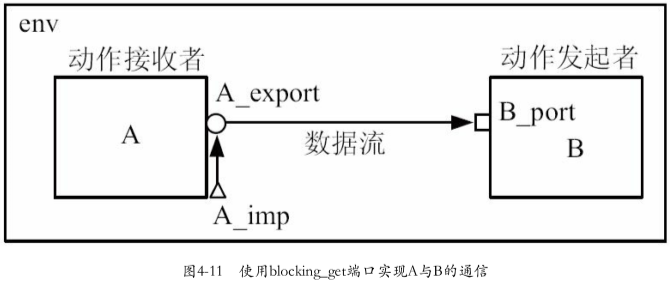
数据流依然是从A到B,但是A由动作发起者变成了动作接收者,而B由动作接收者变成了动作发起者
1.主要步骤:
第一步:A,B中的端口声明
B_port的类型为
uvm_blocking_get_portA_export的类型为
uvm_blocking_get_export,A_imp的类型为uvm_blocking_get_imp第二步:实现功能(与put类似)
uvm_blocking_get_imp所在的component要实现一个名字为get的函数/任务第三步:连接
第四步:调用get
2.代码详解
1 | |
涉及:
①定义接口:
A_export,A_imp②定义功能:数据最终流向A,所以需要A_imp,需要实现数据处理功能,即
get,改功能主要将A内transaction发送到B③连接:在A中把A_export与A_imp连接
1 | |
涉及:
① 端口定义
④调用
get,这个get最终会调用到A.get,从而获取到A中transcation
1 | |
涉及:
③ B_port与A_export连接
3.其他get端口连接
与blocking_put系列端口类似:
blocking_get_port也可以直接连接到blocking_get_impblocking_get_port也可以连接到blocking_get_portblocking_get_export也可以连接到blocking_get_export
在这些连接关系中,需要谨记的是连接的终点必须是一个IMP
4.2.8 transport
特性:双向,与*_get和*_put不同,在*_transport系列端口中, 通信变成了双向的,即又有get又有put
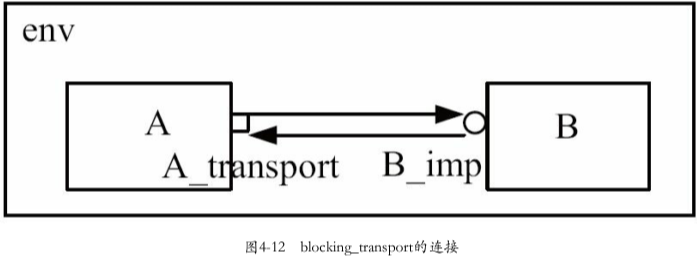
1.主要步骤:
第一步:A,B中的端口声明
A中定义一个
uvm_blocking_transport_*B中需要定义一个类型为
uvm_blocking_transport_imp的IMP第二步:实现功能
IMP所在的component要实现一个名字为
transport任务/函数第三步:连接
第四步:调用
transport
2.代码详解
1 | |
涉及:
① A中定义一个
uvm_blocking_transport_port④ 调用
transport,把生成的transaction作为第一个参数REQ发送到B_imp,B_imp接收到这个参数调用transport任务做了点什么,最后把操作的结果作为transport第二个参数RSP返回回去,A根据RSP进行后面操作
1 | |
涉及:
① B中需要定义一个类型为
uvm_blocking_transport_imp的IMP② 实现
transport,通过A调用主要实现:A把生成的transaction作为第一个参数REQ发送到B_imp,B_imp接收到这个参数调用transport任务做了点什么,最后把操作的结果作为transport第二个参数RSP返回回去,A根据RSP进行后面操作
1 | |
涉及:
③ A_transport_port与B_imp连接
3.其他连接
- 在本例中:
uvm_blocking_transport_port直接连接到uvm_blocking_transport_imp - 还可以:
uvm_blocking_transport_port前者还可以连接到uvm_blocking_transport_export - 总结:
uvm_blocking_transport_port,uvm_blocking_transport_export,uvm_blocking_transport_imp连接关系与uvm_blocking_put系列端口类似
4.2.9 nonblocking
特性:非阻塞,nonblocking端口的所有操作都是非阻塞的,换言之,必须用函数实现,而不能用任务实现,以用nonblocking端口实现图4-8所示的连接关系为例
1.主要步骤:
第一步:A,B中的端口声明
A中定义一个
uvm_nonblocking_*_*_portB中需要定义一个类型为
uvm_nonblocking_*_imp的IMP第二步:实现功能
IMP所在的component要实现:
can_put/get/peek函数,try_put/get/peek函数第三步:连接
第四步:调用
由于端口变为了非阻塞的,所以在送出
transaction之前需要调用can_put函数来确认是否能够执行put操作。can_put最终会调用 B中的can_put,然后再调用try_put真正发送到B_imp中
2.代码详解
1 | |
涉及:
① A中定义一个类型为
uvm_nonblocking_put_port的PORT④ 调用
can_put查询是否能发送,try_put进行发送
1 | |
涉及:
① B中定义一个类型为
uvm_nonblocking_put_imp的IMP② 实现
can_put查询是否能发送的函数,try_put进行发送数据的处理(这里是直接接收了)
1 | |
涉及:
③ A_port与B_imp连接
4.2.10 peek
详情参考4.3.4节,FIFO中的内容
peek端口与get相似,其数据流、控制流都相似,唯一的区别在于当get任务被调用时,FIFO内部缓存中会少一个transaction,而 peek被调用时,FIFO会把transaction复制一份发送出去,其内部缓存中的transaction数量并不会减少
4.3.1 analysis
除了4.2提到的5个功能系列(get/put/transport/peek/get_peek),UVM中还有一个功能系列(analysis)可以实现一对多通信的功能,即广播功能,主要有一下三个
1 | |
1.analysis端口与普通端口的区别:
- 一个analysis_port(analysis_export)可以连接多个IMP,且IMP的类型必须是uvm_analysis_imp
- 对于analysis_port和analysis_export来说,没有阻塞和非阻塞的概念。 因为它本身就是广播,不必等待与其相连的其他端口的响应,所以不存在阻塞和非阻塞
- 对于analysis系列端口来说,只有一种操作:
write(对于普通的put系列端口,有put、try_put、can_put等操作,对于普通的get系列端口,有get、try_get和can_get等操作)
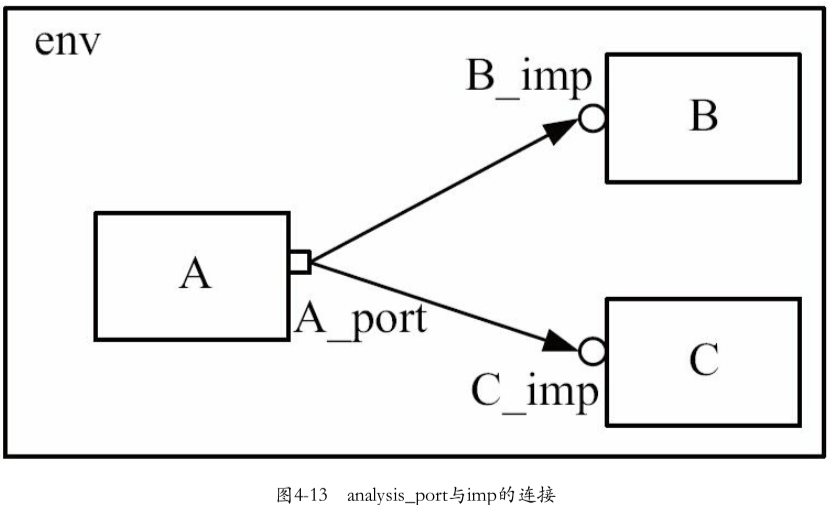
2.上图analysis端口关键代码实现定义
1 | |
4.3.2a 跨层次的三种连接方案
考虑图2-13中o_agt的monitor与scoreboard之间的通信,使用analysis_port实现
1 | |
在env中可以使用connect连接。由于monitor与scoreboard在UVM树中间隔了o_agt,所以这里有三种连接方式
1.第一种:直接跨层次引用
直接在env中跨层次引用monitor中的ap:
1 | |
2.第二种:例化端口连接
在agent中声明一个ap并实例化它,在connect_phase将其与monitor的ap相连,并可以在env中把agent的ap直接连接到 scoreboard的imp:
1 | |
3.第三种:间接跨层次引用(推荐)
在agent中声明一个ap,但是不实例化它,让其指向monitor中的ap。在env中可以直接连接agent的ap到scoreboard的 imp:
1 | |
第一种最简单,但是其层次关系并不好,第二种稍显麻烦,第三种既具有明显的层次关系,同时其实现也较简单
4.3.2b 一个component内有多个IMP
问题背景:在上面的例子中,scoreboard只接收一路数据,但在现实情况中,scoreboard除了接收monitor的数据之外,还要接收reference model的数据。相应的scoreboard就要再添加一个 uvm_analysis_imp的IMP,如model_imp。此时问题就出现了,由于接收到的两路数据应该做不同的处理,所以这个新的IMP也要有一个write任务与其对应。但是write只有一个,怎么办?
一句话问题背景(以下内容都以analysis为例):当一个comp中需要连接多个端口,需要例化多个IMP,多个IMP需要多个write函数,这可怎么办?
方案1:使用FIFO通信,直接不用实现write函数了(4.3中进行解释)
方案2:使用`uvm_analysis_imp_decl宏,直接添加(本节解释)
使用方案2:
UVM考虑到了这种情况,它定义了一个宏`uvm_analysis_imp_decl来解决这个问题,其使用方式为:
1 | |
步骤:
- 上述代码通过宏
`uvm_analysis_imp_decl声明了两个后缀_monitor和_model- UVM会根据这两个后缀定义两个新的IMP类:
uvm_analysis_imp_monitor和uvm_analysis_imp_model,
- UVM会根据这两个后缀定义两个新的IMP类:
- 在
my_scoreboard中分别声明并实例化这两个类:monitor_imp和model_imp - 当与
monitor_imp相连接的analysis_port执行write函数时,会自动调用write_monitor函数 - 当与
model_imp相连接的analysis_port执行write函数时,会自动调用write_model函数
所以,只要完成后缀的声明,并在write后面添加上相应的后缀就可以正常工作了
我的一点总结
4.2主要提到了TLM中的三个端口:PORT,EXPORT,IMP,优先级从左往右,控制流从左往右(还有两种端口ananlaysis,4.3节进行分析)
三种端口又根据功能,分为了不同类型:blocking_put,blocking_get,blocking_transport,noblocking_put,noblocking_get,noblocking_transport
三种端口在一个连接中应保持功能类型的统一,例如:这是一条完整的put通路从blocking_put_port到blocking_put_export再到blocking_put_imp
功能特性主要有:put发送,get接收,transport双向,noblocking非阻塞
- 阻塞:实现的时候可以是任务,从而有了阻塞时间
- 非阻塞:实现的时候应该全都是函数,不应该有时间
IMP类型的端口,需要对数据进行处理,具体讲是需要在定义了IMP端口的类中,实现不同的功能特性任务/函数(对于非阻塞而言只有函数)
- 对于
put功能,需要实现数据的接收 - 对于
get功能,需要实现数据的发送(因为port调用了get,get对应到imp.get并最终调用到该类中的相关函数/任务) - 对于
transport功能,需要实现接收一个请求,返回一个响应 - 对于
nonblocking,需要实现try_*处理函数,以及can_*来判断是否能调用处理函数
4.3 FIFO通信
FIFO的类型有两种:
- 一种是4.3.3中的
uvm_tlm_analysis_fifo - 另外一种是
uvm_tlm_fifo
这两者的唯一差别在于前者有一个analysis_export端口,并且有一个write函数,而后者没有。4.3.4节中介绍的所有端口同时适用于这两者
4.3.3 使用FIFO通信
4.3.2a节中monitor和scoreboard的通信,monitor占据主动地位, 而scoreboard只能被动地接收
那么有没有简单的方法呢?让scoreboard实现主动的接收呢?这两个问题的答案都是肯定的,那就是使用第2章使用的方式:利用FIFO来实现monitor和scoreboard的通信
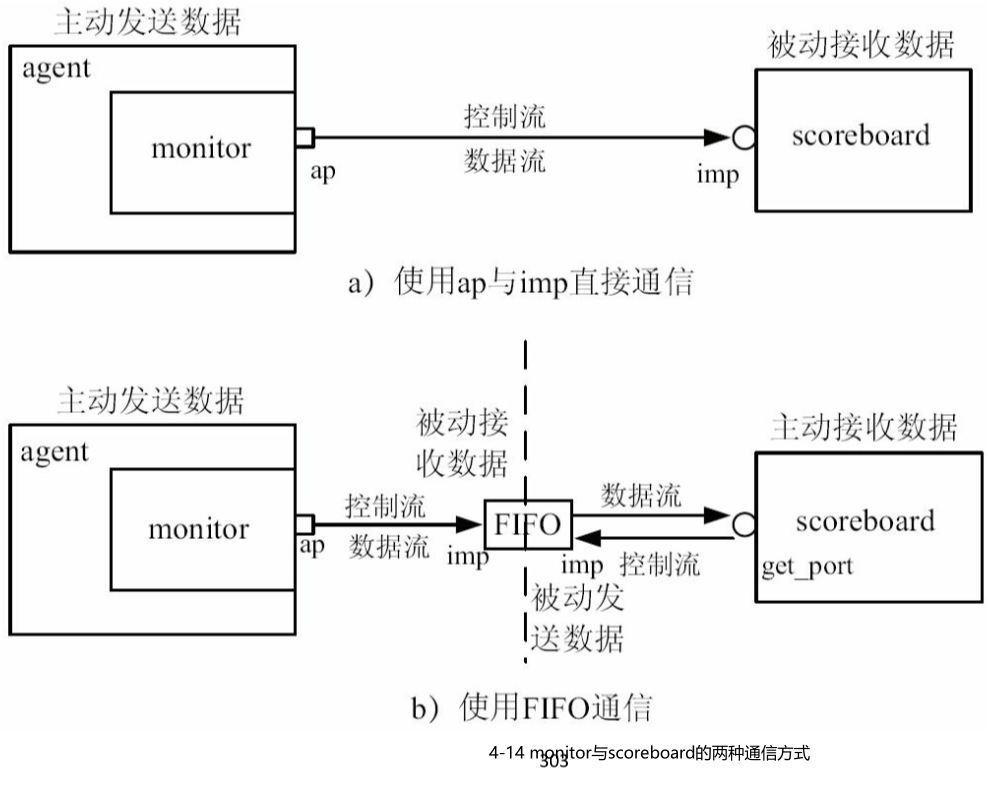
4-14解释
如图4-14b所示,在agent和scoreboard之间添加一个
uvm_analysis_fifo,FIFO的本质是一块缓存加两个IMPFIFO的连接关系中:
- 在monitor与与FIFO的连接关系中,monitor中依然是
analysis_port- FIFO中是
uvm_analysis_imp,数据流和控制流的方向相同- 在scoreboard与FIFO的连接关系中,scoreboard中使用
blocking_get_port端口
FIFO的本质:FIFO的本质是一块缓存加两个IMP
2.FIFO的例化与连接
主要展示my_env.sv(设计框架参考4.3.2a中提到的),FIFO例化与连接的代码
这里再解释一下为什么例化三个FIFO,因为是参考第二章的例子:
agt_scb_fifo意思是从agent到scoreboardagt_mdl_fifo意思是从agent到modelmdl_scb_fifo意思是从model到scoreboard
实现了两条到scoreboard的事务级内部通信:
①dut->agent(monitor)->scoreboard
②agent(drv)->model->scoreboard
1 | |
构造函数:
function new(string name, uvm_component parent = null, int size = 1);
- FIFO在本质上是一个component,所以其前两个参数是uvm_component的
new函数中的两个参数- 第三个参数是
size,用于设 定FIFO缓存的上限,在默认的情况下为1,如果为0则缓存无限连接要点:
- 使用FIFO通信后,连接主要是FIFO的连接
- FIFO上没有
IMP,因为EXPORT就是IMP实现的,解释见下方连接到FIFO的是EXPORT而不是IMP
原因:
实际上,FIFO中的
analysis_export和blocking_get_export虽然名字中有关键字export,但是其类型却是IMP。UVM为了掩饰IMP的存在,在它们的命名中加入了export关键字。如analysis_export的原型如下:
>uvm_analysis_imp #(T, uvm_tlm_analysis_fifo #(T)) analysis_export;
3.FIFO连接的好处
第一个好处是不必在scoreboard中再写一个名字为write的函数。scoreboard可以按照自己的节奏工作,而不必跟着monitor的节奏
第二个好处是FIFO的存在隐藏了IMP,这对于初学者来说比较容易理解
第三个好处是可以轻易解决上一节讲到的当reference model和monitor同时连接到scoreboard应如何处理的问题。事实上,FIFO的存在自然而然地解决了它,这根本就不是一个问题了
4.3.4a FIFO上的端口
4.3.3介绍了FIFO上的blocking_get_export(用于数据获取)和analysis_export(用于数据输入)端口(两个端口实际上是IMP),实际上FIFO端口有众多接口。uvm_tlm_analysis_fifo端口示意图如下:
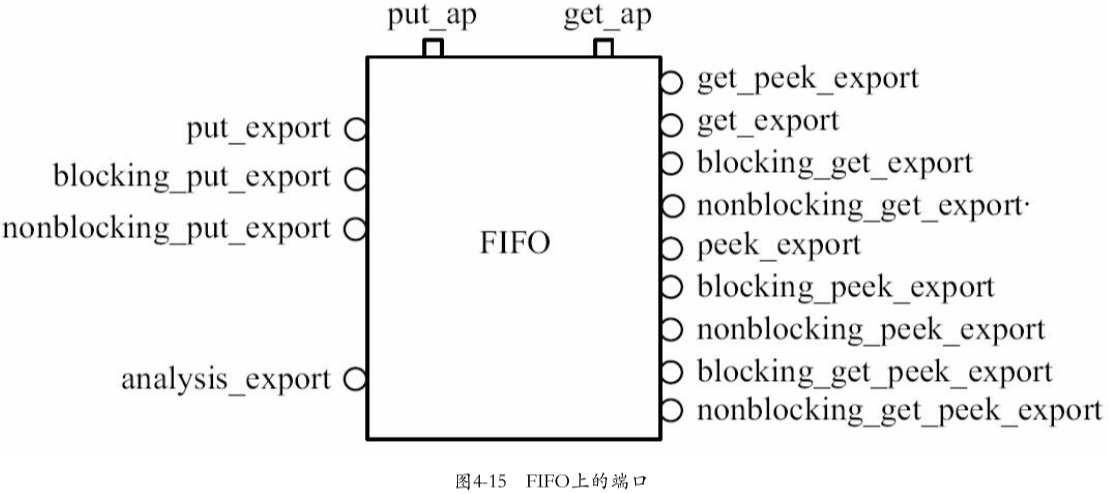
端口:
一共有12+1+2=15个端口,其中12个export是除transport系列外的12种IMP,1个是
uvm_tlm_analysis_fifo的analysis_export,2个是analysis_port2个
analysis_port的作用:
put_ap:
- 大致内容:FIFO的
put任务被调用后,不仅会缓存数据到FIFO,还会通过put_ap端口额外发送出transaction- 具体细节:当FIFO上的
blocking_put_export或者put_export被连接到一 个blocking_put_port或者put_port上时,FIFO内部被定义的put任务被调用,这个put任务把传递过来的transaction放在FIFO内部的缓存里,同时,把这个transaction通过put_ap使用write函数发送出去。FIFO的put任务定义如下:
2
3
4virtual task put(input T t);
m.put(t);//m即是FIFO内部的缓存,使用SystemVerilog中的mailbox来实现
put_ap.write(t);
endtask
get_ap:
- 与
put_ap相似,当FIFO的get任务被调用时,同样会有一个transaction从get_ap上发出,FIFO的get任务定义如下
2
3
4
5
6virtual task get(output T t);
m_pending_blocked_gets++;
m.get(t);
m_pending_blocked_gets--;
get_ap.write(t);
endtask
4.3.4b FIFO的调试函数
UVM也提供了几个函数用于FIFO的调试
used()函数用于查询FIFO缓存中有多少transactionis_empty()函数用于判断当前FIFO缓存是否为空is_full()用于判断当前FIFO缓存是否已经满了flush()用于清空FIFO缓存中的所有数据,一般用于复位
4.4 用FIFO还是用IMP(端口数组与for循环)
每个人对于这个问题都有各自不同的答案
FIFO优点:
- 在用FIFO通信的方法中,完全隐藏了IMP这个UVM中特有、而TLM中根本就没有的东西。用户可以完全不关心IMP。因此,对于用户来说,只需要知道
analysis_port、blocking_get_port即可。这大大简化了初学者的工作量。尤其是在scoreboard面临多个IMP,且需要为IMP声明一个后缀时,这种优势更加明显 - 对于使用端口数组的情况,FIFO要优于IMP,可以使用for循环进行例化、函数调用和端口连接(端口数组<—>FIFO数组的端口)
FIFO缺点:FIFO连接的方式增加了env中代码的复杂度,满满的看上去似乎都是与FIFO相关的代码。尤其是当要连接的端口数量众多时,这个缺点更加明显(毕竟直连不需要在env中例化FIFO,且只需要写一行connect就够了)
2022年11月30日,20:25:04
第5章 UVM验证平台的运行
5.1 phase机制
5.1.1 phase基础
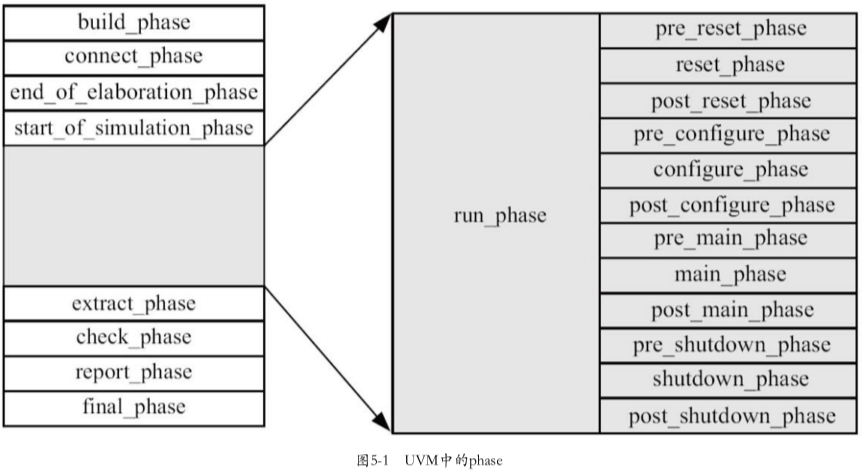
1.phase分类
UVM中的phase,按照其是否消耗仿真时间($time打印出的时间)的特性,可以分成两大类:
- function phase:下图中白色的phase
- task phase:下图中灰色的phase,包括
run_phase和12个run-tiime phase
对于task phase分为两种,一种是run_phase,一种是run-time(运行时/动态运行时) phase,其中run-time phase包括12个小phase
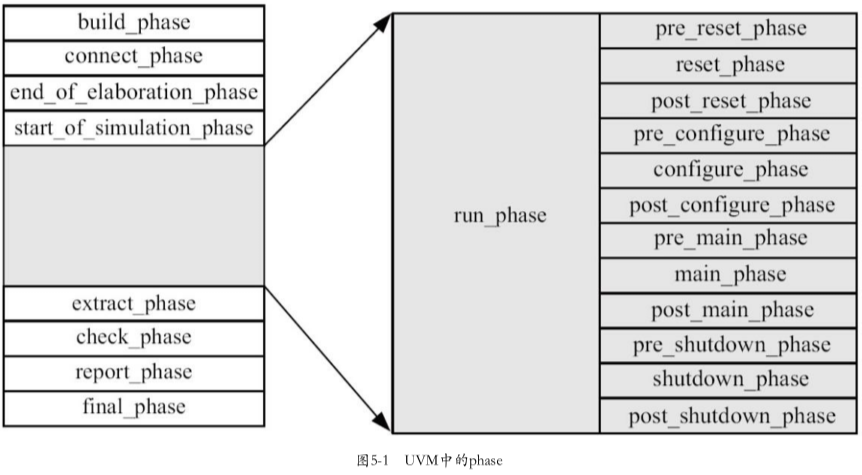
总结:
reset_phase主要做一些清理工作,并等待复位完成为什么这么多phase
- 不会都用:在一般的应用中,无论是
function phase还是task phase都不会将它们全部用上- 使用频率最高:的是
build_phase、connect_phase和main_phase- 好处,方便迁移:这么多phase除了方便验证人员将不同的代码写在不同的phase外,还有利于其他验证方法学向UVM迁移。一般的验证方法学都会把仿真分成不同的阶段,但是这些阶段的划分通常没有UVM分得这么多、这么细致。所以一般来说,当其他验证方法学向UVM迁移的时候,总能找到一个phase来对应原来方法学中的仿真阶段,这为迁移提供了便利
run-time phase引入时间:动态运行(run-time)phase是UVM1.0引入的新的phase,其他phase则在UVM1.0之前(即UVM1.0EA版和OVM中)就已经存在了为什么引入12个
run-time phase?
- 为了精细化的控制:分成小的phase是为了实现更加精细化的控制。reset、configure、main、shutdown四个phase是核心,这四个phase通常模拟DUT的正常工作方式,在reset_phase对DUT进行复位、初始化等操作,在configure_phase则进行DUT的配置,DUT的运行主要在main_phase完成,shutdown_phase则是做一些与DUT断电相关的操作。通过细分实现对DUT更 加精确的控制。假设要在运行过程中对DUT进行一次复位(reset)操作,在没有这些细分的phase之前,这种操作要在 scoreboard、reference model等加入一些额外的代码来保证验证平台不会出错。但是有了这些小的phase之后,分别在scoreboard、 reference model及其他部分(如driver、monitor等)的reset_phase写好相关代码,之后如果想做一次复位操作,那么只要通过phase的跳转,就会自动跳转回reset_phase。(关于跳转的内容,请参考5.1.7节)
run_phase是OVM遗留的phase作用
- function phase:八个
phase- task phase:
run_phase以及12个run-time phasefunction phase
connect_phase
- 传递实例句柄,包括:
reg_model实例在base中传递给env,env传递给ref_model
run-time phase:
reset、configure、main、shutdown四个phase是核心,这四个phase通常模拟DUT的正常工作方式,通过细分实现对DUT更加精确的控制
- 在
reset_phase对DUT进行复位、初始化等操作- 在
configure_phase则进 行DUT的配置- DUT的运行主要在
main_phase完成shutdown_phase则是做一些与DUT断电相关的操作
run_phase是OVM遗留的
2.phase执行的时间顺序
phase首先是按照时间决定当前应该执行哪个phase,再从空间中遍历所有组件运行,当所有组件执行完后该phase进入到下一个phase
所有的phase都会按照图5-1中的顺序自上而下自动执行/启动:
- 对于function phase同一时间只有一个phase在执行
- 对于task phase有两个phase并行:
run_phase和某个run-time phase并行运行,顺序大致如下代码- 对于
run-time phase,执行也是从上到下进行 - 使用domain特性可将不同组件的
run-time phase分隔(见5.3节)
- 对于
1 | |
3.phase执行的空间顺序(以UVM树的视角)
主要顺序:
- build_phase:自上而下
- 其他所有phase(function,task phase):自下而上
同一层次顺序:根据例化时的名称使用字典序的排序
注意:UVM并未保证一直会是这个顺序(这个顺序是在UVM1.1d源代码中找到的,UVM并未保证一直会是这个顺序)。如果代码存在依赖这种顺序的执行,必须立刻修改,并杜绝这种依赖出现
UVM树的遍历顺序:深度优先
注意:如果存在要求位于不同分支的两个组件,某一组件phase提前于另一组件phase执行的代码,必须立刻修改,并杜绝这种依赖出现
不同组件的
task phase顺序并行启动
task phase运行耗费时间,所以它并不是等到“下面”的phase(如driver的run_phase)执行完才执行“上面”的phase(如agent 的run_phase),而是将这些run_phase通过fork…join_none的形式全部启动。所以,更准确的说法是自下而上的启动,同时在运行不同组件的
task phase执行同步(三个同步):
- 所有组件
run-time phase之间需要同步(即所有组件某一run-time phase都进行结束,才代表该run-time phase进行结束,否则提前结束的组件进行等待)- 所有组件
run_phase需要同步(即所有组件run_phase都进行结束,才代表run_phase进行结束,否则提前结束的组件进行等待)run_phase与post_shutdown_phase的同步(即所有组件的run_phase和pose_shutdown_phase都结束,才代表task phase结束,进入extract_phase)
5.1.5 super.phase的使用
前文代码中有的地方调用super.xxx_phase有的地方不调用,这里做下总结
1.前文代码中
在main_phase中,有时出现super.main_phase, 有时又不会;
在build_phase中,一般都会出现super.build_phase
2.何时调用super.xxx_phase
何时调用super.xxx_phase?
- 场景1(使用机制):对于
build_phase且需要自动获取config_dg::set设置参数(config_db),或使用了field automation的时需要调用super.build_phase(如果build_phase不需要自动获得参数就不调用super.build_phase) - 场景2(继承):对于用户自定义类的子类,如果自定义的父类在某个
phase中定义了重要内容,则子类中应该调用super.xxx_phase - 其他大多数情况完全可以不加上
super.xxxx_phase语句,如第2章中所有的super.main_phase都可以去掉。因为除了build_phase外,UVM实现的基础phase没有任何作用,如下代码所示
1 | |
3.补充
以下是我在搜索资料的时候找到的内容
函数/任务内部成员变量定义应在最前面
在my_model中,super用于my_transaction 声明之前如图
会出现下图错误
这样定义则正常,如图
原因:SystemVerilog要求,声明必须位于语句之前(调用
super.xxx_phase就已经开始运行语句了)https://bbs.eetop.cn/thread-852901-1-1.html
new构造函数
new构造函数必须调用super.new(name, parent);,原因:SystemVerilog要求扩展类构造函数调用https://stackoverflow.com/questions/37672145/example-with-super-function-call-in-uvm


5.1.6 build_phase与UVM_ERROR

在end_of_elaboration_phase及其前的phase中,如果出现了一个或多个UVM_ERROR,那么UVM就认为出现了致命错误,会调用uvm_fatal结束仿真。
好处:提高debug效率
UVM的这个特性在小型设计中体现不出优势,但是在大型设计中,这一特性非常有用。大型设计中,真正仿真前的编译、优化可能会花费一个多小时的时间。完成编译、优化后开始仿真,几秒钟后,出现一个
uvm_fatal就停止仿真。当修复了这个问题后,再次重新运行,发现又有一个uvm_fatal出现。如此反复,可能会耗费大量时间。但是如果将这些uvm_fatal替换为uvm_error,将所有类似的问题一次性暴露出来,一次性修复,这会极大缩减时间,提高效率2.2.4节
我们在
connect_phase中,如果config_db::set没有设置成功用则调用`uvm_fatal来结束仿真事实上这里调用
`uvm_error也能结束仿真
5.1.7 phase的跳转
整个验证平台的phase可以实现跳转,通过调用下方两个函数,进行跳转和参数的获取(补充:多domain的run-time phase跳转phase的跳转只能局限在某一domain中(原文5.3.3))
跳转函数
jump
function void uvm_phase::jump(uvm_phase phase);
- 参数必须是一个
uvm_phase类型的变量
uvm_phase类型的变量获取方式如下:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21uvm_build_phase::get();
uvm_connect_phase::get();
uvm_end_of_elaboration_phase::get();
uvm_start_of_simulation_phase::get();
uvm_run_phase::get();
uvm_pre_reset_phase::get();
uvm_reset_phase::get();
uvm_post_reset_phase::get();
uvm_pre_configure_phase::get();
uvm_configure_phase::get();
uvm_post_configure_phase::get();
uvm_pre_main_phase::get();
uvm_main_phase::get();
uvm_post_main_phase::get();
uvm_pre_shutdown_phase::get();
uvm_shutdown_phase::get();
uvm_post_shutdown_phase::get()
uvm_extract_phase::get();
uvm_check_phase::get();
uvm_report_phase::get();
uvm_final_phase::get();那些phase可以作为jump的参数呢?
uvm_reset_phase::get();及以后的phase(除run_phase)run_phase也是不可以跳转的向前跳转与向后跳转
从
main_phase跳转到reset_phase是一种向前跳转,这种向前跳转中,只能是main_phase前的动态运行(run-time phase)中的一个从
main_phase跳转到shutdown_phase是一种向后跳转,在向后跳转中,除了动态运行的phase外(run-time phase),还可以是函数phase,如可以从main_phase跳转到final_phase
我知道你在找这张图
2.一个示例
假如在验证平台中监测到reset_n信号为低电平,则马上从main_phase跳转到reset_phase,driver的代码如下:
1 | |
reset_phase`主要做一些清理工作,并等待复位完成。`main_phase`中一旦监测到reset_n为低电平,则马上跳转到`reset_phase
在my_case中控制objection代码如下:
1 | |
运行上面例子的结果:
1 | |
- 结果整个验证平台都从
main_phase跳转到了reset_phase - 出现了一个UVM_WARNING
- 整个验证平台phase的运行结果图:
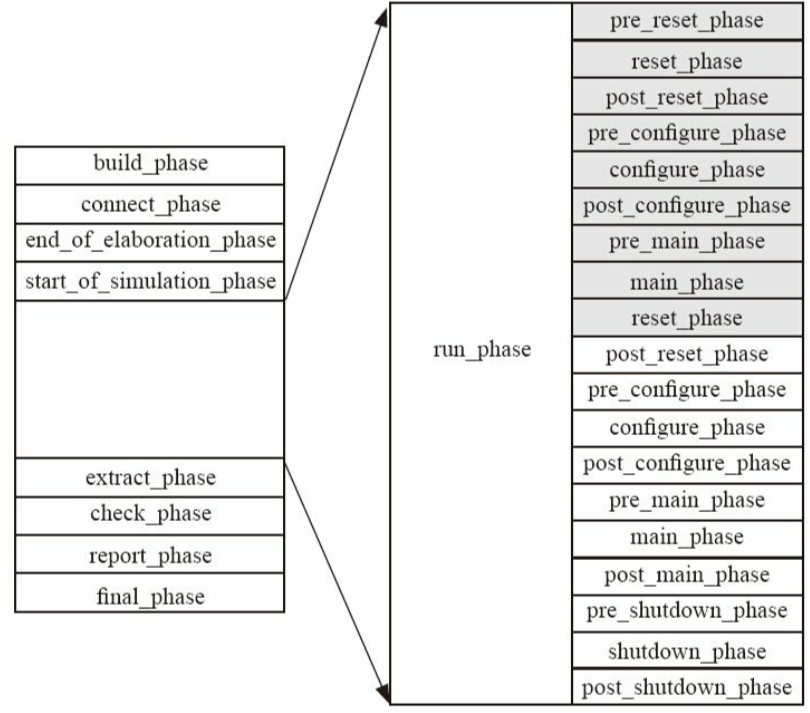
为什么会有
UVM_WARNING?这是因为在 my_driver中调用jump时,并没有把my_case0中提起的objection进行撤销
3.跳转的清理!!!
跳转中最难的地方在于跳转前后的清理和准备工作。如上面的运行结果中的警告信息就是因为没有及时对objection进行清理
对于scoreboard来说,这个问题可能尤其严重。在跳转前,scoreboard的expect_queue中的数据应该清空,同时要容忍跳转后DUT可能输出一些异常数据。
5.1.8 phase机制的必要性
1.Verilog背景
Verilog中有非阻塞赋值和阻塞赋值,相对应的,在仿真器中要实现分为NBA区域和Active区域[1],这样在不同的区域做不同 的事情,可以避免因竞争关系导致的变量值不确定的情况。同样的,验证平台是很复杂的,要搭建一个验证平台是一件相当繁杂的事情,要正确地掌握并理顺这些步骤是一个相当艰难的过程
[1] 可以参照《IEEE Std 1364—2005 IEEE Standard Verilog® Hardware Description Language》
其他参考:https://blog.csdn.net/dinghj3/article/details/122513314
2.UVM的phase
- 在不同时间做不同的事情,这就是UVM中phase的设计哲学
- 仅仅划分成phase是不够的,phase的自动执行功能才极大方便了用户
- phase的引入在很大程度上解决了因代码顺序杂乱可能会引发的问题。遵循UVM的代码顺序划分原则(如build_phase做实例化工作,connect_phase做连接工作等),可以在很大程度上减少验证平台开发者的工作量,使其从一部分杂乱的工作中解脱出来
5.1.9 phase的调试
如果碰到问题后每次都使用`uvm_info在每个phase打印不同的信息显然是不能满足要求的,使用命令行参数自动打印
命令行参数:
1 | |
运行时命令输出:
1 | |
5.1.10 超时退出
超时背景:在验证平台运行时,有时测试用例会出现挂起(hang up)的情况。在这种状态下,仿真时间一直向前走,driver或者monitor并没有发出或者收到transaction,也没有UVM_ERROR出现
测试用例特性:一个测试用例的运行时间是可以预计的,如果超出了这个时间,那么通常就是出错了。在UVM中通过uvm_root的set_timeout函数可以设置超时时间:
1 | |
如上的代码将超时的时间定为500ns。如果达到500ns时,测试用例还没有运行完毕,则会给出一条uvm_fatal的提示信息,并退出仿真
set_timeout:
- 参数1:要设置的时间
- 参数2:此设置是否可以被其后的其他set_timeout语句覆盖(0不可以,1可以)
`UVM_DEFAULT_TIMEOUT宏:
- 默认的超时退出时间是9200s,是通过宏
`UVM_DEFAULT_TIMEOUT来指定的命令行
- 除了可以在代码中设置超时退出时间外,还可以在命令行中设置
- 其中
timeout是要设置的时间,overridable表示能否被覆盖,其值可以是YES或者NO
2
3<sim command> +UVM_TIMEOUT=<timeout>,<overridable>
如
<sim command> +UVM_TIMEOUT="300ns, YES"总结一下提到过让验证平台停止的方法:
- 直接
`uvm_fatal- 设置
UVM_ERROR阈值- 在
end_of_elaboration_phase及其前的phase中,直接调用`uvm_errorset_timeout超时退出drop_objection通知系统可以关闭验证平台(之前需要先raise_objection)
5.2 objection机制
objection字面的意思——反对、异议
5.2.1 objection与task phase
objection的引入是为了解决何时结束仿真的问题,它更多面向task phase,而不是面向function phase,不过在function phase中使用也不报错(原文5.2.2)
1.机制使用
在验证平台中,可以通过drop_objection来通知系统可以关闭验证平台。当然,在撤销 之前首先要
raise_objection,示例代码如下:
1 | |
2
3virtual function void raise_objection ( uvm_object obj = null,
string description = "",
int count = 1 )
- 第一个形参phase是加入objection的phase,如果未指定object或为 null,则选择隐式顶级组件uvm_root
- 第二个形参是字符串,用于标记特定的反对意见,用于跟踪/调试,默认为空
- 第三个形参为objection的数量,默认为1
2.phase与objection
1.UVM
- 在进入到某一phase时,UVM会收集此phase提出的所有objection,并实时监测所有objection是否已经被撤销
- 当发现所有objection都已经撤销后,那么就会关闭此phase,开始进入下一个phase
- 如果UVM发现此phase没有提起任何objection,那么将会直接跳转到下一个phase中
- 当所有的phase都执行完毕后,就会调用
$finish来将整个的验证平台关掉
2.run_phase与run-time phase的objection
对于run_phase来说,有两种方式rasie_objection:
- 方式1:其他
run-time phase中有rasie_objection - 方式2:自己
rasie_objection
对于run-time phase只能自己rasie_objection,在run_phase中的rasie_objection对它没有作用
5.2.2 形参phase的必要性
所有phase的函数/任务的形参中,都有一个phase,如:
1 | |
为什么要有这个形参?
因为要便于在任何component的phase中都能raise_objection,而要raise_objection则必须通过phase.raise_objection来完成,所以必须将phase作为参数传递到main_phase等任务中。可以想象,如果没有这个phase参数,那么想要提起一个objection就会比较麻烦了
作者真能扯
5.2.3 在哪控制objection
在第2章的例子中,最初是在driver中
raise_objection,但是事实上,在driver中raise_objection的时刻并不多。这是因为driver中通常都是一个无限循环的代码,由于无限循环的特性,phase.drop_objection永远不会被执行到
在driver,monitor和reference model中,有类似的情况,它们都是无限循环的,因此一般其中控制objection
一般来说,在一个实际的验证平台中,通常会选择以下两种方案之一:
方案1:在scoreboard中进行控制
在2.3.6节中,scoreboard的main_phase被做成一个无限循环如果要在scoreboard中控制objection,则需要去除这个无限循环,通过config_db::set的方式设置收集到的transaction的数量pkt_num,当收集到足够数量的transaction后跳出循环:
1 | |
上述代码中将原本的fork...join语句改为了fork...join_any。当收集到足够的transaction后,第二个进程终结,从而跳出 fork…join_any,执行drop_objection语句
方案2:如在第2章中介绍的例子那样,在sequence中提起sequencer的objection,当sequence完成后,再撤销此objection
总结:以上两种方式在验证平台中都有应用。其中用得最多的是第二种,这种方式是UVM提倡的方式。UVM的设计哲学就是全部 由sequence来控制激励的生成,因此一般情况下只在sequence中控制objection
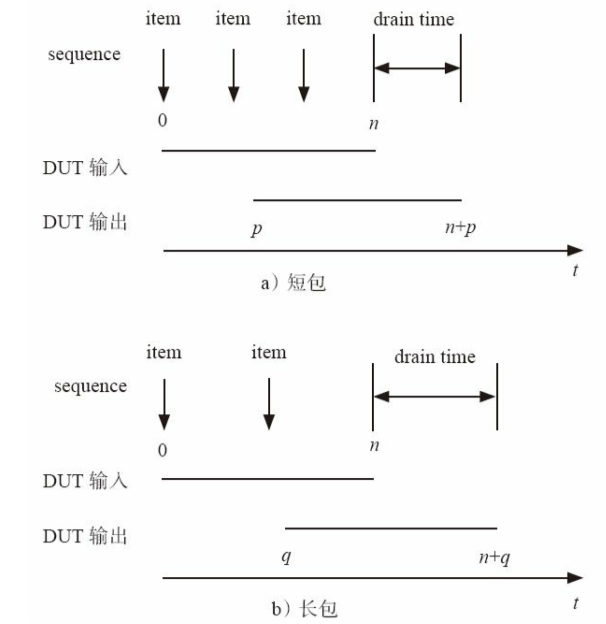
5.2.4 drain_time(撤销objection延时)
在sequence中,n时刻发送完毕最后一个transaction,如果此时立刻drop_objection,那么最后在n+p时刻DUT输出的包将无法接收到。因此,在sequence中,最后一个包发送完毕后,要延时p时间才能drop_objection
1.考虑两种实现方式
第一种,直接#(无法控制延迟时间)
1 | |
缺点:
- 随机发送激励时,延时的大小也是随机的,所以无法精确地控制延时,只能根据激励选择一个最大的延时
- 如果某一天,DUT对于同样的激励,其处理延时变大,那就要修改所有的延时大小
第二种,使用drain_time
所谓drain_time,就是所有objection被撤销后等待一段时间,在这段时间内,那些正在运行的线程依然在正常地运转,drain_time过去才进入下一phase
drain_time的设置方式为:phase.phase_done.set_drain_time
1 | |
phase_done是uvm_phase内定义的一个成员变量:
uvm_objection phase_done; // phase done objection一个phase对应一个drain_time,并不是所有的phase共享一个drain_time
在没有设置的情况下,drain_time的默认值为0
5.2.5 objection的调试
与phase的调试一样,UVM同样提供了命令行参数来进行objection的调试:
1 | |
结果如下:
1 | |
在调用raise_objection时,count=1表示此次只提起了这一个objection,下面代码是提起两个objection的结果
1 | |
5.3 domain
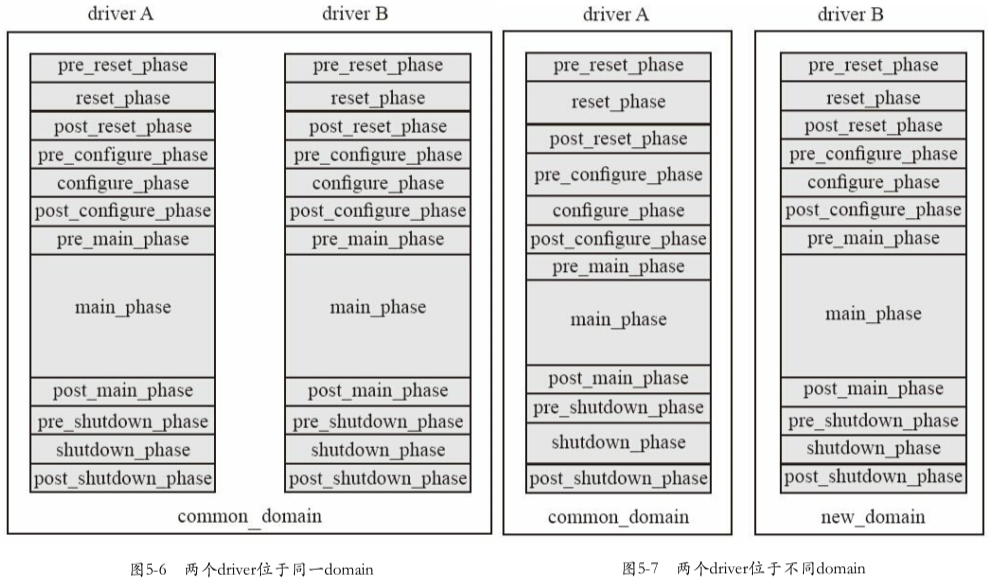
5.3.1 domain简介
问题背景:设DUT分成两个相对独立的部分,这两个独立的部分可 以分别复位、配置、启动,但如果没有domain的概念,那么这两块独立的部分则必须同时在reset_phase复位,同时在configure_phase配置,同时进入main_phase开始正常工作。这种协同性当然是没有问题的,但是没有体现出独立性。图5-6中画出了这两个部分的driver位于同一domain的情况
解决方案,使用不同domain划分多个时钟域,这图5-7中列出了两个driver位于不同domain的情况,实现了两个driver的run-time phase异步执行
domain特性:
- 默认情况下,验证平台中所有component都位于一个名字为
common_domain的domain中 - domain只能隔离
run-time phase,无法隔离run_phase和function phase - phase的跳转只能局限在某一domain中(原文5.3.3)
5.3.2 多domain的例子
如何把某个组件置于新的domain中:
1 | |
步骤:
声明一个了一个
uvm_domain:uvm_domain new_domain;在构造函数中实例化该
uvm_domain:new_domain = new("new_domain");在
connect_phase中将该组件加入到domain中:set_domain(new_domain);
function void uvm_component::set_domain(uvm_domain domain, int hier=1);
- 第二个参数表示是否递归调用,如果为1,则
domain及其子节点都将全部加入到该domain中。由于子节点的实例化一般在build_phase中完成,所以这里一般在connect_phase中调用set_domain
2022-12-02 15:45:38
第六章 UVM中的sequence :seedling:
6.1 sequence基础
6.1.1 激励产生(从driver中剥离激励产生功能)
为什么激励最初产生在driver中,后来产生在sequence中?
- 原因:如果要修改激励,则需要将driver.main_phase重新写了一遍,可扩展性太差
分析后发现main_phase代码只有中间的改变了,那为什么不定义一个gen_pkt用于专门产生激励的函数来替代这段代码?
- 原因1:如果直接定义两个
gen_pkt则不符合sv,造成重复定义 - 原因2:如果使用虚函数,则需要定义新的子类
driver,重载gen_pkt函数,更麻烦了
为解决上面的问题,UVM引入了sequence机制,在解决的过程中还使用了factory机制、config机制,具体来讲:使用sequence机制之后,在不同的测试用例中,将不同的sequence设置成sequencer的main_phase的default_sequence。当sequencer执行到main_phase时,发现有default_sequence,那么它就启动sequence
sequence机制和TLM的区别?
- sequence机制描述的是,sequence、sequencer、agent、driver之间的关系
- TLM描述的是其他组件之间的事务级连接
sequence机制如何实现的?猜测resource_db机制
resource_db机制与config_db机制的底层实现是一样的,uvm_config_db类就是从uvm_resource_db类派生而来的。在寄存器模型的sequence中,get操作是通过resource_db来进行的(详见7.6.2)
6.1.2 sequence机制回顾
sequence的实例化有两种方式:
- 手动调用
seq::start(sqr)函数 - 使用
default_sequence
执行逻辑:
body:
- 每一个sequence都有
pre_body、body、post_body任务 - 当一个sequence启动后会自动执行sequence的
pre_body、body、post_body任务 - 作用:
- 发送transcation(
`uvm_do,`uvm_send…) - 控制objection机制
- 发送transcation(
sequence机制参考实现步骤(2.4.3):
- sqr定义(只用简单注册一下sqr到factory,其他不用实现)
- sqr实例化(在agent中例化sqr,drv,mon)
- seq定义(主要定义
body()函数,并在该函数内调用`uvm_do用来发送激励)- seq的实例化(两种方案:手动
new;或者在使用default_sequence是参数四指定为case0_sequence::type_id::get()形式- seq启动(在case/env中启动,有两种方案:手动
seq.start(sqr)或default_sequence)- 连接driver与sqr(在agent中连接,使用继承自UVM各自组件的端口,代码:
drv.seq_item_port.connect(sqr.seq_item_export))- drv申请item(在driver的
main_phase向sqr申请数据,使用到seq_item_port.get_next_item(req);和seq_item_port.item_done();
item_done还可以用来返回response(6.7.1)
default_sequence如何使用:调用uvm_config_db
1 | |
方式总结
方式①:手动实例化+手动启动(在case中直接定义)
1 | |
方式②:工厂实例化+手动启动(在vseq中定义,vseq在case中使用default_sequence自动实例化)
1 | |
方式③:手动实例化 + default_sequence(seq实例,如某seq)
这样做的好处就是,既可以利用default_sequence,又可以配置sequence_library_cfg省去繁杂的配置(6.8.4)
1 | |
方式④:直接default_sequence(seq类的id,如case0_sequence::type_id::get())
1 | |
default_sequence做了什么?
① 在uvm_sequence这个基类中,有一个变量名为starting_phase,它的类型是uvm_phase,sequencer在启动default_sequence时,会执行如下代码,实现在sequence中使用starting_phase进行提起和撤销objection:
2seq.starting_phase = phase;
seq.start(this);
6.2 sequence的仲裁机制
6.2.1 在同一sequencer上启动多个sequence
1.如何定义
定义两个sequence,运行后会显示两个sequence交替产生transaction
1 | |
2.优先级
sequencer根据什么选择使用哪个sequence的transaction呢?
依据创建的transaction的优先级、sequencer的仲裁算法、sequence的优先级,优先级越高越容易选中
- 使用
`uvm_do(SEQ_OR_ITEM) 或 `uvm_do_with(SEQ_OR_ITEM, CONSTRAINTS)宏时创建的seq默认优先级为-1- 默认sqr的仲裁算法为
SEQ_ARB_FIFO,它会严格遵循先入先出的顺序,而不会考虑优先级- seq时启动时可以指定seq的优先级:
seq.start(sqr, null, pri);改变transaction优先级
可以通过
`uvm_do_pri(SEQ_OR_ITEM, PRIORITY) 或 `uvm_do_pri_with(SEQ_OR_ITEM, PRIORITY, CONSTRAINTS)改变所产生的transaction的优先级,其中形参pri必须≥-1,代码示例如下:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43class sequence0 extends uvm_sequence #(my_transaction);
my_transaction m_trans;
function new(string name= "sequence0");
super.new(name);
endfunction
virtual task body();
if(starting_phase != null)
starting_phase.raise_objection(this);
repeat (5) begin
`uvm_do_pri(m_trans, 100)
`uvm_info("sequence0", "send one transaction", UVM_MEDIUM)
end
#100;
if(starting_phase != null)
starting_phase.drop_objection(this);
endtask
`uvm_object_utils(sequence0)
endclass
class sequence1 extends uvm_sequence #(my_transaction);
my_transaction m_trans;
function new(string name= "sequence1");
super.new(name);
endfunction
virtual task body();
if(starting_phase != null)
starting_phase.raise_objection(this);
repeat (5) begin
`uvm_do_pri_with(m_trans, 200, {m_trans.pload.size < 500;})
`uvm_info("sequence1", "send one transaction", UVM_MEDIUM)
end
#100;
if(starting_phase != null)
starting_phase.drop_objection(this);
endtask
`uvm_object_utils(sequence1)
endclass仲裁算法
如果只设置了优先级,则两个sequence还是交替产生transaction,因为默认的仲裁算法为
SEQ_ARB_FIFO为先进先出不考虑优先级,sequencer的仲裁算法有以下几种:
2
3
4
5
6SEQ_ARB_FIFO,
SEQ_ARB_WEIGHTED,//加权的仲裁
SEQ_ARB_RANDOM,//完全随机选择
SEQ_ARB_STRICT_FIFO,//严格按照优先级,当有多个同一优先级的sequence时,按照先入先出的顺序选择
SEQ_ARB_STRICT_RANDOM,//严格按照优先级,当有多个同 一优先级的sequence时,随机从最高优先级中选择
SEQ_ARB_USE//用户自定义一种新的仲裁算法想使优先级起作用,应该使用sqr的方法
set_arbitration设置仲裁算法为SEQ_ARB_STRICT_FIFO或者SEQ_ARB_STRICT_RANDOM,设置示例:
2
3
4
5
6
7
8
9
10
11
12
13
14task my_case0::main_phase(uvm_phase phase);
sequence0 seq0;
sequence1 seq1;
seq0 = new("seq0");
seq0.starting_phase = phase;
seq1 = new("seq1");
seq1.starting_phase = phase;
env.i_agt.sqr.set_arbitration(SEQ_ARB_STRICT_FIFO);//调用set_arbitration设置
fork
seq0.start(env.i_agt.sqr);
seq1.start(env.i_agt.sqr);
join
endtask改变sequence优先级
对sequence设置优先级的本质即设置其内产生的transaction的优先级,通过调用的启动任务
virtual task start(sequencer, parent_sequence=null, this_priority=-1, call_pre_porst=1),优先级参数this_priority选择不同的参数进行sequence优先级的改变,使用示例如下:
2
3
4
5
6
7
8
9
10
11
12
13
14task my_case0::main_phase(uvm_phase phase);
sequence0 seq0;
sequence1 seq1;
seq0 = new("seq0");
seq0.starting_phase = phase;
seq1 = new("seq1");
seq1.starting_phase = phase;
env.i_agt.sqr.set_arbitration(SEQ_ARB_STRICT_FIFO);
fork
seq0.start(env.i_agt.sqr, null, 100);
seq1.start(env.i_agt.sqr, null, 200);
join
endtask
6.2.2 lock操作与仲裁进一步理解
使用方式:直接调用uvm_sequence方法lock()与unlock()
定义:所谓lock,就是一个使用了lock操作的sequence向sequencer发送一个请求,这个请求与其他sequence发送事务的请求一同被放入sequencer的仲裁队列中。当其前面的所有请求被处理完毕后,sequencer就开始响应这个使用lock的sequence,此后sequencer会一直连续发送此sequence的transaction,直到unlock被调用
补充:如果两个sequence都使用了lock操作,则先被处理的sequence先占用sequencer,直到unlock被调用
一个使用lock操作的sequence为:
1 | |
6.2.3 grab
grab与lock类似,用于立即占用sequencer
使用方式:直接调用uvm_sequence方法grab()与ungrab()
定义:grab操作比lock操作优先级更高。lock请求是被插入 sequencer仲裁队列的最后面,等到它时,它前面的仲裁请求都已经结束了。grab请求则被放入sequencer仲裁队列的最前面,它几乎是一发出就拥有了sequencer的所有权
补充:
- 如果两个sequence都使用了
grab操作,则先被处理的sequence先占用sequencer,直到ungrab被调用(与lock一样) - 如果sequencer已经被某个sequence使用
lock占用,另一个使用grab操作的请求依旧需要等待,不能打断
一个使用grab操作的sequence为:
1 | |
6.2.4 sequence的有效性
使用方式(成对重载,不然会报错):
- 重载自定义的
uvm_sequence子类的is_relevant()函数 - 重载自定义的
uvm_sequence子类的wait_for_relevant()函数,该函数要使sequence无效的条件清除 - 成对重载上面两个函数不然会报错:
UVM_FATAL @ 1166700: uvm_test_top.env.i_agt.sqr@@seq0 [RELMSM] is_relevant()was implemented without def(代码6-19没有重载是因为巧妙设计了延迟,可以保证调用不到wait_for_relevant())
执行逻辑:
- sequencer在仲裁时,会查看sequence的
is_relevant()函数的返回结果。如果为1,说明此sequence有效,否则无效 - 当sequencer发现在其上启动的所有sequence都无效时,此时会调用sequence的
wait_for_relevant()函数,当wait_for_relevant返回后,sequencer会继续调用sequence的is_relevant,发现依然是无效状态,则继续调用wait_for_relevant,系统会处于死循环的状态。(这个过程中,其他有效的seq照样发送,即等待的是该发射无效seq的线程而不是sqr整体)
6.3 sequence相关宏
6.3.1 uvm_do系列宏
1 | |
使用注意事项:
- 只能在sequence类里面用
①
`uvm_do(SEQ_OR_ITEM)作用:
- 将一个my_transaction的变量m_trans实例化
- 将m_trans随机化
- 最终将m_trans送给sequencer
如果不用
`uvm_do宏,也可以直接使用start_item与finish_item的方式产生transaction什么时候返回:等待driver的
item_done使用方法(2.4.2 sequence机制):
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16class my_sequence extends uvm_sequence #(my_transaction);
my_transaction m_trans;
function new(string name= "my_sequence");
super.new(name);
endfunction
virtual task body();
repeat (10) begin
`uvm_do(m_trans)
end
#1000;
endtask
`uvm_object_utils(my_sequence)
endclass②
`uvm_do_with(SEQ_OR_ITEM, CONSTRAINTS)作用:类似于
`uvm_do,CONSTRAINTS参数用于在随机化时提供对某些字段的约束补充:参考2.5.2
③
`uvm_do_pri(SEQ_OR_ITEM, PRIORITY)作用:类似于
`uvm_do,PRIORITY参数用于给trans添加优先级补充:参考6.2节
④
`uvm_do_pri_with(SEQ_OR_ITEM, PRIORITY, CONSTRAINTS)作用:类似于
`uvm_do_with,PRIORITY参数用于给trans添加优先级⑤
`uvm_do_on(SEQ_OR_ITEM, SEQR)作用:用于显式地指定使用哪个sequencer发送此transaction
参数:
SEQ_OR_ITEM:transaction的指针SEQR:sequencer的指针补充:
uvm_do等价于:`uvm_do_on(tr, this.m_sequencer)- 当在sequence中使用
`uvm_do等宏时,其默认的sequencer就是此sequence启动时为其指定的sequencer,sequence将这个sequencer的指针放在其成员变量m_sequencer中- 在这里看起来指定使用哪个sequencer似乎并没有用,它的真正作用要在6.5节virtual sequence中得到体现
⑥
`uvm_do_on_pri(SEQ_OR_ITEM, SEQR, PRIORITY)作用:
uvm_do_on和uvm_do_pri⑦
`uvm_do_on_with(SEQ_OR_ITEM, SEQR, CONSTRAINTS)作用:
`uvm_do_on和`uvm_do_with⑧
`uvm_do_on_pri_with(SEQ_OR_ITEM, SEQR, PRIORITY, CONSTRAINTS)作用:
uvm_do_on和uvm_do_pri和uvm_do_with补充:
`uvm_do系列的其他七个宏其实都是,`uvm_do_on_pri_with宏来实现的。如uvm_do宏:
2`define uvm_do(SEQ_OR_ITEM) \
`uvm_do_on_pri_with(SEQ_OR_ITEM, m_sequencer, -1, {})⑨其他产生transaction的方法:
除了使用
`uvm_do宏产生transaction,还可以使用`uvm_create宏与`uvm_send宏来产生
6.3.2 uvm_send系列
除了使用`uvm_do宏产生transaction,还可以使用`uvm_create宏,`uvm_send宏来产生
①
`uvm_create与`uvm_send产生transaction步骤:
`uvm_create实例化transaction;或者直接使用new进行实例化- 对transaction实例做自定义操作
`uvm_send发送transaction好处:比
`uvm_do系列宏更灵活使用实例:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53/* 一个使用`uvm_create与`uvm_send的实例 */
class case0_sequence extends uvm_sequence #(my_transaction);
my_transaction m_trans;
function new(string name= "case0_sequence");
super.new(name);
endfunction
virtual task body();
int num = 0;
int p_sz;
if(starting_phase != null)
starting_phase.raise_objection(this);
repeat (10) begin
num++;
`uvm_create(m_trans)
assert(m_trans.randomize());
p_sz = m_trans.pload.size();
{m_trans.pload[p_sz - 4],
m_trans.pload[p_sz - 3],
m_trans.pload[p_sz - 2],
m_trans.pload[p_sz - 1]}
= num;
`uvm_send(m_trans)
end
#100;
if(starting_phase != null)
starting_phase.drop_objection(this);
endtask
`uvm_object_utils(case0_sequence)
endclass
/* 一个使用new与`uvm_send的实例*/
...
virtual task body();
int num = 0;
int p_sz;
if(starting_phase != null)
starting_phase.raise_objection(this);
repeat (10) begin
num++;
m_trans = new("m_trans")
assert(m_trans.randomize());
p_sz = m_trans.pload.size();
{m_trans.pload[p_sz - 4],
m_trans.pload[p_sz - 3],
m_trans.pload[p_sz - 2],
m_trans.pload[p_sz - 1]}
= num;
`uvm_send(m_trans)
end
...②
`uvm_send_pri除
`uvm_send外,还有`uvm_send_pri用于将transaction交给sequencer时设定优先级③
`uvm_rand_send系列
2
3
4`uvm_rand_send(SEQ_OR_ITEM)
`uvm_rand_send_pri(SEQ_OR_ITEM, PRIORITY)
`uvm_rand_send_with(SEQ_OR_ITEM, CONSTRAINTS)
`uvm_rand_send_pri_with(SEQ_OR_ITEM, PRIORITY, CONSTRAINTS)作用:
`uvm_rand_send与`uvm_send系列类似,唯一区别是对transaction进行随机化使用示例:
2
3
4`uvm_rand_send(m_trans
`uvm_rand_send_pri(m_trans, 100)
`uvm_rand_send_with(m_trans, {m_trans.pload.size == 100;})
`uvm_rand_send_pri_with(m_trans, 100, {m_trans.pload.size == 100;})
6.3.4 不使用宏产生transaction(`start_item与`finish_item)
不使用宏产生transaction的方式要依赖于两个任务:`start_item与`finish_item
`start_item与`finish_item产生步骤(必须先实例化transaction):
2
3tr = new("tr");
start_item(tr);
finish_item(tr);指定优先级:
2start_item(tr, 100);
finish_item(tr, 100);加入随机化与assert:
2
3
4tr = new("tr");
start_item(tr);
assert(tr.randomize() with {tr.pload.size() == 200;});
finish_item(tr);
6.3.5 精细化控制(pre_do、mid_do与post_do)
`uvm_do宏封装了从transaction实例化到发送的一系列操作,封装的越多,则其灵活性越差
为了增加uvm_do系列宏的功能, UVM提供了几个接口:wait_for_grant、pre_do,mid_do、send_request、wait_for_item_done、post_do
这几个函数/方法执行顺序如图:

其中:
pre_do是一个任务,在start_item中被调用,是start_item返回前执行的最后一行代码- 一个参数,用于表明
`uvm_do宏是在对一个transaction还是在对一个sequence进行操作(参考6.4.1)
- 一个参数,用于表明
mid_do是一个函数,位于finish_item的最开始- 一个参数,是正在操作的sequence或者item的指针,但其类型是
uvm_sequence_item,需要调用$cast来转为自定义的seq或item用于自定义操作
- 一个参数,是正在操作的sequence或者item的指针,但其类型是
post_do是一个函数,位于finish_item中,是finish_item返回前执行的最后一行代码- 一个参数,同
mid_do
- 一个参数,同
使用示例:
1 | |
6.4 sequence进阶
6.4.1 嵌套sequence
在sequence中,除了可以使用`uvm_do宏产生transaction外,其实还可以启动其他的sequence,实现嵌套sequence
补充:一个seq中所有的transaction应保持一种类型,嵌套的seq也应保持transaction一致,详情6.4.3
方法1:手动new与start
1 | |
方法2:调用`uvm系列宏
之前介绍的,uvm_do宏、uvm_send宏、uvm_rand_send宏、uvm_create宏,其第一个参数是SEQ_OR_ITEM的都可以是sequence的指针
1 | |
嵌套的好处:
如果不嵌套,在不同seq中一个一个写同样约束的transaction会显得特别麻烦。产生的两种不同的包中,第一个约束条件有两个,第二个约束条件有三个。但是假如约束条件有十个呢?如果整个验证平台中有30个测试用例都用到这样的两种包,那就要在这30个测试用例的sequence中加入这些代码,这是一件相当恐怖的事情,而且特别容易出错
6.4.2 在sequence中使用rand类型变量
介绍:
不仅在transaction中可以使用rand对变量进行修饰,在sequence中也可以。
sequence与transaction都可以调用randomize进行随机化,都可以有rand修饰符的成员变量,从某种程度上来说,二者的界限比较模糊
注意,不要相同命名!:
sequence与transaction中定义的rand变量名称需要注意,在约束中编译器会优先寻找transaction中的变量,若rand变量名称相同则会忽略掉seq中的变量,即出现下面的情况
1 | |
6.4.3 transaction类型匹配
相同类型匹配:
一个sequencer只能产生一种类型的transaction,一个sequence如果要想在此sequencer上启动,那么其所产生的transaction的类型 必须是这种transaction或者派生自这种transaction。
如果一个sequence中产生的transaction的类型不是此种transaction,那么将会报错:
1 | |
使用父类参数实现启动不同类型的transaction
有没有办法将两个截然不同的transaction交给同一个sequencer呢?
可以,只是需要将sequencer和driver能够接受的数据类型设置为uvm_sequence_item(即自定义transaction的父类)
具体步骤:
- sequence
- 类型内部定义不同的transaction,并在body中调用uvm系列宏启动
- sequencer
- 更改类型定义参数:
class my_sequencer extends uvm_sequencer #(uvm_sequence_item);
- 更改类型定义参数:
- driver
- 更改类型定义参数:
class my_driver extends uvm_driver#(uvm_sequence_item); - 如果要使用子类transaction的变量或方法需要调用
$cast进行强制类型转换
- 更改类型定义参数:
6.4.4 m_sequencer和p_sequencer
1.回顾m_sequencer
m_sequencer是每个sequence中都有的默认成员变量- 用途:作为
`uvm_do系列宏的默认sequencer(详情参考6.3.1)、seq.start(m_sequencer)手动启动(代码6-46),等在sequence中的uvm框架函数使用到的sequencer指针 - 类型是
uvm_sequencer_base类型(注意该指针是uvm_sequencer_base类型,即父类指针) - sequencer启动该sequence时,
m_sequencer会被赋值为启动的sequencer
2.p_sequencer
p_sequencer需要使用宏`uvm_declare_p_sequencer(自定义的sequencer类)声明,该宏等同于自定义的sequencer类p_sequencer;- 用途:通过该变量使得sequence可以引用sequencer中的变量
- 类型为调用宏时声明的自定义sequencer类(注意该指针是子类指针)
- UVM会自动将
m_sequencer通过cast转换成p_sequencer
3.p_sequencer解决的问题
简化了操作:如果在my_sequencer中设置了某些参数,在my_sequence中通过句柄m_sequence参数访问的时候由于是父类句柄无法访问到,这时可通过p_sequencer进行访问
6.4.5 sequence的派生
1.sequence的派生
sequence作为一个类,是可以从其中派生其他sequence的:
1 | |
2.补充p_sequencer情况
- 父类sequence中使用宏声明的
p_sequencer在子类中依然可以使用,无需在子类中在此调用宏声明 - 若子类在此调用宏声明,则和正常声明变量一样,产生子类父类两个
p_sequencer变量
6.5 virtual sequence的使用
virtual sequence与virtual sequencer
virtual sequence就是控制其他sequence的sequence,不发送transaction起到统一调度作用,定义方式和普通sequence一样,就是功能不一样。在virtual sequence中也可启动其他的virtual sequence。
virtual sequencer为了使用virtual sequence,一般需要一个virtual sequencer。virtual sequencer里面包含指向其他真实sequencer的指针,从而保证了在default_sequence为该vsqr的情况下,vseq可以通过该vsqr引用刀不同的sqr
sequencer对比
| virtual sequencer | sequence | |
|---|---|---|
| 实例化位置 | base_test(uvm_test) | agent |
| 路径对比 | uvm_test_top.v_sqr | uvm_test_top.env0.i_agt.sqr |
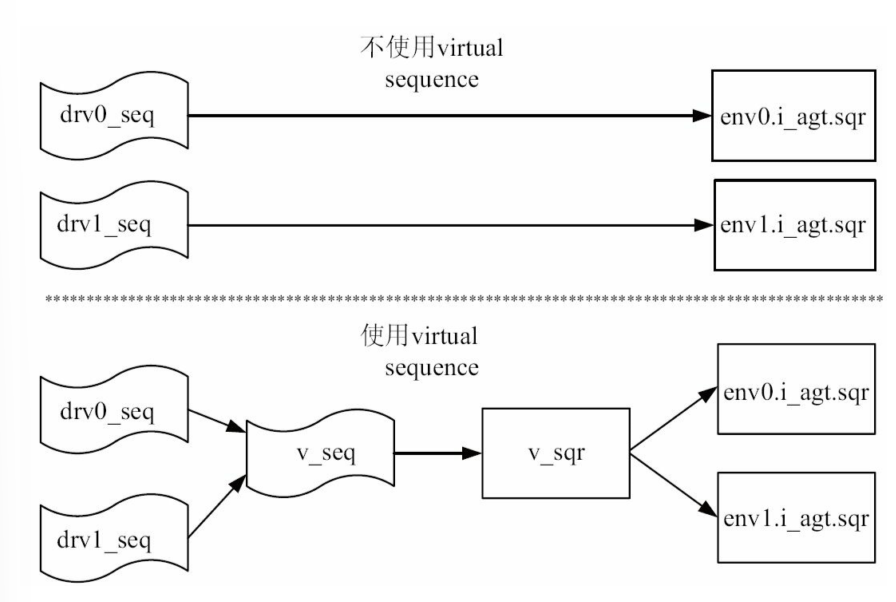
6.5.1 带双路输入输出端口的DUT
在2.2.1节所示的DUT的基础上增加了一组数据口,这组新的数据口与原先的数据口功能完全一样,具体实现分为这几步:
- 在
base_test中添加一个env, - 在
top_tb模块中添加一组interface,并使用config_db与新env中的组件进行连接 - 在
casen中添加针对该env中的sequencer的default_sequence - 其中
base_test是uvm_test的子类,casen是base_test的子类,top_tb是DUT与interface的例化模块
代码如下:
1 | |
6.5.2 sequence之间的简单同步
问题背景:基于6.5.1的验证平台
实现:DUT要求driver0必须先发送一个最大长度的包,在此基础上driver1才可以发送包,如何进行sequence的同步?
两种解决方案:
①使用全局变量(不建议使用全局变量)(本节介绍的方案)
②使用virtual sequence进行不同sequence的控制(下一节介绍的方案)
方案①的问题:
- 应该尽量避免全局变量的使用
send_over,以防在其他地方错误的使用同名变量 - 只是实现了一次同步,如果有多次同步则实现非常笨拙
方案②的好处
- 解决了方案①带来的问题
- 不用刻意地同步,体现调度功能强大
- 只需要使用一个default_sequence,减少
config_db语句的使用,减少出错概率(假如验证平台中的sequencer有多个,如10个,那么就需要写10个uvm_config_db语句,这是一件很令人厌烦的事情。使用virtual sequence后可以将这10句只压缩成一句)
方案①
1 | |
drv1_seq要等待send_over事件的到来,所以它并不会马上产生transaction
drv0_seq则会直接产生transaction。当drv0_seq发送完一个最长包后,send_over事件被触发,于drv1_seq开始产生 transaction
6.5.3 sequence之间的复杂同步
实现sequence之间同步的最好的方式就是使用virtual sequence,它不发送transaction,只是控制其他的sequence,起统一调度的作用
如图所示,为了使用virtual sequence,一般需要一个virtual sequencer。virtual sequencer里面包含指向其他真实sequencer的指针
实现步骤:
- 定义一个vsqr类
my_vsqr,内部声明两个sqr指针 - 在
base_test类中,工厂模式创建vsqr以及env(env内部agent组件创建了sqr),并将两个sqr赋值给vsqr中的sqr的指针 - 在vseq中实现控制逻辑
- 使用
`uvm_do_on系列宏指定sqr来发送transaction。或者使用手动启动sequence,手动启动优势是可以向seq传递一些值
- 使用
`uvm_do_on启动如下:
1 | |
my_case0.sv包括:seq1、seq2、vseq
手动启动如下
- (补充)解决问题:在
read_file_seq中,需要一个字符串的文件名字,在手工启动时可以指定文件名字,但是uvm_do系列宏无法实现这个功能, 因为string类型变量前不能使用rand修饰符。这就是手工启动sequence的优势
1 | |
6.5.4 仅在virtual sequence中控制objection
5.2.3节中提过要么在scoreboard中控制objection,要么在sequence中控制
当virtual sequence存在时,尤其是virtual sequence中又可以启动其他的virtual sequence时,有三个地方可以控制objection:一是普通的sequence、二是中间层的virtual sequence(如代码清单6-76中的cfg_vseq)、三是最顶层的virtual sequence(代码清单6-76中的case0_vseq)。一般来说,只在最顶层的virtual sequence中控制objection
回顾:如何在seq中控制seq
调用starting_phase.raise_objection(this);与starting_phase.drop_objection(this)
starting_phase哪来的?
uvm_sequence内部变量- 赋值位置:
- default_sequence时自动产生
- 手动启动seq时赋值
seq0.starting_phase = phase;
6.5.5 在sequence中慎用fork join_none
问题背景:将6.5.1节中的DUT的数据口扩展为4路,那么相应的验证平台中也要有4个完全相同的driver、sequencer
对于四个seq在vseq的启动有以下种写法:
①使用在for循环中使用fork join_none开个线程(错误用法)
②增加wait fork来改进方案①
③直接fork join手动写四个线程
第一种写法(错误写法):
1 | |
6.6 在sequence中使用config_db
config_db机制也对sequence机制提供了支持,可以在sequence中获取或设置参数
6.6.1 在sequence中获取参数
sequence是一个uvm_object,可以通过在sequence调用get_full_name函数获取位置,本节示例的调用结果为:uvm_test_top.env.i_agt.sqr.case0_sequence
代码示例:
set代码
1 | |
set函数的第二个路径参数里面出现了通配符
*,这是因为sequence在实例化时名字一般是不固定的,而且有时是未知的(比如 使用default_sequence启动的sequence的名字就是未知的),所以使用通配符
sequence的get代码
1 | |
在get函数原型中,第一个参数必须是一个component,而sequence不是一个component, 所以这里不能使用this指针,只能使用null或者
uvm_root::get()(前文已经提过,当使用null时,UVM会自动将其替换为uvm_root::get()再加上第二个参数
get_full_name(),就可以完整地得到此sequence的路径,从而得到参数
6.6.2 在sequence中设置参数
sequence的set代码
向scoreboard中传递了一个cmp_en参数
1 | |
也可以向sequence中传递参数,下面例子是sequence向自己传了一个first_start参数:
1 | |
在sequence中启动sequence带来的路径不同:
可以看到上面set的例子中直接使用了"uvm_test_top.v_sqr.*"路径,这是因为我们要设置的sequence是由该virtual sequence启动的,而不是像之前一样通过default_sequence由sqr启动的(这种路径会是"uvm_test_top.env0.i_agt.sqr.*"
6.6.3 wait_modified的使用
问题背景:为了解决使用config_db时,设置参数时间不确定问题
解决方法:wait_modified任务
任务原型:
1 | |
- 参数与
config_db::get前三个参数使用方法一致 wait_modified检测到第三个参数的值被更新过后返回,否则一直等待在那里- 与
config_db::get类似,可在sequence中调用
使用示例:
1 | |
wait_modified与main_phase中的其他进程在同一时刻被fork起来,当检测到参数值被设置后,立刻调用 config_db::get得到新的参数。其他进程可以根据新的参数值决定后续的比对策略。
6.7 response的使用
sequence机制提供了一种sequence→sequencer→driver的单向数据传输机制
但是在复杂的验证平台中,sequence需要根据 driver对transaction的反应来决定接下来要发送的transaction,换言之,sequence需要得到driver的一个反馈
sequence机制使用response来支持这种反馈(这种反馈只能在driver、sequencer、sequence之间,即sequence机制支持的组件)
6.7.1 put_response与get_response
如何实现sequence收到response:
方法一:使用response机制
- sequence中调用
get_response - driver中
- 设置rsp的id:调用
set_id_info函数(只有设置了rsp的id等信息,sequencer才知道将response返回给哪个sequence) - 发送response:调用
put_response任务,或者直接将rsp作为item_done函数的参数(只在只有一个response的情况下可以作为item_done的参数,详情见下一节)
- 设置rsp的id:调用
方案二:使用另类的response
- sequence中使用
`uvm_do系列宏(即seq的基本操作) - driver中直接对req进行赋值(把req看作rsp)
方案一与方案二的不同:
put_response、get_response或者response_handler,都是新建了一个transaction,并将其返回给sequence事实上,当一个
`uvm_do语 句执行完毕后,其第一个参数并不是一个空指针,而是指向刚刚被送给driver的transaction。利用这一点,可以实现一种另类的response补充:rsp与req是哪里来的?
方案一代码示例
sequence中获取rsp
1 | |
driver中设置id与发送rsp:
1 | |
driver中直接将response作为item_done参数:
1 | |
方案二代码示例
sequence正常发送transaction
1 | |
driver中对req相应字段赋值,写入响应
1 | |
6.7.2 response的数量问题
UVM支持一个transaction对应多个response的情况(但通常是一对一)
实现方式:在sequence中需要多次调用get_response,而在driver中多次调用put_response
重要特性:
- 当存在多个response时,将response作为
item_done()参数的方式就不适用了。由于一个transaction只能对应一个item_done(),所以多次调用item_done(rsp)是会出错的 - response机制的原理是driver将rsp推送给sequencer,sequencer内部维持一个队列,这个队列默认大小为8,如果溢出UVM会报错
使用示例:
1 | |
1 | |
6.7.3 response handler
问题背景:
- 在sequence中启动
get_response时,进程就会阻塞在那里,一直到response_queue中被放入新的记录 - sequence中发送
transaction与get_response是在同一个进程中执行的,get_response阻塞会导致无法发送transaction
解决方法:重定义response handle,实现sequence中发送transaction与get_response功能分离
具体步骤:
- 调用
use_response_handler()函数,打开sequence的response handler功能(默认关闭) - 需要重载虚函数
response_handler(uvm_sequence_item response); - 在
response_handle中$cast强制转换入参response为该sequence类的RSP类型
代码实现
1 | |
6.7.4 REQ与RSP
req变量来自哪里?:sequencer与driver的内部变量,可以直接使用
回顾UVM中uvm_driver、uvm_sequence、uvm_sequencer类型声明
1 | |
本书自定义my_driver、my_sequence、my_sequencer等类中使用一个参数即my_transaction,表示该子类的RSP、REQ泛型均为my_transaction
同时REQ与RSQ两种类型也可以不同
使用如下几种方式产生的子类REQ与RSQ不同,也可以使用response handler,这与req及rsp类型相同时完全一样
1 | |
6.8 sequence library
6.8.1 sequence library基础
sequence library,就是一系列sequence的集合。sequence_library类的原型为:
1 | |
由上述代码可以看出sequence library派生自uvm_sequence,从本质上说它是一个sequence
作用:sequence library根据特定的算法(详见6.8.2)随机选择注册其中的一些sequence,并在body中执行这些sequence
使用步骤:
自定义一个sequence library
- 自定义一个
uvm_sequence_library子类,REQ与RSQ参数与定义sequence相同 - 在该子类的
new函数中要调用init_sequence_library,否则其内部的候选sequence队列就是空的 - 在该子类中调用宏
`uvm_sequence_library_utils进行注册
- 自定义一个
将某个sequence添加到sequence library中
- 一个sequence在定义时使用宏
`uvm_add_to_seq_lib来将其加入某个sequence library中,下面两条是该宏的补充说明uvm_add_to_seq_lib有两个参数,第一个是此sequence的名字,第二个是要加入的sequence library的名字- 一个sequence可以加入多个不同的sequence library中
- 一个sequence在定义时使用宏
- sequence与sequence library定义好后,可以将sequence library作为sequencer的default sequence
代码示例:
自定义一个sequence library
1 | |
将某个sequence添加到sequence library中
1 | |
将sequence library作为sequencer的default sequence
1 | |
6.8.2 控制选择算法
selection_mode变量
sequence library中的变量selection_mode决定sequence library从其sequence队列中选择的模式,默认为UVM_SEQ_LIB_RAND
selection_mode原型为:
1 | |
其中uvm_sequence_lib_mode为一个枚举类型:
1 | |
如何设置selection_mode
使用config_db::set机制,示例如下:
1 | |
如何自定义算法
假设有4个sequence加入了sequence library中:seq0、seq1、seq2和seq3。
现在由于各种原因,不想使用seq2了。上述代码的
select_sequence第一次被调用时初始化index队列,把seq0、seq1和seq3在sequences中的索引号存入其中。之后,从index中随机选择一个值返回,相当于是从seq0、seq1和seq3随机选一个执行。sequences是sequence library中存放候选sequence的队列。
select_sequence会传入一个参数max,select_sequence函数必须返回一个介于0到max之间的数值。如果sequences队列的大小为4,那么传入的max的数值是3,而不是4
1 | |
1 | |
6.8.3 控制执行次数
min_random_count与max_random_count
sequence library内部的两个变量控制生成sequence次数,默认都为10,变量定义原型如下:
1 | |
- sequence library会在
min_random_count和max_random_count之间随意选择一个数来作为执行次数。这里只能选择10 - 当
selection_mode为UVM_SEQ_LIB_ITEM时,将会产生10个item;为其他模式时,将会顺序启动10个sequence。可以设置这两个值为其他值来改变迭代次数
如何设置min_random_count与max_random_count**
1 | |
上述设置将会产生最多20个,最少5个transaction
6.8.4 设置sequence library的简便方案
问题背景:前几节使用3个config_db设置迭代次数和选择算法稍显麻烦
两种解决方案:
方案①:使用UVM提供了一个类uvm_sequence_library_cfg来对 sequence library进行配置
- 声明一个
uvm_sequence_library_cfg类的对象 - 调用该对象的构造函数
new,并配置相应形参 - 使用
config_db::set设置default_sequence.config与default_sequence
方案②:使用6.1.2中的方法3启动sequence,步骤如下:
- 手动实例化seq
- 配置参数
- 使用
config_db::set设置default_sequence
代码示例
方案①
1 | |
方案②
1 | |
2023年1月17日 18:36:58
第七章 UVM中的寄存器模型
任何系统设计通常都面临两大挑战:缩小技术节点的尺寸和 TTM(上市时间)。为了应对竞争激烈的市场格局的速度,大多数系统都以通用方式设计——这意味着相同的设计可以以不同的方式用于不同的配置。配置的数量越多,设计中的寄存器数量就越多。最重要的是,由于当前市场对数据存储的高需求,内存容量也越来越大。要访问和验证大量的寄存器和巨大的内存,需要一些创新的方法。
因此,UVM提供了一个用于寄存器管理及其访问的基类库,称为UVM RAL(Register Abstraction Layer)。
UVM RAL 顾名思义,是一个高级的面向对象的抽象层,用于访问设计寄存器。RAL模型模仿设计寄存器,整个模型是完全可配置的。由于其抽象行为,RAL 模型可以很容易地从块级迁移到系统级
https://www.design-reuse.com/articles/46675/uvm-ral-model-usage-and-application.html
7.1 寄存器模型简介
问题背景:
- 在本书以前所有的例子中,DUT为最简单的DUT,只有数据端口,没有行为控制口,这样的DUT几乎是没有任何价值的
- DUT一般都会有一组控制端口,用来配置DUT中的寄存器,DUT可以根据寄存器的值来改变行为(可以参考代码清单中B-2的DUT实现)
操作指南:
- read
- mirror:7.7.2
- set:7.5.1
- update:7.5.1
- write:7.5.1
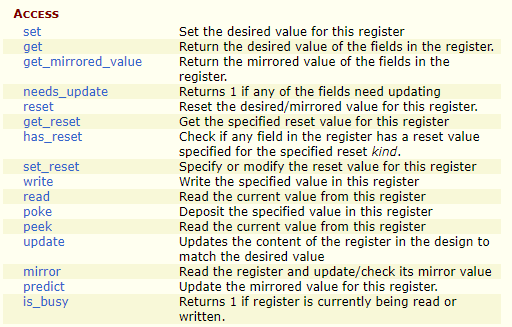
7.1.1 带寄存器配置总线的DUT
B-2中DUT介绍:
该DUT接口如下:
1 | |
该DUT仅具有一个1bit的控制寄存器invert,其地址为16'h9,用于实现以下功能:
invert值为1,那么DUT在输出时会将输入的数据取反invert值为0,那么DUT在输出时会将输入数据直接发送出去
验证平台框图:
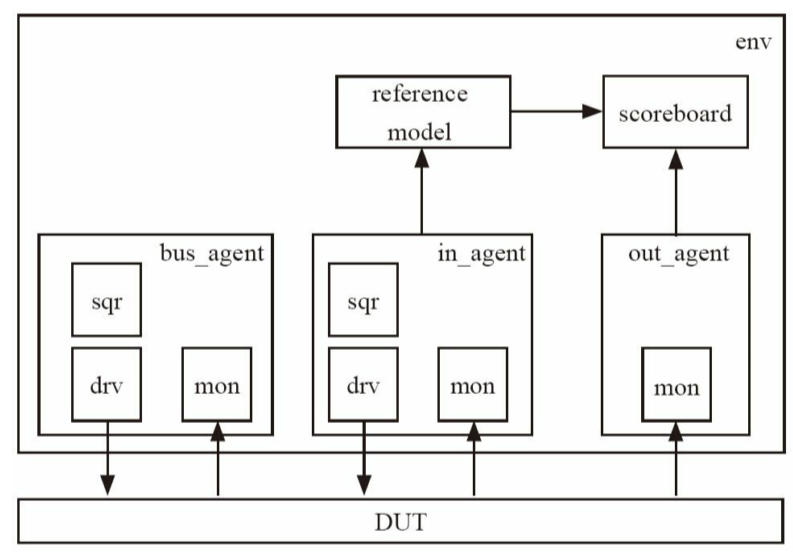
验证平台相关重点代码:
有如下的transaction定义:
1 | |
有如下的driver定义:
1 | |
1 | |
7.1.2 概述
问题背景:如何在参考模型中读取DUT中一个寄存器的值呢?
没有寄存器模型的情况下:我们只能先通过使用bus_driver向总线上发送读指令,并给出要读的寄存器地址来查看一个寄存器的值。要实现这个过程,需要启动一个sequence,这个sequence会发送一个transaction给bus_driver,这会带来两个问题:
- 第一个问题是,如何在参考模型的控制下来启动一个sequence以读取寄存器
- 第二个问题是,sequence读取的寄存器的值如何传递给参考模型
解决第一个问题有两种方法:
- 方法1:一个简单的想法是设置一个全局事件,然后在参考模型中触发这个事件。在virtual sequence中等待这个事件的到来,等到了,则启动sequence(全局变量,非常不好!)
- 方法2:用一个非全局事件来代替。利用config机制分别为
virtual sequencer和scoreboard设置一个config_object,在此object中设置一个事件,如rd_reg_event,然后在scoreboard中触发这个事件,而在virtual sequence中则要等待这个事件的到来(代码可以是@p_sequencer.config_object.rd_reg_event;),这个事件等到后就启动一个sequence,开始读寄存器 - 方法3:详见7.3.1
解决第二个问题:当sequence读取到寄存器后,可以再通过6.6.2节所示的config_db传递给参考模型,在参考模型中使用6.6.3 节所示的wait_modified来更新数据
可以看到看出这个过程相当麻烦,如果有了寄存器模型,只要一条语句就可以实现上述复杂的过程。像启动sequence及将读取结果返回这些事情,都会由寄存器模型来自动完成。这个过程就可以简化为:
1 | |
下图指出了读取寄存器的过程,其中左图为不使用寄存器模型,右图为使用寄存器模型的读取方式
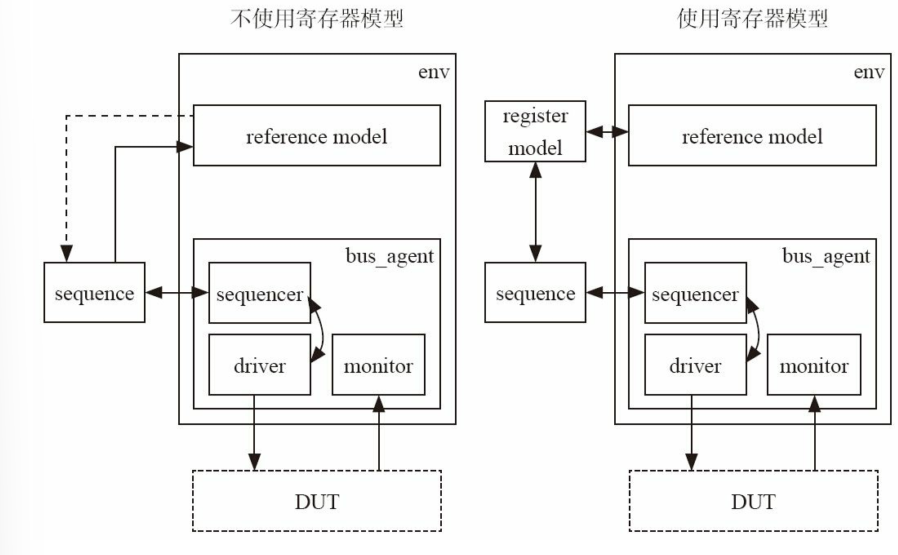
后门与前门的使用,以及寄存器模型的优势
在没有寄存器模型之前,验证平台内模块只能启动sequence通过前门(FRONTDOOR)访问的方式来读取寄存器
有了寄存器模型之后,验证平台内模块只与寄存器模型打交道,无论是发送读的指令还是获取读操作的返回值,都可以由寄存器模型完成
有了寄存器模型后,可以在任何耗费时间的phase中使用寄存器模型以前门访问或后门(BACKDOOR)访问的方式来读取寄存器的值
有了寄存器模型后,还能在某些不耗费时间的phase(如check_phase)中使用后门访问的方式来读取寄存器的值
前门访问与后门访问:是两种寄存器的访问方式,关于前门访问与后门访问的问题,将会在7.3节中详细说明
前门访问:
- 概念:指的是通过模拟cpu在总线上发出读指令,进行读写操作。在这个过程中,仿真时间(
$time函数得到的时间)是一直往前走的 - 前门访问的工作流程:7.2.2
后门访问:是与前门访问相对的概念。它并不通过总线进行读写操作,而是直接通过层次化的引用来改变寄存器的值
UVM寄存器模型的本质就是重新定义了验证平台与DUT的寄存器接口,使验证人员更好地组织及配置寄存器,简化流程、减少工作量
前门访问(FRONTDOOR):启动sequence产生待操作寄存器的读写控制和地址,在driver中通过总线(Bus)驱动至DUT,并在monitor中采集Bus输出数据,该方式需要消耗仿真时间 ;
后门访问(BACKDOOR):在仿真环境中通过DUT实例名进行点操作,直接访问DUT内部的寄存器,该方式的缺点是,点操作需要通过绝对路径操作,如果寄存器数量庞大,会导致验证环境臃肿繁杂,容易出错如下图所示,RAL Model中包含MEM和 block,它们分别用于对 DUT 中的寄存器和memory进行建模,其行为和硬件行为保持一致(其实是尽可能保持一致),ADDR MAP用于实现访问寄存器的相对地址和绝对地址的转换
寄存器模型注意有以下优势:
a.方便对 DUT 中寄存器进行读写;
b.在软件仿真时,可以不耗时的获取寄存器的值(直接从 RAL Model 中获取);
c.可以很方便的正对寄存器的coverage验证点的收集来源:https://www.cnblogs.com/dreamCll/p/11756898.html
我的理解
RAL model是验证平台用于获取DUT内部寄存器状态的一个桥梁,通过调用RAL model的
read/write函数(前门/后门访问)或peek/poke(后门访问),可以很轻松以不同方式实现验证平台对DUT内部寄存器的读写而具体实现DUT内部寄存器读写的总线操作,是通过bus_agent进行的
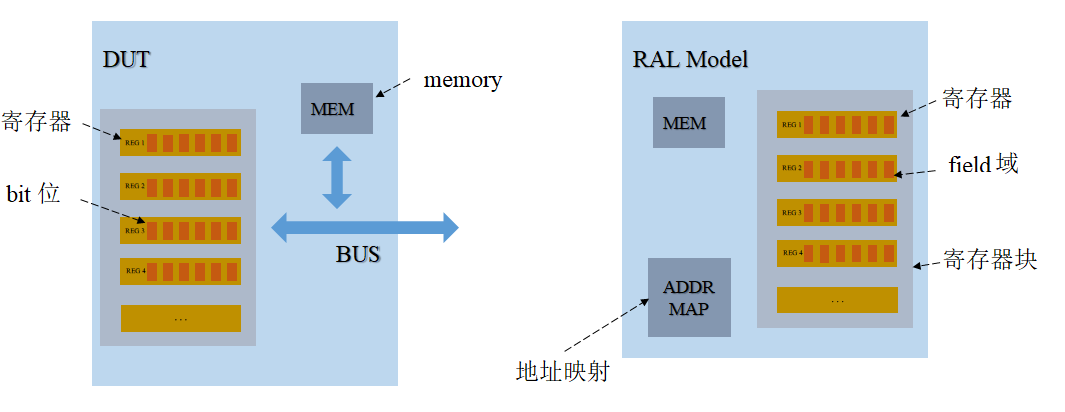
7.1.3 寄存器模型中的基本概念
uvm_reg_field:寄存器域,这是寄存器模型中的最小单位uvm_reg:寄存器,一个比较小的单位,比uvm_reg_field高一个级别。一个uvm_reg中至少包含一个uvm_reg_fielduvm_reg_block:寄存器块,一个比较大的单位,在其中可以加入许多的uvm_reg,也可加其他的uvm_reg_block。一个寄存器模型中至少包含一个uvm_reg_blockuvm_reg_map:寄存器地址映射,每个寄存器在加入寄存器模型时都有其地址,uvm_reg_map就是存储这些地址,并将其转换成可以访问的物理 地址(因为加入寄存器模型中的寄存器地址一般都是偏移地址,而不是绝对地址)。当寄存器模型使用前门访问方式来实现读或写操作时,uvm_reg_map就会将地址转换成绝对地址,启动一个读或写的sequence,并将读或写的结果返回。在每个uvm_reg_block内部,至少有一个(通常也只有一个)uvm_reg_map
uvm_reg与uvm_reg_field对比:
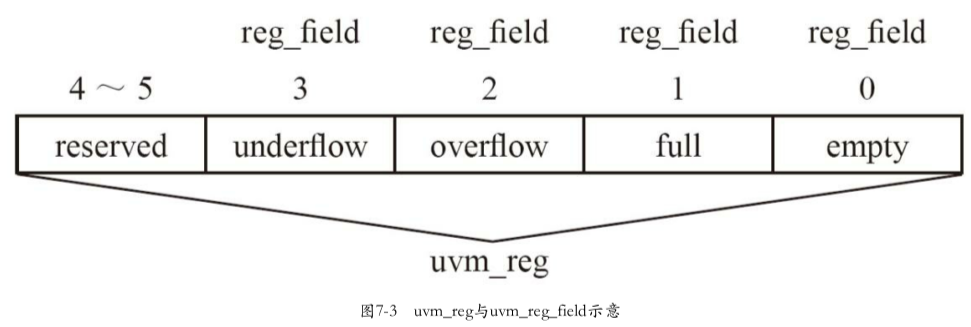
如上的状态寄存器共有四个域,分别是empty、full、overflow、underflow。这四个域对应寄存器模型中的uvm_reg_field。名字 为“reserved”的并不是一个域
我的理解:(多个域的寄存器配置方法略有不同)
field,寄存器内的域
- 不用自定义,需要在reg中例化并配置
reg,寄存器
- 需要自定义
- 在
new函数中向super.new传递寄存器基本信息,如位宽等- 内部需要对不同field例化并配置
block,多个寄存器组成的块
- 需要自定义
- 在
new函数中调用super.new- 内部需要对所有reg例化并配置,configure参数3设置为路径字符串用作后门访问地址,同时调用reg.build函数配置field
- 内部需要对内部成员default_map进行例化与配置
- 将所有reg添加到default_map中
- 一般在base_test中例化,一般会实现两级结构(见7.4.1)
- (可选)reg_file实例化并配置,修改reg的configure参数3为该reg_file指针
map,地址映射
- 不用自定义
base_test
- adapter相关
- 声明,例化adapter
- 将adpater与bus_sequencer告知reg model中的default_map
reg model相关(7.2.2)
- 声明、例化block(这个就是reg model)、配置reg model以及后门访问路径(一般不用设置,可以在reg的配置里设置)、build其内部所有reg,锁定reg model、复位reg model
- 将reg model中的default_map设置为自动预测状态
- 将reg model指针传递给env,env再传递给其他组件
后门访问
- 需要设置根路径
rm.set_hdl_path_root("top_tb.my_dut");reg_file
mem
7.2 简单的寄存器模型
7.2.1 只有一个寄存器的寄存器模型
考虑之前只存在一个寄存器invert的DUT,为其建造寄存器模型,主要有以下几步:
- 定义一个
uvm_reg的派生类(reg定义)- 在其
new函数中向super.new传递寄存器基本信息 - 在其
build函数内实例化所有uvm_reg_field对象,并调用configure函数配置(field实例化)
- 在其
- 定义一个
uvm_reg_block派生类(block定义)- 在其
build函数内实现所有uvm_reg对象的实例化,并调用其configure与build函数,完成配置与构建(reg实例化) - 在其
build函数内,使用内部变量default_map创建并参数配置一个uvm_reg_map,将上面实例化的reg加入该map中(map实例化)
- 在其
补充:一个uvm_reg_block中一定要对应一个uvm_reg_map
分步分析
1、定义一个uvm_reg的派生类
1 | |
new构造方法
在new函数中,要调用
super.new函数,该函数有三个参数:
- 参数1:
- 参数2:该寄存器的位数(如对于一个16位的寄存器,其中可能只使用了8位,那么这里要填写的是16,而不是8。这个数字一般与系统总线的宽度一致)
- 参数3:该寄存器是否要加入覆盖率的支持,是为
UVM_COVERAGE,否为UVM_NO_COVERAGEbuild方法
每一个派生自
uvm_reg的类都有一个build,这个build与uvm_component的build_phase并不一样,它不会自动执行,而需要手工调用,与build_phase相似的是所有的uvm_reg_field都在这里实例化配置字段
当
uvm_reg_field(reg_data)实例化后,要调用uvm_reg_field.configure(reg_data.configure)函数来配置这个字段
configure:
- 第一个参数就是此域(
uvm_reg_field)的父辈,也即此域位于哪个uvm_reg中,这里当然是填写this- 第二个参数是此域的宽度,由于DUT中invert的宽度为1,所以这里为1
- 第三个参数是此域的最低位在整个寄存器中的位置,从0开始计数
假如一个寄存器如图所示,其低3位和高5位没有使用,其中只有一个字段,此字段的有效宽度为8位,那么在调用configure时,第二个参数就要填写8,第三个参数则要填写3,因为此
uvm_reg_field是从第4位开始的
- 第四个参数表示此字段的存取方式。UVM共支持如下25种存取方式(事实上,寄存器的种类多种多样,25种存取方式有时并不能满足用户的需求,这时就需要自定义寄存器的模型):
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
251)RO:读写此域都无影响
2)RW:会尽量写入,读取时对此域无影响
3)RC:写入时无影响,读取时会清零
4)RS:写入时无影响,读取时会设置所有的位
5)WRC:尽量写入,读取时会清零
6)WRS:尽量写入,读取时会设置所有的位
7)WC:写入时会清零,读取时无影响
8)WS:写入时会设置所有的位,读取时无影响
9)WSRC:写入时会设置所有的位,读取时会清零
10)WCRS:写入时会清零,读取时会设置所有的位
11)W1C:写1清零,写0时无影响,读取时无影响
12)W1S:写1设置所有的位,写0时无影响,读取时无影响
13)W1T:写1入时会翻转,写0时无影响,读取时无影响
14)W0C:写0清零,写1时无影响,读取时无影响
15)W0S:写0设置所有的位,写1时无影响,读取时无影响
16)W0T:写0入时会翻转,写1时无影响,读取时无影响
17)W1SRC:写1设置所有的位,写0时无影响,读清零
18)W1CRS:写1清零,写0时无影响,读设置所有位
19)W0SRC:写0设置所有的位,写1时无影响,读清零
20)W0CRS:写0清零,写1时无影响,读设置所有位
21)WO:尽可能写入,读取时会出错
22)WOC:写入时清零,读取时出错
23)WOS:写入时设置所有位,读取时会出错
24)W1:在复位(reset)后,第一次会尽量写入,其他写入无影响,读取时无影响
25)WO1:在复位后,第一次会尽量写入,其他的写入无影响,读取时会出错
- 第五个参数表示是否是易失的(
volatile),这个参数一般不会使用- 第六个参数表示此域上电复位后的默认值。
- 第七个参数表示此域是否有复位,一般的寄存器或者寄存器的域都有上电复位值,因此这里一般也填写
1- 第八个参数表示这个域是否可以随机化。这主要用于对寄存器进行随机写测试,如果选择了0,那么此域将不会随机化,而一直是复位值,否则将会随机出一个数值来。这一个参数当且仅当第四个参数为RW、WRC、WRS、WO、W1、WO1时才有效
- 第九个参数表示这个域是否可以单独存取
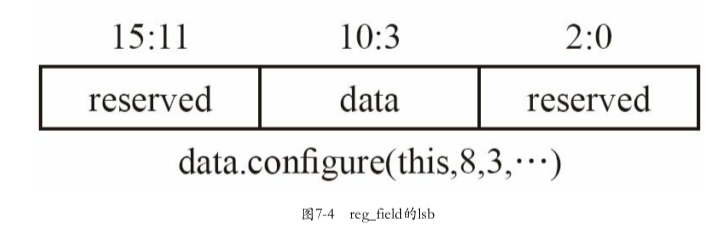
2、定义一个uvm_reg_block派生类
1 | |
new构造方法
在new函数中,要调用
super.new函数build方法
每一个由
uvm_reg_block派生的类也要定义一个build函数,一般在此函数中实现所有寄存器的实例化步骤:
- 实例化
uvm_map:调用create_map函数,为内部成员default_map实例化一个
uvm_reg_block中一定要对应一个uvm_reg_map,系统已经有一个声明好的default_map,只需要在build中将其实例化
default_map的过程并不是直接调用uvm_reg_map的new函数,而是通过调用uvm_reg_block的create_map来实现
create_map参数:
- 第一个参数是名字
- 第二个参数是基地址
- 第三个参数则是系统总线的宽度,这里的单位是byte而不是bit
- 第四个参数是大小端
- 最后一个参数表示是否能够按照byte寻址
- 实例化所有
uvm_reg:使用工厂方法,实例化之前定义的uvm_reg衍生类- 配置
uvm_reg的实例:调用之前实例化的uvm_reg变量的configure函数
configure函数:这个函数的主要功能是指定寄存器进行后门访问路径
configure参数:
- 第一个参数是此寄存器所在uvm_reg_block的指针,这里填写this
- 第二个参数是reg_file的指针(7.4.2节将会介绍reg_file的概念)这里暂时填写null
- 第三个参数是此寄存器的后门访问路径,关于这点请参考7.3节,这里暂且为空
- 实例化
uvm_field:当调用完configure时,需要手动调用uvm_reg变量的build函数,将该寄存器中的域实例化- 将
uvm_reg变量加入default_map中:调用add_reg函数
uvm_reg_map的作用是存储所有寄存器的地址,因此必须将实例化的寄存器加入default_map中,否则无法进行前门访问操作
add_reg函数参数:
- 第一个参数是要加入的寄存器
- 第二个参数是寄存器的地址
- 第三个参数是此寄存器的存取方式
7.2.2 寄存器模型集成
前门访问方式工作流程:
寄存器模型的前门访问方式工作流程如图所示,其中图a为读操作,图b为写操作
寄存器模型的前门访问操作可以分成读和写两种,步骤如下:
- 无论是读或写,RAL model在调用
read/write函数时都会通过启动一个sequence(用户不可见) 产生一个uvm_reg_bus_op的变量,此变量中存储着操作类型(读还是写),操作的地址,如果是写操作,还会有要写入的数据
此变量中存储着操作类型(读还是写)和操作的地址
如果是写操作,还会有要写入的数据
此变量中的信息要经过一个转换器(
adapter)转换之后,交给bus_sequencer随后
bus_sequencer交给bus_driver,由bus_driver实现最终的前门访问读写操作
因此,必须要定义好一个转换器
寄存器模型的前门访问操作最终都将由
uvm_reg_map完成
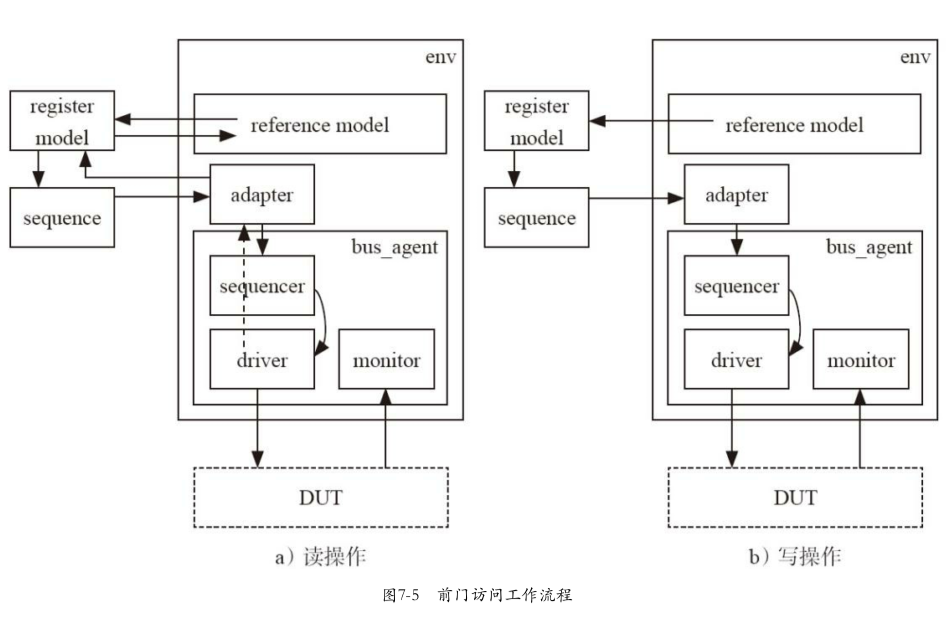
一个简单的转换器的代码:
1 | |
转换器实现步骤:一个转换器要定义好两个函数
reg2bus、bus2reg
reg2bus,其作用为将寄存器模型通过sequence发出的uvm_reg_bus_op型的变量转换成bus_sequencer能够接受的形式bus2reg,其作用为当监测到总线上有操作时,它将收集来的transaction转换成寄存器模型能够接受的形式,以便寄存器模型能够更新相应的寄存器的值
补充:读操作细节、虚线解释
说到这里,不得不考虑寄存器模型发起的读操作的数值是如何返回给寄存器模型的?(如果你搞不懂为什么这里是寄存器模型读操作返回给寄存器模型,请参考7.1.2我的理解内容)
- 由于总线的特殊性,
bus_driver在驱动总线进行读操作时,它也能顺便获取要读的数值 - 如果它将此值放入从
bus_sequencer获得的bus_transaction中时,那么bus_transaction中就会有读取的值 - 此值经过
adapter的bus2reg函数的传递,最终被寄存器模型获取
这个过程如图7-5a所示。由于并没有实际的transaction的传递,所以从bus_driver到adapter使用了虚线
把寄存器模型集成到bast_test中
1 | |
集成步骤:
- 至少需要在base_test中定义两个成员变量:
reg_model(这是一个uvm_reg_block的自定义衍生类)、reg_sqr_adapter(这是一个uvm_reg_adapter的自定义衍生类)build_phase:
- 所有用到的类进行实例化(
reg_model、reg_sqr_adapter…)- 对于
reg_model还要做四件事:
- 第一是调用
configure()函数,其第一个参数是parent block,由于是最顶层的reg_block,因此填写null,第二个参数是后门访问路径,请参考7.3节,这里传入一个空的字符串- 第二是调用
build()函数,将所有的寄存器实例化- 第三是调用
lock_model()函数,调用此函数后,reg_model中就不能再加入新的寄存器了- 第四是调用
reset()函数,如果不调用此函数,那么reg_model中所有寄存器的值都是0,调用此函数后,所有寄存器的值都将变为设置的复位值connect_phase:
- 将转换器和
bus_sequencer通过set_sequencer()函数告知reg_model的default_map- 通过
set_auto_predict(1)函数,将default_map设置为自动预测状态(因为寄存器模型中涉及到的前门访问操作最终都将由uvm_reg_map完成,所以需要告知default_map)
7.2.3 如何使用寄存器模型
本节基本内容
- 当一个寄存器模型被建立好后,可以在sequence和其他component中使用
- 本节以前门访问为例,介绍寄存器模型提供了两个基本的任务:
read和write,用于其他类对寄存器模型的读写
寄存器模型与transaction类型:
寄存器模型对sequence的transaction类型没有任何要求。因此,可以在一个发送my_transaction的sequence中使用寄存器模型对寄存器进行读写操作
在参考模型中读取寄存器
使用read任务:
1 | |
参考模型中获得寄存器模型的指针
以在参考模型中使用为例,需要在参考模型中有一个寄存器模型的指针:
2
3
4
5
6//src/ch7/section7.2/my_model.sv
class my_model extends uvm_component;
...
reg_model p_rm;
...
endclass这个指针的实例获取方式:
- 在
base_test实例化reg_model时传递给env,- 再由
env传递给ref_model补充
在7.8.1使用新方法
get_root_block可以在不使用指针传递的情况下得到寄存器模型的指针
read任务参数
它有多个参数,常用的是其前三个参数:
- 其中第一个是
uvm_status_e型的变量,这是一个输出,用于表明读操作是否成功- 第二个是读取的数值,也是一个输出
- 第三个是读取的方式,可选
UVM_FRONTDOOR和UVM_BACKDOOR

在virtual sequence中写入寄存器
由于参考模型一般不会写寄存器,因此对于write任务,以在virtual sequence进行写操作为例说明
1 | |
virtual sequence中获得寄存器模型的指针
这个指针的实例获取方式:
- 在
base_test(该类实例化了reg_model)的connect_phase()时把reg_model传递给v_sqr- 在sequence中使用寄存器模型,通常通过
p_sequencer的形式补充
在7.8.1使用新方法
get_root_block可以在不使用指针传递的情况下得到寄存器模型的指针
write任务参数
它的参数也有很多个,但是与read类似,常用的也只有前三个:
- 第一个为
uvm_status_e型的变量,这是一个输出,用于表明写操作是否成功- 第二个要写的值,是一个输入
- 第三个是写操作的方式,可选
UVM_FRONTDOOR和UVM_BACKDOOR
7.3 前门访问与后门访问
7.3.1 UVM中的前门访问实现
前门访问
所谓前门访问操作就是通过寄存器配置总线(如APB协议、OCP协议、I2C协议等)来对DUT进行操作
无论在任何总线协议中,前门访问操作只有两种:读操作和写操作。前门访问操作是比较正统的用法。对一块实际焊接在电路板上正常工作的芯片来说,此时若要访问其中的某些寄存器,前门访问操作是唯一的方法
本节内容:
- 不使用RAL model来实现前门访问
- 使用RAL model进行前门访问的不同(使用RAL model来实现前门访问的方法在7.2已经描述完了)
- transaction与adapter的转换实现:uvm_reg_item
- 使用RAL model进行前门访问的读操作完整流程
- 应答机制
- 使用RAL model进行前门访问的写操作完整流程
1.不使用RAL model来实现前门访问
在7.1.2节中介绍寄存器模型时曾经讲过,对于参考模型来说,最大的问题是如何在其中启动一个sequence,当时列举了全局变量和config_db的两种方式。除了这两种方式之外,如果能够在参考模型中得到一个sequencer的指针,也可以在此sequencer上启动一个sequence。这通常比较容易实现,只要在其中设置一个p_sqr的变量,并在env中将sequencer的指针赋值给此变量即可
代码实现:
一个读写的sequence:
1 | |
在参考模型中使用如下的方式来进行读操作:
1 | |
sequence是自动执行的,但是在其执行完毕后(body及post_body调用完成),为此sequence分配的内存依然是有效的,所以 可以使用
reg_seq继续引用此sequence。上述读操作正是用到了这一点
2. 使用RAL model进行前门访问的不同(使用RAL model来实现前门访问的方法在7.2已经描述完了)
对UVM来说,其在寄存器模型中使用的方式也与此类似
上述操作方式的关键是在参考模型中有一个sequencer的指针,而在寄存器模型中也有一个这样的指针,它就是7.2.2节中,在base_test的connect_phase为default map设置的sequencer指针
3.transaction与adapter的转换实现:uvm_reg_item
对于UVM来说,它是一种通用的验证方法学,所以要能够处理各种transaction类型。幸运的是,这些要处理的 transaction都非常相似,在综合了它们的特征后,UVM内建了一种transaction:uvm_reg_item。通过adapter的bus2reg及reg2bus,可以实现uvm_reg_item与目标transaction的转换
4.以读操作为例,其完整的流程为
- 参考模型调用寄存器模型的读任务
- 寄存器模型产生sequence,并产生
uvm_reg_item rw - 产生driver能够接受的transaction:
bus_req = adapter.reg2bus(rw) - 把
bus_req交给bus_sequencer - driver得到
bus_req后驱动它,得到读取的值,并将读取值放入bus_req中,调用item_done() - 寄存器模型调用
adapter.bus2reg(bus_req,rw)将bus_req中的读取值传递给rw - 将
rw中的读数据返回参考模型
5.应答机制的作用
问题背景:介绍sequence的应答机制时提到过,如果driver一直发送response而sequence不收集response,那么将会导致sequencer的应答队列溢出
解决方案:UVM考虑到这种情况,在uvm_reg_adapter中声明了一个内部成员provide_responses
1 | |
在设置了provide_responses后,寄存器模型在调用bus2reg将目标transaction转换成uvm_reg_item时,其传入的参数是rsp,而不是req,这样就不需要driver按照req一样返回rsp,从而增加sequence处理rsp
你可能好奇,这有什么用呢?简单来说driver把返回RAL model的bus_req过程替换为返回response,这样driver的reponse就相当于处理完了
使用应答机制的操作流程为:
- 参考模型调用寄存器模型的读任务
- 寄存器模型产生sequence,并产生
uvm_reg_item rw - 产生driver能够接受的
transaction bus_req = adapter.reg2bus(rw) - 将
bus_req交给bus_sequencer - driver得到
bus_req,驱动它,得到读取的值,并将读取值放入rsp中,调用item_done() - 寄存器模型调用
adapter.bus2reg(rsp,rw)将rsp中的读取值传递给rw - 将rw中的读数据返回参考模型
7.3.2 后门访问介绍
本节内容:
- 引入一个带有只读寄存器的DUT
- 后门访问操作的定义
1.引入一个带有只读寄存器的DUT
从本节开始,将在7.1.1节的DUT的基础上引入一个新的DUT,如附录B的代码清单B-3所示。这个 DUT中加入了寄存器counter,它的功能就是统计rx_dv为高电平的时钟数。同时在上述DUT中,加法器的位宽被限制在16位。要实现32位的counter的加法操作,需要使用两个叠加的16位加法器(7.4.4节将会介绍使它们作为一个寄存器的方法)
计数器的位数与加法器之间的故事
在通信系统中,有大量计数器用于统计各种包裹的数量,如超长包、长包、中包、短包、超短包等。这些计数器的一个共同 的特点是它们是只读的,DUT的总线接口无法通过前门访问操作对其进行写操作。除了是只读外,这些寄存器的位宽一般都比较 宽,如32位、48位或者64位等,它们的位宽超过了设计中对加法器宽度的上限限制。计数器在计数过程中需要使用加法器,对于加法器来说,在同等工艺下,位宽越宽则其时序越差,因此在设计中一般会规定加法器的最大位宽。在上述DUT中,加法器的位宽被限制在16位。要实现32位的counter的加法操作,需要使用两个叠加的16位加法器(7.4.4节将会介绍使它们作为一个寄存器的方法)
验证平台针对DUT更新RAL model相关内容(详情见7.3.5):
- 添加该counter到RAL model层
- 注意block中对reg的configure参数三的路径设置是否正确
- 在
bast_test添加正确的hdl路径
2.后门访问
后门访问是与前门访问相对的操作,从广义上来说,所有不通过DUT的总线而对DUT内部的寄存器或者存储器进行存取的操作都是后门访问操作。所有后门访问操作都是不消耗仿真时间(即$time打印的时间)而只消耗运行时间
后门访问示例:在top_tb中可以使用如下方式对counter赋初值
1 | |
后门访问的意义
- 后门访问操作能够更好地完成前门访问操作所做的事情:后门访问不消耗仿真时间,与前门访问操作相比,它消耗的运行时间要远小于前门访问操作的运行时间。在一个大型芯片的验证中,在其正常工作前需要配置众多的寄存器,配置时间可能要达到一个或几个小时,而如果使用后门访问操作,则时间可能缩短为原来1/100
- 后门访问操作能够完成前门访问操作不能完成的事情:如在网络通信系统中,计数器通常都是只读的(有一些会附加清零功能),无法对其指定一个非零的初值。而大部分计数器都是多个加法器的叠加,需要测试它们的进位操作。本节DUT的counter使用了两个叠加的16位加法器,需要测试当计数到32’hFFFF时能否顺利进位成为32’h1_0000,这可以通过延长仿真时间来使其 计数到32‘hFFFF,这在本节的DUT中是可以的,因为计数器每个时钟都加1。但是在实际应用中,可能要几万个或者更多的时钟才会加1,因此需要大量的运行时间,如几天。这只是32位加法器的情况,如果是48位的计数器,情况则会更坏。这种情况下,后门访问操作能够完成前门访问操作完成的事情,给只读的寄存器一个初值
后门访问相对于前门访问的劣势
与前门访问操作相比,后门访问操作也有其劣势:
如所有的前门访问操作都可以在波形文件中找到总线信号变化的波形及所有操作的记录,但是后门访问操作则无法在波形文件中找到操作痕迹。其操作记录只能仰仗验证平台编写者在进行后门访问操作时输出的打印信息,这样便增加了调试的难度
7.3.3 后门访问操作实现概述
本书第七章提到了如下几种后门访问方式:
- 绝对路径访问
- 使用接口封装绝对路径进行访问(常用)
- 使用UVM中DPI+VPI定义的函数
- UVM的RAL model(常用)
第一、第二都是使用sv特性
第三、第四方式将在下两节进行解释
1.绝对路径访问
其中方式1就是上一节中的代码,在top_tb中使用绝对路径对寄存器进行后门访问操作,这需要更改top_tb.sv文件,但是这个文件一般是固定的,不会因测试用例的不同而变化,所以这种方式的可操作性不强。在driver等组件中也可以使用这种绝对路径的方式进行后门访问操作,但强烈建议不要在driver等验证平台的组件中使用绝对路径。这种方式的可移植性不强。代码我再写一遍:
1 | |
2.使用接口封装绝对路径进行访问
如果想在driver或monitor中使用后门访问,一种方法是使用接口。可以新建一个后门interface,其中poke_counter()为后门写,而peek_counter()为后门读:
1 | |
在测试用例(或者drvier、scoreboard)中,若要对寄存器赋初值可以直接调用此函数:
1 | |
这种方法的缺点:如果有n个寄存器,那么需要写n个poke函数,同时如果有读取要求的话,还要写n个peek函数,这限制了其使用,且此文件完全没有任何移植性
这种方法的应用:这种方式在实际中是有应用的,它适用于不想使用寄存器模型提供的后门访问或者根本不想建立寄存器模型,同时又必须要对DUT中的一个寄存器或一块存储器(memory)进行后门访问操作的情况
7.3.4 UVM中后门访问操作的实现原理:DPI+VPI
VPI介绍
在实际的验证平台中,还有在C/C++代码中对DUT中的寄存器进行读写的需求
Verilog提供VPI接口,可以将DUT的层次结构开放给外部的C/C++代码,常用的VPI接口有如下两个:
1 | |
vpi_get_value()用于从RTL中得到一个寄存器的值
vpi_put_value()用于将RTL中的寄存器设置为某个值
DPI介绍
VPI的不足:如果单纯地使用VPI进行后门访问操作,在SystemVerilog与C/C++之间传递参数时将非常麻烦
为了提供更好的用户体验,SystemVerilog提供了一种更好的接口:DPI,DPI如何实现自己百度
注意:
本书介绍的后门访问,都是以SV视角,而不是C/C++,别搞混了,C/C++只是实现的中间件
在UVM中相应的DPI函数在UVM的C++源码中已经给你定义好了,你只需要在需要调用的地方声明即可,或者直接使用RAL model的特性
两个DPI函数的声明:
2import "DPI-C" context function int uvm_hdl_read(string path, output uvm_hdl_data_t value);//用于读操作
import "DPI-C" context function int uvm_hdl_deposit(string path, uvm_hdl_data_t value);//用于写操作
使用DPI+VPI实现后门访问读操作
在SystemVerilog中像普通函数一样调用uvm_hdl_read函数了。这种方式比单纯地使用VPI的方式简练许多。它可以直接将参数传递给C/C++中的相应函数,省去了单纯使用VPI时繁杂的注册系统函数的步骤
SystemVerilog中读操作的代码可以是:
1 | |
DPI+VPI的优势:路径被抽像成了一个字符串,从而可以以参数的形式传递,并可以存储, 这为建立寄存器模型提供了可能。一个单纯的Verilog路径,如top_tb.my_dut.counter,它是不能被传递的,也是无法存储的
读操作的整个过程如图:
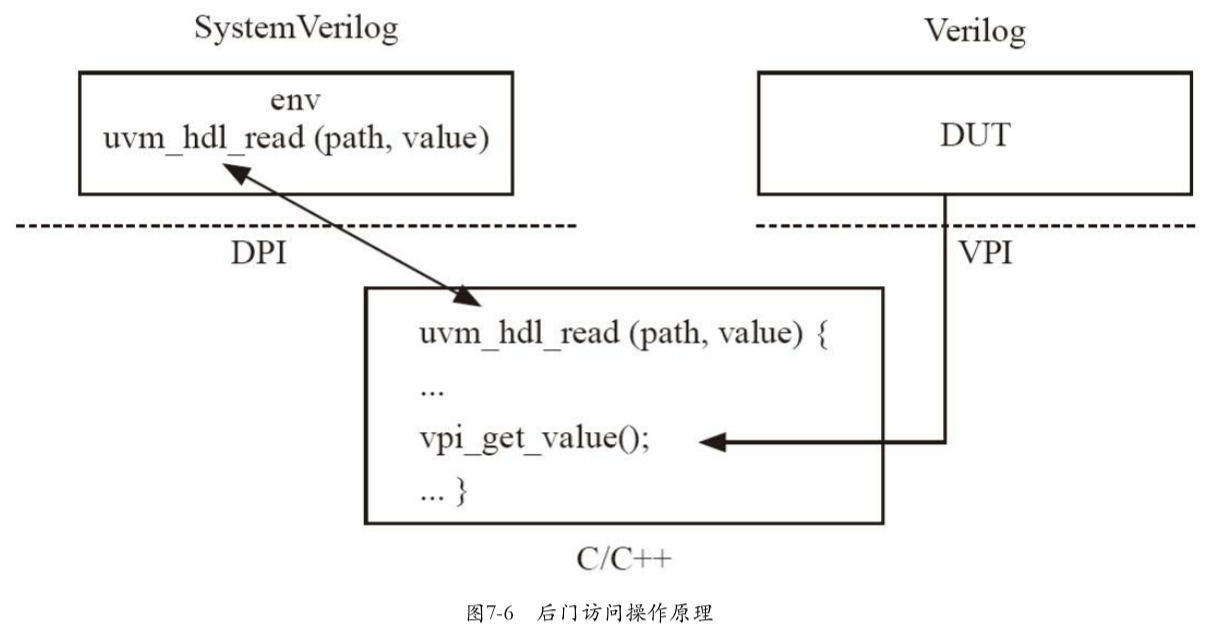
7.3.5 UVM中RAL后门访问操作实现
1.寄存器模型集成与修改
介绍完UVM中后门访问原理后,介绍使用RAL model的后门访问功能,我们需要对之前的验证环境进行修改,主要内容有:
- 直接添加该counter到RAL model层(没有uvm_reg和uvm_reg_field这一套)
- 补充:在
block实例化reg,注意configure()参数
- 补充:在
- 在
bast_test添加正确的hdl路径
设置好DUT内部路径
在reg_block中调用uvm_reg的configure函数时,设置好第三个路径参数:
1 | |
设置好根路径hdl_root
1 | |
上面两个路径合起来就是寄存器的路径
2.使用RAL model进行后门访问
UVM提供两类后门访问的函数:
- UVM_BACKDOOR形式的
read和write peek和poke
这两类函数的区别是,第一类会在进行操作时模仿DUT的行为,第二类则完全不管DUT的行为。如对一个只读的寄存器进行写操作,那么第一类由于要模拟DUT的只读行为,所以是写不进去的,但是使用第二类可以写进去
poke()函数用于第二类写操作,其原型为:

peek()函数用于第二类的读操作,其原型为:

无论是peek还是poke,其常用的参数都是前两个:
- 第一个参数表示操作是否成功
- 第二个参数表示读写的数据
在sequence中,可以使用如下的方式来调用这两个任务:
1 | |
7.4 复杂的寄存器模型
7.4.1 层次化的寄存器模型
1.应用背景
在现实应用中,一般会将block再加入一个block中,然后在base_test中实例化后者。从逻辑关系上看,呈现出的是两级的寄存器模型
具体来讲,一般只会在第一级的block中加入寄存器,而第二级的block通常只添加block,体现了较为清晰的结构
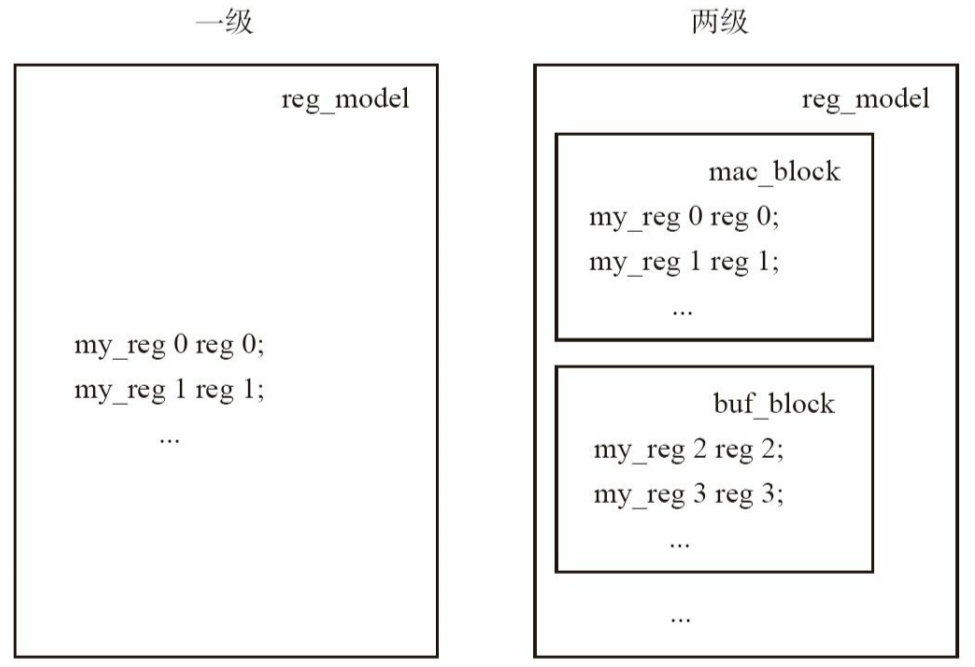
2.实现步骤与示例讲解
假如一个DUT分了三个子模块:
- 用于控制全局的global模块,global模块寄存器的地址为0x0000~0x0FFF
- 用于缓存数据的buf模块,buf部分的寄存器地址为0x1000~0x1FFF
- 用于接收发送以太网帧的mac模块,mac部分的寄存器地址为0x2000~0x2FFF
那么可以按照如下方式定义寄存器模型
1 | |
多级block实现
将一个子block加入父block中有两步:
- 第一步是先实例化子block
- 第二步是调用子block的
configure()函数- 需要使用后门访问,则
configure()路径需要说明子block的路径,这个路径不是绝对路径,而是相对于父block来说的路径(上例子不使用,所以直接给空)
- 需要使用后门访问,则
- 第三步是调用子block的
build()函数 - 第四步是调用子block的
lock_model()函数 - 第五步则是将子block的default_map,以子map的形式加入父block的default_map中
- 这是可以理解的,因为一般在子block中定义寄存器时,给定的都是寄存器的偏移地址,其实际物理地址还要再加上一个基地址。寄存器前门访问的读写操作最终都要通过default_map来完成。很显然,子block的default_map并不知道寄存器的基地址,它只知道寄 存器的偏移地址,只有将其加入父reg_block的default_map,并在加入的同时告知子map的偏移地址,这样父block的default_map就可以完成前门访问操作了
基地址与偏移地址
一般在子block中定义寄存器时,给定的都是寄存器的偏移地址,其实际物理地址还要再加上一个基地址
一般将具有同一基地址的寄存器作为整体加入一个block中,而不同的基地址对应不同的block。每个block一般都有与其对应的物理地址空间。对于本节介绍的子block,其里面还可以加入小的block,这相当于将地址空间再次细化
7.4.2 添加uvm_reg_file
UVM的寄存器模型中还有一个称为uvm_reg_file的概念。这个类的引入主要是用于区分不同的hdl路径
问题背景
如果你有很多寄存器需要后门访问,寄存器包括不同的文件中,则configure()的时候需要加上地址如下:
1 | |
这种寄存器一多,如果”fileA”或”fileB”一改,则需要修改大量的设置代码,很容易出错
下面是原文,一堆废话。。。
假设有两个寄存器regA和regB,它们的hdl路径分为”top_tb.mac_reg.fileA.regA”和”top_tb.mac_reg.fileB.regB”
延续上一节的例子,设top_tb.mac_reg下面所有寄存器的基地址为0x2000,这样,在最顶层的block中加入mac模块时,其hdl路径要写成:
mb_ins.configure(this, "mac_reg");相应的,在mac_blk的build中,要通过如下方式将regA和regB的路径告知寄存器模型:
2
3regA.configure(this, null, "fileA.regA");
…
regB.configure(this, null, "fileB.regB");当fileA中的寄存器只有一个regA时,这种写法是没有问题的,但是假如fileA中有几十个寄存器时,那么很显然,fileA.*会几十次地出现在这几十个寄存器的
configure()函数里。假如有一天,fileA的名字忽然变为filea_inst,那么就需要把这几十行中所有fileA替 换成filea_inst,这个过程很容易出错
为了适应这种情况,在UVM的寄存器模型中引入了uvm_reg_file的概念。uvm_reg_file同uvm_reg相同是一个纯虚类,不能直接使用,而必须使用其派生类
reg_file定义集成与使用示例
1 | |
reg_file定义与集成步骤
- 从
uvm_reg_file派生一个reg_file类 - 然后在my_blk中实例化reg_file,之后调用其
configure()函数- 第一个参数是其所在的block的指针
- 第二个参数是假设此reg_file是另外一个reg_file的父文件,那么这里就填写其父reg_file的指针(由于这里 只有这一级reg_file,因此填写null)
- 第三个参数则是此reg_file的hdl路径
- 在my_blk中实例化并配置寄存器
- 当把reg_file实例化并配置好后,在调用寄存器的configure参数时,就可以将其第二个参数设为reg_file的指针
reg_file的使用
加入reg_file的概念后,当fileA变为filea_inst时,只需要将file_a的configure()参数值改变一下即可,其他则不需要做任何改变
7.4.3 多个域的寄存器
前面所有例子中的寄存器都是只有一个域的,如果一个寄存器有多个域时,那么在建立模型时会稍有改变
问题背景
某个寄存器有三个域,其中最低两位为filedA,接着三位为filedB,接着四位为filedC,其余位未使用
实现步骤与示例讲解
1 | |
reg定义内容
- 声明多个field
build()中例化field,删除对field的configure()
block定义内容
- 声明reg
build()中例化reg,并配置reg,configure中的hdl参数为空build()中配置reg中的所有field,使用add_hdl_path_slice()给field添加hdl路径
原文解释
这里要先从uvm_reg派生一个类,在此类中加入3个uvm_reg_field。在reg_block中将此类实例化后,调用
tf_reg.configure()时要注意,最后一个代表hdl路径的参数已经变为了空的字符串,在调用tf_reg.build()之后要调用tf_reg.fieldA的configure()函数调用完fieldA的
configure()函数后,需要将fieldA的hdl路径加入tf_reg中,此时用到的函数是add_hdl_path_slice(),这个函数的参数:
- 第一个参数是要加入的路径
- 第二个参数则是此路径对应的域在此寄存器中的起始位数,如fieldA是从0开始的,而fieldB是从2开始的
- 第三个参数则是此路径对应的域的位宽
为什么在block中对field进行配置?上述
fieldA.configure()和tf_reg.add_hdl_path_slice()其实也可以如7.2.1节那样在three_field_reg的build中被调用。这两者有什么区别呢?解释:
如果是在所定义的uvm_reg类中调用,那么此uvm_reg其实就已经定型了,不能更改了
例如7.2.1节中定义了具有一个域的uvm_reg派生类,现在假如有一个新的寄存器,它也是只有一个域,但是这个域并不是如7.2.1节中那样占据了1bit,而只占据了8bit,那么此时就需要重新从uvm_reg派生一个类,然后再重新定义。如果7.2.1节中的reg_invert在定义时并没有在其build中调用reg_data的
configure()函数,那么就不必重新定义。因为没有调用configure()之前,这个域是不确定的我的吐槽:作者是不是傻逼啊,直接在reg里面修改
configure()不就行了吗。。。
7.4.4 多个地址的寄存器
问题背景
实际的DUT中,有些寄存器会同时占据多个地址,如7.3.2中counter被分成了高位和低位两个寄存器
这种方式的缺点:因其每次要读取counter的值时,都需要对counter_low和counter_high各进行一次读取操作,然后再将两次读取的值合成一个counter的值,所以这种方式使用起来非常不方便
解决方法
- 定义一个32位reg,且只有一个宽度相同的field
- 定义default_map的总线宽度时指定为16位
- 对default_map使用
add_reg时,给reg最小地址,存取方式为UVM_LITTLE_ENDIAN
这种方法相对简单,可以定义一个reg_counter,并在其构造函数中指明此寄存器的大小为32位,此寄存器中只有一个域,此域的宽度也为32bit,之后在reg_model中将其实例化即可。在调用default_map的add_reg函数时,要指定寄存器的地址,这里只需要指明最小的一个地址即可。这是因为在前面实例化default_map时,已经指明了它使用UVM_LITTLE_ENDIAN形式,同时总线的 宽度为2byte,即16bit,UVM会自动根据这些信息计算出此寄存器占据两个地址。当使用前门访问的形式读写此寄存器时,寄存器模型会进行两次读写操作,即发出两个transaction,这两个transaction对应的读写操作的地址从0x05一直递增到0x06
代码示例
寄存器模型示例
1 | |
使用示例
1 | |
7.4.5 加入存储器模型uvm_mem
1.存储器与地址
除了寄存器外,DUT中还存在大量的存储器。这些存储器有些被分配了地址空间,有些没有。验证人员有时需要在仿真过程中得到存放在这些存储器中数据的值,从而与期望的值比较并给出结果
2.后门访问的优势:一级检查与两级检查
一个DUT的功能是接收一种数据,它经过一些相当复杂的处理(操作A)后将数据存储在存储器中,这块存储器是 DUT内部的存储器,并没有为其分配地址。当存储器中的数据达到一定量时,将它们读出,并再另外做一些复杂处理(如封装成另外一种形式的帧,操作B)后发送出去。在验证平台中如果只是将DUT输出接口的数据与期望值相比较,当数据不匹配情况出现时,则无法确定问题是出在操作A还是操作B中,如图7-8a所示。此时,如果在输出接口之前再增加一级比较,就可以快速地定位问题所在了,如下图所示
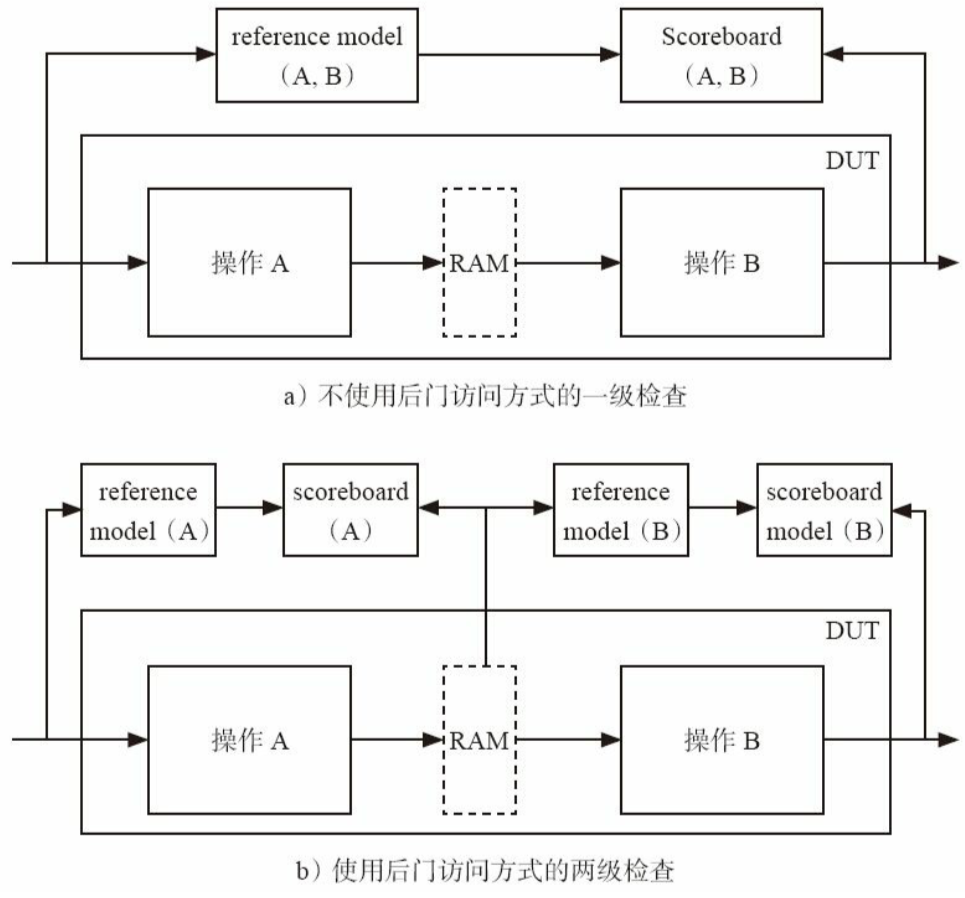
3.添加方法与示例分析
要在寄存器模型中加入存储器非常容易
在一个16位的系统中加入一块1024×16(深度为1024,宽度为16)的存储器的代码如下:
1 | |
步骤:
- 首先由
uvm_mem派生一个类my_memory,在其new函数中调用super.new()函数,这个函数有三个参数:- 第一个是名字
- 第二个是存储器的深度
- 第三个是宽度
- 在reg_model的
build()函数中,将存储器实例化,调用其configure()函数:- 第一个参数是所在 reg_block的指针
- 第二个参数是此块存储器的hdl路径
- 最后调用
default_map.add_mem()函数,将此块存储器加入default_map中,从 而可以对其进行前门访问操作。如果没有对此块存储器分配地址空间,那么这里可以不将其加入default_map中。在这种情况下,只能使用后门访问的方式对其进行访问
如何访问mem:
要对此存储器进行读写,可以通过调用read()、write()、peek()、poke()实现。相比uvm_reg来说,这四个任务/函数在调用的时候需要额外加入一个offset的参数,说明读取此存储器的哪个地址:
1 | |
4.存储器与总线位宽不同时
上面存储器的宽度与系统总线位宽恰好相同。 假如存储器的宽度大于系统总线位宽时, 情况会略有不同。 如在一个16位的系统中加入512×32的存储器:
1 | |
存储器模型代码的变更:在派生my_memory时, 就要在其new函数中指明其宽度为32bit, 在my_block中加入此memory的方法与前面的相同
产生效果:进行多次总线访问
很明显,这里加入的存储器的一个单元占据两个物理地址, 共占据1024个地址。 那么当使用read、 write、 peek、 poke时,输入的参数offset 代表实际的物理地址偏移还是某一个存储单元偏移呢? 答案是存储单元偏移。 在访问这块512×32的存储器时,offset的最大值是511, 而不是1023。 当指定一个offset, 使用前门访问操作读写时, 由于一个offset对应的是两个物理地址,所以寄存器模型会在总线上进行两次读写操作
7.5 寄存器模型对DUT的模拟
7.5.1 期望值与镜像值
问题背景
由于DUT中寄存器的值可能是实时变更的,寄存器模型并不能实时地知道这种变更,因此,寄存器模型中的寄存器的值有时与DUT中相关寄存器的值并不一致
注意!!!对于存储器来说,并不存在期望值和镜像值。寄存器模型不对存储器进行任何模拟。若要得到存储器中某个存储单元的值, 只能使用7.4.5节中的四种操作(不能使用本节介绍的get()、get_mirrored_value()、set())
镜像值(mirrored value)
对于任意一个寄存器,寄存器模型中都会有一个专门的变量用于最大可能地与DUT保持同步,这个变量在寄存器模型中称为DUT的镜像值(mirrored value),获得方法:get_mirrored_value()
期望值(desired value)
除了DUT的镜像值外,寄存器模型中还有期望值(desired value)。如目前DUT中invert的值为'h0,寄存器模型中的镜像值也为'h0,但是希望向此寄存器中写入一个'h1,此时有两种方法:
- 一种方法是直接调用前面介绍的
write()任务,将'h1写入,期望值与镜像值都更新为'h1 - 另外一种方法是通过
set()函数将期望值设置为'h1(此时镜像值依然为0),之后调用update()任务,update()任务会检查期望值和镜像值是否一致,如果不一致,那么将会把期望值写入DUT中,并且更新镜像值
使用示例:
1 | |
get()函数可以得到寄存器的期望值get_mirrored_value()可以得到镜像值
7.5.2 常用操作及其对期望值和镜像值的影响
1.read&write操作:
无论通过后门访问还是前门访问的方式从DUT中读取或写入寄存器的值,在操作完成后,寄存器模型都会根据读写的结果更新期望值和镜像值(二者相等)
2.peek&poke操作:
在操作完成后, 寄存器模型会根据操作的结果更新期望值和镜像值(二者相等)
3.get&set操作:
set操作会更新期望值, 但是镜像值不会改变
get操作会返回寄存器模型中当前寄存器的期望值
4.update操作:
这个操作会检查寄存器的期望值和镜像值是否一致, 如果不一致, 那么就会将期望值写入DUT中, 并且更新镜像值, 使其与期望值一致
每个由uvm_reg派生来的类都会有update操作, 其使用方式在上一节中已经介绍过
每个由 uvm_reg_block派生来的类也有update操作,它会递归地调用所有加入此reg_block的寄存器的update任务
5.randomize操作:
寄存器模型提供randomize接口。randomize之后, 期望值将会变为随机出的数值, 镜像值不会改变。 但是并不是寄存器模型中所有寄存器都支持此函数;如果不支持,则randomize调用后其期望值不变
若要关闭随机化功能,build中调用reg_xxx.configure时将其第八个参数设置为0即可
一般的, randomize不会单独使用而是和update一起。如在DUT上电复位后, 需要配置一些寄存器的值。 这些寄存器的值通过randomize获得, 并使用update任务配置到DUT中
7.6 寄存器模型中一些内建的sequencce
UVM提供了一系列的sequence,可以用于检查寄存器模型及DUT中的寄存器
7.6.1 检查后门访问中hdl路径的sequence
uvm_reg_mem_hdl_paths_seq用于检查检查寄存器/存储器的hdl路径的正确性,原型为:
1 | |
这个sequence的运行依赖于在基类uvm_sequence中定义的一个uvm_block变量:model
使用方法与示例
1 | |
方法
- 在启动此sequence时必须给
model赋值寄存器模型 - 可以在任意的sequence中,可以启动此sequence
- 调用的
start()任务时传入参数为null(即不传入transaction)- 因为它正常工作不依赖于这个sequencer,而依赖于model变量
作用
- 这个sequence会试图读取hdl所指向的寄存器,如果无法读取,则给出错误提示。 由这个sequence的名字也可以看出,它除了检查寄存器外,还检查存储器
- 如果某个寄存器/存储器在加入寄存器模型时没有指定其hdl路径,那么此sequence在检查时会跳过这个寄存器/存储器
7.6.2 检查默认值的sequence
uvm_reg_hw_reset_seq用于检查上电复位后寄存器模型与DUT中寄存器的默认值是否相同,它的原型为:
1 | |
复位与默认值(复位值)
对于DUT来说, 在复位完成后, 其值就是默认值。但是对于寄存器模型来说, 如果只是将它集成在验证平台上, 而不做任何处理,那么它所有寄存器的值为0, 此时需要调用reset()函数来使其内寄存器的值变为默认值(复位值)
1 | |
使用方法
与uvm_reg_mem_hdl_paths_seq类似,在启动时也需要指定其model变量
作用
这个sequence在其检查前会调用model的reset函数,所以即使在集成到验证平台时没有调用reset函数,这个sequence也能正常工作。除了复位(reset)外,这个sequence所做的事情就是使用前门访问的方式读取所有寄存器的值,并将其与寄存器模型中的值比较
如何跳过某个寄存器的检查:resource_db机制
如果想跳过某个寄存器的检查,可以在启动此sequence前使用resource_db设置不检查此寄存器
resource_db机制与config_db机制的底层实现是一样的,uvm_config_db类就是从uvm_resource_db类派生而来的。由于在寄存器模型的sequence中,get操作是通过resource_db来进行的,所以这里使用resource_db来进行设置设置
这里可以通过设置NO_REG_TESTS或者NO_REG_HW_RESET_TEST,都可以实现跳过该寄存器检查:
1 | |
或者使用:
1 | |
7.6.3 检查读写功能的sequence
UVM提供两个sequence分别用于检查寄存器和存储器的读写功能。uvm_reg_access_seq用于检查寄存器的读写,uvm_mem_access_seq用于检查存储器的读写
1.uvm_reg_access_seq
uvm_reg_access_seq的原型为
1 | |
作用
这个sequence会使用前门访问的方式向所有寄存器写数据,然后使用后门访问的方式读回,并比较结果。最后把这个过程反过来,使用后门访问的方式写入数据,再用前门访问读回
使用方法
与uvm_reg_mem_hdl_paths_seq类似,在启动时也需要指定其model变量,这个sequence要正常工作必须为所有的寄存器设置好hdl路径
跳过寄存器检查
如果要跳过某个寄存器的读写检查, 则可以在启动sequence前使用如下的两种方式之一进行设置:
1 | |
2.uvm_mem_access_seq
uvm_mem_access_seq原型为
1 | |
作用
这个sequence会通过使用前门访问的方式向所有存储器写数据,然后使用后门访问的方式读回,并比较结果。最后把这个过程反过来,使用后门访问的方式写入数据,再用前门访问读回
使用方法
与uvm_reg_mem_hdl_paths_seq类似,在启动时也需要指定其model变量,这个sequence要正常工作必须为所有的寄存器设置好hdl路径
跳过寄存器检查
如果要跳过某块存储器的检查,则可以使用如下的三种方式之一进行设置:
1 | |
7.7 寄存器模型的高级用法
7.7.1 两种读操作返回值数据通路
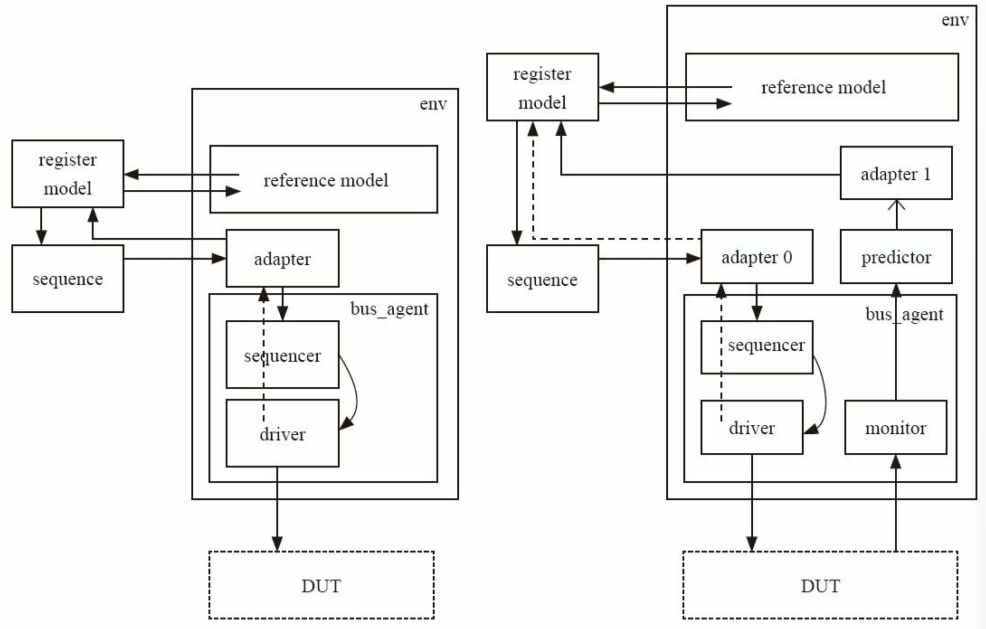
有两种返回值数据通路:
1.auto predict(左图)
在7.2.2节讲述读操作的返回值时,介绍的这种这种方式要依赖于driver,当driver将读取值返回后,寄存器模型会更新寄存器的镜像值和期望值。这个功能被称为寄存器模型的auto predict功能
使用方式:在建立寄存器模型时使用如下的语句打开此功能:
1 | |
2.手动创建reg_predictor(右图)
如右图所示,方法2是由monitor将从总线上收集到的transaction交给寄存器模型,后者更新相应寄存器的值
使用方法
- 需要实例化一个reg_predictor对象,并为这个reg_predictor实例化一个adapter
- 在connect_phase中,需要将reg_predictor和
bus_agt或bus_agt.monitor的ap口连接在一起,并设置reg_predictor的adapter和map【只有设置了map后,才能将predictor和寄存器模型关联在一起】 - 关闭auto predict(也就是7-9中虚线路径)【因为经过之前的设置,事实上存在着两条更新寄存器模型的路径】
reg_predictor及其adapter集成与配置代码
1 | |
关闭auto predict的代码
1 | |
两种返回值更新到寄存器的方法对比
方法1:左图使用driver的返回值更新寄存器模型
方法2:右图使用monitor,并增加reg_predictor将返回值更新到寄存器模型
两条读操作对比
当总线上只有一个主设备(master)时,则图7-9的左图和右图是完全等价的
如果有多个主设备,则左图会漏掉某些trasaction
7.7.2 其他操作
本节介绍UVM书7.7.2、7.7.3中内容,包括以下四种操作:
mirror()predictor()randomize()搭配update
1.mirror操作
UVM提供mirror操作,用于读取DUT中寄存器的值并将它们更新到寄存器模型中,函数原型为:
1 | |
它有多个参数,但是常用的只有前三个:
- 第二个参数指的是如果发现DUT中寄存器的值与寄存器模型中的镜像值不一 致,那么在更新寄存器模型之前是否给出错误提示。其可选的值为
UVM_CHECK和UVM_NO_CHECK
它有两种应用场景:
- 一是在仿真中不断地调用它,使得到整个寄存器模型的值与DUT中寄存器的值保持一致,此时check选项是关闭的
- 二是在仿真即将结束时,检查DUT中寄存器的值与寄存器模型中寄存器的镜像值是否一致,这种情况下,check选项是打开的
它会更新期望值和镜像值
它的调用逻辑(同update操作类似):mirror操作既可以在uvm_reg级别被调用,也可以在uvm_reg_block级别被调用。当调用一个uvm_reg_block的mirror时,其实质是调用加入其中的所有寄存器的mirror
2.predict操作
问题背景:
前文已经说过,在通信系统中存在大量的计数器。当网络出现异常时,借助这些计数器能够快速地找出问题所在,所以必须要保证这些计数器的正确性。一般的,会在仿真即将结束时使用mirror操作检查这些计数器的值是否与预期值一致
在DUT中的计数器是不断累加的,但是寄存器模型中的计数器则保持静止。参考模型会不断统计收到了多少包,那么怎么将这些统计数据传递给寄存器模型呢? 前文中介绍的所有的操作都无法完成这个事情,无论是set,还是write,或是poke;无论是后门访问还是前门访问
我的理解:
- predict就是不修改DUT的update,update会更新期望值到DUT中
- 为什么不直接用read?本质上这些操作是为了实现DUT与RAL model之间的同步,read底层也调用了该函数
这个问题的实质是想人为地更新镜像值,但是同时又不要对DUT进行任何操作
UVM提供predict操作来实现这样的功能,函数原型为:
1 | |
它的参数:
- 第一个参数表示要预测的值
- 第二个参数是byte_en,默认-1的意思是全部有效,第三个参数是预测的类型,第四个参数 是后门访问或者是前门访问
- 第三个参数预测类型
- 第四个参数是后门访问或者是前门访问
第三个参数预测类型有如下几种可以选择:
1 | |
它与read/peek和write/poke:read/peek和write/poke操作在对DUT完成读写后,也会调用此函数,只是它们给出的参数是UVM_PREDICT_READ和 UVM_PREDICT_WRITE。要实现在参考模型中更新寄存器模型而又不影响DUT的参数为UVM_PREDICT_DIRECT,即默认值
它会更新镜像值和期望值
使用示例
使用predict更新镜像值
1 | |
在my_model中,每得到一个新的transaction,就先从寄存器模型中得到counter的期望值(此时与镜像值一致),之后将新的transaction的长度加到counter中,最后使用
predict()函数将新的counter值更新到寄存器模型中。predict操作会更新镜像值和期望值
在测试用例中,仿真完成后可以检查DUT中counter的值是否与寄存器模型中的counter值一致:
1 | |
3.randomize()
randomize操作是实现reg/field随机化
它更新寄存器模型中的预期值,不会更新期望值,一般和update一起使用将随机化后的参数更新到DUT中
randomize与update作用:适用于在仿真开始时随机化并配置参数
randomize前提
对field的随机化除了满足定义条件外还需要满足定义条件,reg只需要满足定义条件即可
定义条件
- field可随机化条件1:uvm_reg中将加入的uvm_reg_field定义为rand类型
- reg可随机化条件:uvm_reg_block中将uvm_reg加入中定义为rand类型
配置条件
- field可随机化条件2:
configure参数8(is_rand)为1 - field可随机化条件3:
configure参数4(access)为可写类型
- field可随机化条件2:
补充
- field配置参数
1 | |
- field读写类型
- 可写:RW、WRC、WRS、WO、 W1、WO1
- 不可写:RO、RC、RS、WC、WS、W1C、W1S、W1T、W0C、W0S、W0T、W1SRC、W1CRS、W0SRC、 W0CRS、WSRC、WCRS、WOC、WOS
随机化位置
可以在uvm_reg_block级别调用randomize函数,也可以在uvm_reg级 别,甚至可以在uvm_reg_field级别调用:
1 | |
只读类型
既然存在randomize,那么也可以为它们定义constraint
1 | |
7.7.4 扩展位宽
1.扩展数据位宽
在自定义uvm_reg的衍生类时,其构造函数调用了super.new(),其中第二个参数为系统总线的宽度,它可以是32、 64、128等。但在寄存器模型中,这个数字的默认最大值是64,它是通过UVM_REG_DATA_WIDTH宏来控制的:
1 | |
如果想要扩展系统总线的位宽,可以通过重新定义这个宏来扩展
2.扩展地址位宽
与数据位宽类似,地址位宽也有默认最大值限制,其默认值也是64,它是通过UVM_REG_ADDR_WIDTH控制
1 | |
3.扩展字选择信号位宽
在默认情况下,字选择信号的位宽等于数据位宽除以8,它通过如下的宏来控制
1 | |
7.8 寄存器模型的其他常用函数
7.8.1 get_root_blocks
在本章以前的例子中,若某处要使用寄存器模型,则必须将寄存器模型的指针传递过去
除了这种指针传递的形式外,UVM还提供其他函数,使得可以在不使用指针传递的情况下得到寄存器模型的指针
该函数原型为:
1 | |
作用:get_root_blocks()函数得到验证平台上所有的根块(root block)
根块:指最顶层的block。如7.4.1节中的reg_model是root block,但是global_blk、buf_blk和mac_blk不是
使用示例
1 | |
注意类型转换!
在使用
get_root_blocks()函数得到reg_block的指针后,要使用cast将其转化为目标reg_block形式(示例中为reg_model)。以后就可以直接使用p_rm来进行寄存器操作,而不必使用p_sequencer.p_rm
7.8.2 get_reg_by_offset函数
问题背景
在建立了寄存器模型后,可以直接通过层次引用的方式访问寄存器:
1 | |
但是出于某些原因,如果依然要使用地址来访问寄存器模型,那么此时可以使用get_reg_by_offset()函数通过寄存器的地址得到一个uvm_reg的指针,再调用此uvm_reg的read()或write()就可以进行读写操作
函数原型
1 | |
1 | |
作用:
get_reg_by_offset()函数可以通过寄存器的地址得到一个uvm_reg的指针get_addresses()函数可以得到这个寄存器的所有地址,其返回值是一个动态数组addrs。其中无论是大端还是小端,addrs[0]是LSB 对应的地址
1 | |
代码分析
通过调用最顶层的reg_block的
get_reg_by_offset(),即可以得到任一寄存器的指针。如果如7.4.1节那样使用了层次的寄存器模型,从最顶层的reg_block的get_reg_by_offset()也可以得到子reg_block中的寄存器。即假如buf_blk的地址偏移是’h1000,其中有偏移 为’h3的寄存器(即此寄存器的实际物理地址是’h1003),那么可以直接由p_rm.get_reg_by_offset('h1003)得到此寄存器,而不必使用p_rm.buf_blk.get_reg_by_offset('h3)多地址寄存器访问方案分析:
如果没有使用7.4.4节所示的多地址寄存器,那么情况比较简单,上述代码会运行第39行的分支。当存在多个地址的情况下,通过get_addresses函数可以得到这个函数的所有地址,其返回值是一个动态数组addrs。其中无论是大端还是小端,addrs[0]是LSB 对应的地址。即对于7.3.2节DUT中的counter(此DUT是大端),那么addrs[0]中存放的是‘h6。而假如是小端,两个地址分别 是’h1005和’h1006,那么addrs[0]中存放的是’h1005。第41到48行通过比较addrs中的地址与目标地址,最终得到要访问的数据。
写寄存器与读操作类似,这里不再列出
2023年1月31日 16:08:39
第八章 UVM中的factory机制
8.1 SystemVerilog对重载的支持
8.1.1 任务与函数的重载
SystemVerilog是一种面向对象的语言。面向对象语言都有一大特征:重载
重载:
- 当在父类中定义一个函数/任务时,如果将其设置为virtual类型,那么就可以在子类中重载这个函数/任务
- 重载的最大优势是使得一个子类的 指针以父类的类型传递时,其表现出的行为依然是子类的行为
这种函数/任务重载的功能在UVM中得到了大量的应用。其实最典型的莫过于各个phase:在一个验证平台中,UVM树上的结点是各个类型的,UVM不必理会它们具体是什么类型,统一将它们当作uvm_component来对待,这极大方便了管理。当各个phase被调用时,以build_phase为例,实际上系统是使用如下的方式调用:
1 | |
c_ptr是
uvm_component类型的,而不是其他类型,如my_driver(但是c_ptr指向的实例却是my_driver类)
8.1.2 约束的重载
1.问题背景
在测试一个接收MAC功能的DUT时,有多种异常情况需要测试,如preamble错误、sfd错误、CRC错误等。针对这些错误,在 transaction中分别加入标志位:
1 | |
这些错误都是异常的情况,在正常的测试用例中,它们的值都应该为0(如果在每次产生transaction时进行约束会非常麻烦。PS:这里加约束也不写清楚原因,作者写的依托答辩):
1 | |
由于它们出现的概率非常低,因此结合SV中的dist,在定义transaction时指定如下的约束,从而代表实际transaction的情况:
1 | |
问题出现:无法控制什么时候出现异常,我们只定义了正常测试用例,需要构造异常测试用例!
- 上述语句是在随机化时,
crc_err、pre_err和sfd_err只有1/1_000_000_000的可能性取值会为1,其余均为0。但最大的问题是其何时取1、何时取0是无法控制的。如果某个测试用例用于测试正常的功能,则不能有错误产生,即crc_err、pre_err和sfd_err的值要一定为0。上面的constraint明显不能满足这种要求,虽然只有1/1_000_000_000的可能性,在运行特别长的测试用例时,如发送了1_000_000_000个包,那么有非常大的可能会产生一个crc_err、pre_err或sfd_err值为1的包
补充:构建异常测试用例的方法有很多,如这里的factory机制的重载,还有下一节的callback机制
有两种解决方法:
- 方法1:关闭约束(关闭某一个/所有约束)
- 方法2:对约束重载
方法1实现
在transaction中使用如下方式定义约束
1 | |
在正常的测试用例中,可以使用如下方式随机化
1 | |
在异常的测试用例中,可以使用如下方式随机化(关闭约束)
1 | |
能够使用这种方式的前提是m_trans已经实例化。如果不实例化,直接使用
`uvm_do宏会报空指针的错误关闭约束:
上述语句中只是单独地关闭了某一个约束:
m_trans.crc_err_cons.constraint_mode(0);也可以使用如下的语句关闭所有的约束:
mtrans.constraint_mode(0),这种情况下,随机化时就需要分别对crc_err、pre_err及sfd_err进行约束
方法2
原理:SystemVerilog中一个非常有用的特性是支持约束的重载。
使用第一种方式中my_transaction的定义, 在其基础上派生一个新的transaction
1 | |
这个新的transaction中将crc_err_cons重载了。因此在异常的测试用例中可使用如下方式随机化:
1 | |
8.2 使用factory机制进行重载
8.2.1 factory机制式的重载
factory重载简介:factory机制最伟大的地方在于其具有重载功能(重载并不是factory机制的发明,所有面向对象的语言都支持函数/任务重载,另外SV还支持对约束的重载),只是factory机制的重载与这些重载都不一样
1.SV的重载示例
本段与下段将采用一个示例演示SV与factory重载的不同
SV的重载:
- 可重载虚函数,在子类重新定义后,子类对象执行的是重载后的函数
- 普通函数,在子类重新定义后,子类对象执行的仍然是父类函数
SV重载示例:
定义两个类:bird及其衍生类parror,其中hungry()函数为可被重载的虚函数,hungry2()不可被重载
1 | |
执行下方代码:
1 | |
出现如下结果:
1 | |
总结一下:
- 可重载虚函数,在子类重新定义后,子类对象执行的是重载后的函数
- 普通函数,在子类重新定义后,子类对象执行的仍然是父类函数
2.factory的重载示例
factory的重载与SV执行的结果相反,是作用于父类的
factory重载示例
与SV重载代码类似,只不过需要在SV重载基础上,执行的时候另外添加factory的重载操作:
1 | |
出现如下结果:
1 | |
总结一下
虽然
print_hungry()接收的是bird类型的参数,但是从运行结果可以推测出来,无论是第一次还是第二次调用print_hungry(),传递的都是类型为bird但是指向parrot的指针第二次调用就是正常的SV重载,可以很好理解
但第一次却使人很难接受,这就是factory机制的重载功能,其原理如图8-1所示
3.factory的重载分析
factory重载过程:
- 定义父类及其衍生类,内部定义可重载虚函数
- 实例化前执行
set_type_override_by_type(被重载的父类, 重载的子类)对重载进行注册(形参不能颠倒,如颠倒会报错,8.2.2将会讲到参数) - 使用工厂方式进行实例化
inst::type_id::create()
重载过程分析:对重载的一种注册
在实例化时,UVM会通过factory机制在自己内部的一张表格中查看是否有相关的重载记录set_type_override_by_type()语句相当于在factory机制的表格中加入了一条记录。当查到有重载记录时,会使用新的类型来替代旧的类型。所以虽然在build_phase中写明创建bird的实例,但是最终却创建了parrot的实例
为什么会有这种操作?
为了重载可以实现真正的重载,可以实现被重载函数的全部重载(我猜的)
重载中子类、父类的实例化流程(图8-1):
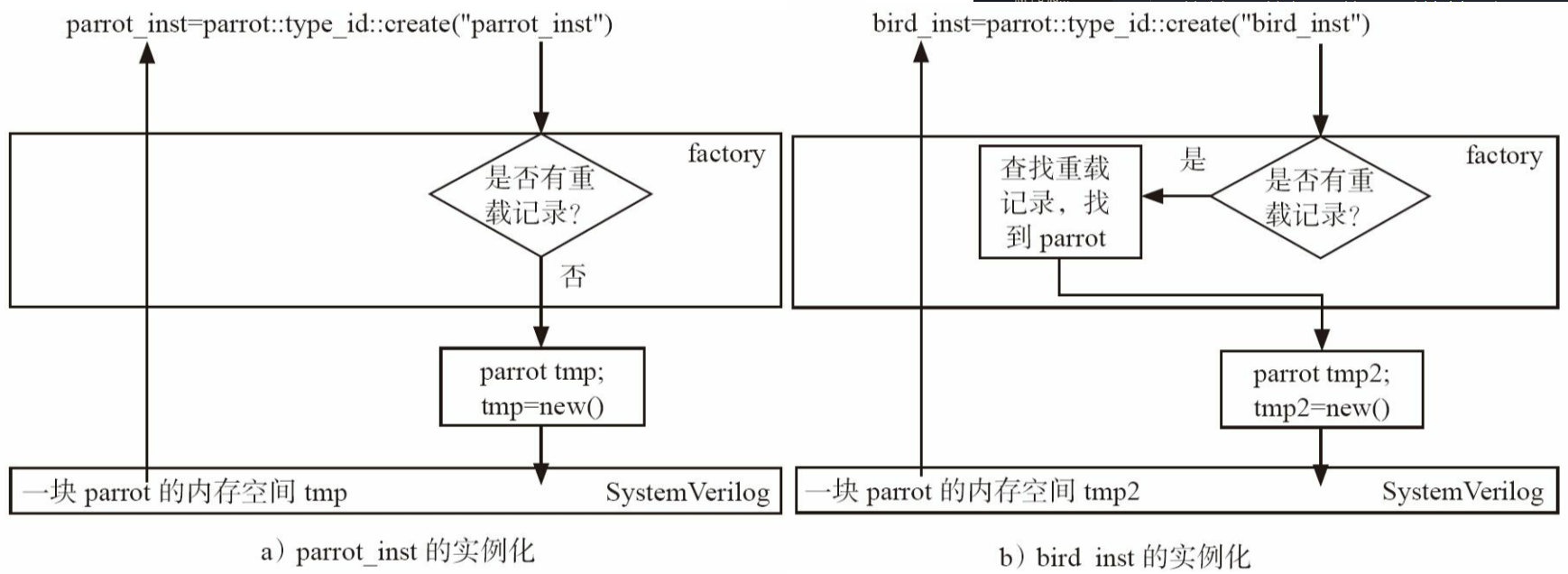
4.factory的重载四条件
使用factory机制的重载是有前提的,并不是任意的类都可以互相重载。要想使用重载的功能,必须满足以下要求:
- ① 子类父类都注册:无论是重载的类(parrot)还是被重载的类(bird),都要在定义时注册到factory机制中
- ② 工厂进行实例化:被重载的类(bird)在实例化时,要使用factory机制式的实例化方式,而不能使用传统的new方式
- ③ 具有派生关系:最重要的是,重载的类(parrot)要与被重载的类(bird)有派生关系。重载的类必须派生自被重载的类,被重载的类必须是重载类的父类;如果没有则会报错
- ④ comp与object无法重载:component与object之间互相不能重载。虽然uvm_component派生自uvm_object,但这两者的血缘关系太远根本不能重载。从两者的new参数的函数就可以看出来,二者互相重载时,多出来的一个parent参数会使factory机制无所适从
8.2.2 重载的方式及种类
本节介绍几个重载相关的函数,以及命令行重载:
| 函数列表 | 所属类 | 参数类型 | 作用区域 |
|---|---|---|---|
| set_type_override_by_type | uvm_component | uvm_object_wrapper | 所有对象 |
| set_inst_override_by_type | uvm_component | uvm_object_wrapper | 指定路径下的对象 |
| set_type_override | uvm_component | 字符串 | 所有对象 |
| set_inst_override | uvm_component | 字符串 | 指定路径下的对象 |
| set_type_override_by_type | uvm_factory | uvm_object_wrapper | 所有对象 |
| set_inst_override_by_type | uvm_factory | uvm_object_wrapper | 指定路径下的对象 |
| set_type_override_by_name | uvm_factory | 字符串 | 所有对象 |
| set_inst_override_by_name | uvm_factory | 字符串 | 指定路径下的对象 |
1.set_type_override_by_type()函数是uvm_component的函数,可以实现两种不同类型之间的重载,原型为:
1 | |
在实际应用中一般只用前两个参数:
- 第一个参数是被重载的类型
- 第二个参数是重载的类型
- 其中第三个参数是replace,将会在下节讲述这个参数
2.set_inst_override_by_type()函数是uvm_component的函数,用于不是把验证平台中的A类型全部替换成B类型,而只是替换其中的某一部分,原型为:
1 | |
参数
- 第一个参数是相对路径
- 第二个参数是被重载的类型
- 第三个参数是要重载的类型
使用示例
以3.2.2节中的UVM树为例,要将env.o_agt.mon替换成new_monitor:
1 | |
3.set_type_override()函数是uvm_component的函数,用于使用字符串来替代get_type(),实现两种不同类型的重载
无论是set_type_override_by_type()还是set_inst_override_by_type(),它们的参数都是一uvm_object_wrapper型的类型参数,这种参数通过xxx::get_type()的形式获得,UVM提供了这个函数来使用字符串替换这种晦涩的写法
set_type_override()原型为:
1 | |
要使用parrot替换bird,只需要添加如下语句:
1 | |
4.set_inst_override()函数是uvm_component的函数,用于使用字符串来替代get_type(),实现两种不同类型的部分重载,原型为:
1 | |
对于上面使用new_monitor重载my_monitor的例子,可以使用语句:
1 | |
5.uvm_factory中的四个同名方法
上述的所有函数都是uvm_component的函数,但是如果在一个无法使用component的地方,如在top_tb的initial语句里,就无法使用。UVM提供了另外四个函数来替换上述的四个函数,这四个函数的原型是:
1 | |
这四个函数都位于uvm_factory类中:
- 第一个函数与uvm_component中的同名函数类似,传递的参数相同。
- 第二个对应uvm_component中的同名函数,只是其输入参数变了,这里需要输入字符串类型的full_inst_path。这个full_inst_path就是要替换的实例使用get_full_name()得到的路径值
- 第三个与uvm_component中的set_type_override类似,传递的参数相同
- 第四个对应uvm_component中的set_inst_override,也需要一个full_inst_path
有两种调用方法:
①系统中存在一个uvm_factory类型的全局变量factory。可以在initial语句里使用如下方式调用这四个函数:
1 | |
②在一个component内也完全可以直接调用factory机制的重载函数
1 | |
这4个函数与uvm_componet中同名函数的关系
事实上,uvm_component的四个重载函数直接调用了factory的相应函数
6.使用命令行进行重载
除了可以在代码中进行重载外,还可以在命令行中进行重载
1 | |
- uvm_set_inst_override对应
set_inst_override_by_name() - uvm_set_type_override对应
set_type_override_by_name()
类型重载的命令行参数中有三个选项,其中最后一个replace表示是否可以被后面的重载覆盖。它的含义与代码清单8-20中的 replace一样,将会在下节讲述。
使用示例
对于实例重载(部分重载):
1 | |
对于类型重载:
1 | |
8.2.3 复杂的重载
本节主要讲的内容:
- 连续的重载
- 替换式的重载
1.连续的重载(子类的子类进行重载)
依然以bird与parrot的例子讲述,现在从parrot又派生出了一个新的类big_parrot(子类的子类):
1 | |
在build_phase中设置如下的连续重载,并调用print_hungry函数:
1 | |
最终输出的都是:
1 | |
2.替换式的重载(两个子类对父类重载)
除了这种连续的重载外,还有一种是替换式的重载。假如从bird派生出了新的鸟sparrow:
1 | |
在build_phase中设置如下重载:
1 | |
那么最终的输出结果是:
1 | |
这种替换式重载的前提是调用set_type_override_by_type时,其第三个replace参数被设置为1(默认情况下即为1)。如果为0那么最终得到的结果将会是:
1 | |
结果分析
- replace为1(默认值):晚的重载
- replace为0:早的重载
3.子类间的重载
在创建bird的实例时,factory机制查询到两条相关的记录,它并不会在看完第一条记录后即直接创建一个parrot的实例,而是 最终看完第二条记录后才会创建sparrow的实例。由于是在读取完最后的语句后才可以创建实例,所以其实下列的重载方式也是允许的:
1 | |
最终输出结果是:sparrow成功对父类进行了重载
1 | |
结果分析
虽然子类间的重载(代码第86行)前面的重载四前提的第三条相违背,sparrow并没有派生自parrot但依然可以重载parrot。这样使用依然是有条件的,最终创建出的实例是sparrow类型的,而最初是bird类型的,这两者之间依然有派生关系。代码去掉了对parrot_inst的实例化。因为在第86行存在的情况下再实例化一个parrot_inst会出错。所以,重载四前提的第三条应该改为:
在有多个重载时,最终重载的类必须派生自最初被重载的类,最初被重载的类必须是最终重载类的父类
8.2.4 factory机制的调试
| 函数名 | 所属类(可用的全局变量) | 作用 | 推荐调用位置 |
|---|---|---|---|
| print_override_info函数 | uvm_component | 输出所有的打印信息 | |
| print函数 | uvm_factory(factory) | 根据参数打印信息 | |
| debug_create_by_name函数 | uvm_factory(factory) | 效果同print_override_info | |
| debug_create_by_type函数 | uvm_factory(factory) | 效果同print_override_info | |
| print_topology函数 | uvm_root(uvm_top) | 显示出整棵UVM树的拓扑结构 | build_phase之后 |
1.print_overrid_info函数
UVM提供了print_override_info函数来输出所有的打印信息
以上节中的new_monitor重载my_monitor为例:
1 | |
验证平台中仅仅有这一句重载语句,那么调用print_override_info函数打印的方式为:
1 | |
最终输出的信息为:
1 | |
你要查看哪个类?
这里会明确地列出原始类型和新类型。在调用
print_override_info()时,其输入的类型应该是原始的类型,而不是新的类型
2.debug_create_by_name与debug_create_by_type函数
print_override_info()是个uvm_component的成员函数,它实质上是调用uvm_factory的debug_create_by_name()。 除该函数外,uvm_factory还有debug_create_by_type(),其原型为:
1 | |
使用它对new_monitor进行调试的代码为:
1 | |
其输出与使用print_override_info相同
3.print函数
除了上述两个函数外,uvm_factory还提供print()函数:
1 | |
参数:这个函数只有一个参数,取值可能为0、1或2
- 0时仅打印被重载的实例和类型,其打印出的信息大体如下:
1 | |
- 1时打印参数为0时的信息,以及所有用户创建的、注册到factory的类的名称
- 2时打印参数为1时的信息,以及系统创建的、所有注册到factory的类的名称(如uvm_reg_item)
4.print_topology
还有另外一个重要的工具可以显示出整棵UVM树的拓扑结构,这个工具就是uvm_root的print_topology()函数。UVM树在build_phase执行完成后才完全建立完成,因此,这个函数应该在build_phase之后调用:
1 | |
最终显示的结果(部分)为:

从这个拓扑结构可以清晰地看出,env.o_agt.mon被重载成了new_monitor类型
print_topology()这个函数非常有用,即使在不进行factory机制调试的情况下,也可通过调用它显示整个验证平台的拓扑结构是否与自己预期的一致。因此可以把其放在所有测试用例的基类base_test中。
8.3 常用的重载
8.3.1 重载transaction
在有了factory机制的重载功能后,构建CRC错误的测试用例就多了一种选择
假设有如下的正常sequence,此sequence被作为某个测试用例的default_sequence:
1 | |
现在要构建一个新的异常的测试用例测试CRC错误的情况。可以从这个transaction派生一个新的transaction:
1 | |
如果按照上节内容,那么现在需要新建一个sequence,然后将这个sequence作为新的测试用例default_sequence:
1 | |
但有了factory机制的重载功能后,可以不用重新写一个abnormal_sequence,而继续使用normal_sequence作为新的测试用例的default_sequence,只是需要将my_transaction使用crc_err_tr重载:
1 | |
经过这样的重载后,normal_sequence产生的transaction就是CRC错误的transaction。这比新建一个CRC错误的sequence的方式简练了很多
我的总结
就是通过factory机制的重载,实现了父类my_transaction中函数的被重载(感觉确实很强大!)
8.3.2 重载sequence
上节使用的transaction重载能工作的前提是约束也可以重载。但很多人可能并不习惯于这种用法,而习惯于最原始的方法
本节讲述的内容其实与上节的类似,都能实现同样的目的。这就是UVM的强大之处,对于同样的事情,它提供多种方式完成,用户可以自由选择
在其他测试用例中已经定义了如下的两个sequence:
1 | |
这里使用了嵌套的sequence。case_sequence被作为default_sequence。现在新建一个测试用例时,可以依然将case_sequence作为default_sequence,只需要从normal_sequence派生一个异常的sequence:
1 | |
并且在build_phase中将normal_sequence使用abnormal_sequence重载掉:
1 | |
8.3.3 重载component
前面分别使用重载transaction和重载sequence的方式产生异常的测试用例。其实还可以使用重载driver的方式产生
在本节所举的例子中看不出重载driver的优势,因为CRC错误是一个非常普通的异常测试用例。对于那些特别异常的测试用例,异常到使用sequence实现起来非常麻烦的情况,重载driver就会显示出其优势
假设某个测试用例使用normal_sequence作为其default_sequence。这是个只产生正常transaction的sequence,使用它构造的测试用例是正常的用例。现在假如要产生一个CRC错误的测试用例,可以依然使用这个sequence作为default_sequence,只是需要定义如下的driver:
1 | |
然后在build phase中将my_driver使用crc_driver重载:
1 | |
参考模型的重载
除driver可以重载外,scoreboard与参考模型等都可以重载。
尤其对于参考模型来说,处理异常的激励源是相当耗时的事情。可能一个DUT80%的代码都是用于处理异常情况,作为模拟DUT的参考模型来说更是如此。如果将所有异常情况都用一个参考模型实现,那么其代码量将会非常大。但如果将其分散为数十个参考模型,每个处理一种异常情况,当建立相应异常的测试用例时,将正常的参考模型由它替换掉。这样可使代码清晰并增加可读性。
8.3.4 不推荐重载driver以实现所有的测试用例
重载driver使得一些在sequence中比较难实现的测试用例轻易地在driver中实现。那么如果放弃sequence,只使用factory机制实现测试用例可能吗?答案确实是可能的。不用sequence时,那么要在driver中控制发送包的种类、数量,对于objection的控制又要从sequence中回到driver中,似乎一切都回到了起点。
但不推荐这么做:
- 引入sequence的原因是将数据流产生的功能从driver中独立出来。取消sequence相当于一种倒退,会使得driver的职能不明确,与现代编程中模块化、功能化的趋势不合。
- 虽然用driver实现某些测试用例比sequence更加方便,但对于另外一些测试用例,在sequence里做起来会比driver中更加方便
- sequence的强大之处在于,它可以在一个sequence中启动另外的sequence,从而可以最大程度实现不同测试用例之间sequence的重用。但driver要实现这样的功能,只能将一些基本的产生激励的函数写在基类driver中。用户会发现到最后这个driver的代码量非常恐怖
- 使用virtual sequence可以协调、同步不同激励的产生。当放弃sequence时,在不同的driver之间完成这样的同步则比较难
基于以上原因,请不要将所有测试用例都使用driver重载实现。只有将driver的重载与sequence相结合,才与UVM的最初设计初衷相符合,才能构建起可重用性高的验证平台。完成同样的事情有很多种方式,应综合考虑选择最合理的方式
8.4 factory机制的原理与接口
factory机制的本质
在没有factory机制之前要创建一个类的实例,只能使用new函数
但有了factory机制之后,可以根据类名创建这个类的一个实例;还可以在创建类的实例时根据是否有重载记录来决定是创建原始的类,还是创建重载的类的实例
所以从本质上来看,factory机制其实是对SV中new函数的重载。因为这个原始的new函数实在太简单且功能太少。经过factory机制的改良之后,进行实例化的方法多了很多。这也体现了UVM编写的一个原则,一个好的库应该提供更多方便实用的接口,这种接口一方面是库自己写出来并开放给用户的,另外一方面就是改良语言原始的接口,使得更加方便用户的使用
8.4.1 创建一个类的实例的方法
原文中在这里就是使用SV的new创建了一个实例。。。
8.4.2 根据字符串来创建一个类
factory机制根据字符串创建类的实例是如此强大,那么它是如何实现的呢?要实现这个功能,需要用到参数化的类。假设有如下的类:
1 | |
在定义一个类(如my_driver)时,同时声明一个相应的registry类及其成员变量:
1 | |
向这个registry类传递了新定义类的类型及类的名称,并创建了这个registry类的一个实例。在创建实例时,把实例的指针和”mydriver”的名字放在一个联合数组global_tab中。上述的操作基本就是`uvmutils
宏所实现的功能,只是uvm_utils`宏做得更多、更好
当要根据类名”my_driver”创建一个my_driver的实例时,先从global_tab中找到”my_driver”索引对应的registry#(my_driver,”my_driver”)实例的指针me_ptr,然后调用me_ptr.inst=new()函数,最终返回me_ptr.inst**。整个过程如下:
1 | |
基本上使用factory机制根据类名创建一个类的实例的方式就是这样。真正的factory机制实现起来会复杂很多,这里只是为了说明而将它们简化到了极致
8.4.3 用factory机制创建实例的接口
factory机制提供了一系列接口来创建实例:
| 函数名 | 所属类(可用的全局变量) | 作用 | 其他 |
|---|---|---|---|
| create_object_by_name函数 | uvm_factory(factory) | 根据类名字创建一个object | |
| create_object_by_type函数 | uvm_factory(factory) | 根据类型创建一个object | |
| create_component_by_name函数 | uvm_factory(factory) | 根据类名创建一个component | 一般只在一个component的new或build_phase中使用 |
| create_component_by_type | uvm_factory(factory) | 根据类型创建一个component | 一般只在一个component的new或build_phase中使用 |
| create_component | uvm_component |
1.create_object_by_name()
用于根据类名字创建一个object,其原型为:
1 | |
一般只使用第一个参数,使用示例:
1 | |
2.create_object_by_type()
根据类型创建一个object,其原型为:
1 | |
一般只使用第一个参数,使用示例:
1 | |
3.create_component_by_name()
根据类名创建一个component,其原型为:
1 | |
有四个参数,在调用这个函数时,这四个参数都要使用:
- 第一个参数是字符串类型的类名
- 第二个参数是父结点的全名
- 第三个参数是为这个新的component起的名字
- 第四个参数是父结点的指针
使用示例:
1 | |
使用phase:
- 这个函数一般只在一个component的new或build_phase中使用
- 如果是在一个object中被调用则很难确认parent参数
- 如果是在connect_phase之后调用,由于UVM要求component在build_phase及之前实例化完毕,所以会调用失败
4.create_component()
调用了create_component_by_name(),原型为:
1 | |
只有两个参数,factory.create_component_by_name()中剩余的两个参数分别就是this和this.get_full_name()
5.create_component_by_type()
根据类型创建一个component,其原型为:
1 | |
其参数与create_component_by_name()类似,也需要四个参数齐全
使用示例:
1 | |
2023年2月2日 3:35:23
第九章 UVM中代码的可重用性
本章主要内容:
- callback机制
- 参数化的类
- 模块级、芯片级验证范例!(9.4节)
9.1 callback机制
callback在UVM中的主要作用:
- callback机制的最大用处就是提高验证平台的可重用性。很多情况下验证人员期望在一个项目中开发的验证平台能够用于另外一个项目。但通常来说完全的重用是比较难实现的,两个项目之间或多或少会有一些差异。如果把两个项目不同的地方使用callback函数来做,而把相同的地方写成一个完整的env,这样重用时只要改变相关callback函数env可完全的重用
- callback机制还用于构建异常的测试用例。只是在UVM中构建异常的测试用例有很多种方式,如factory机制的重载,callback机制只是其中的一种
9.1.1 广义的callback函数
书上讲的:
举了一个
post_randomize()的应用例子分析了与callback的关系:
post_randomize的例子似乎与本节引语中提到的callback机制不同,引语中强调两个项目之间。不过如果将SV语言的开发过程作为一个项目A,验证人员使用SV开发的是项目B。A的开发者预料到B可能会在randomize()函数完成后做一些事情,于是A给SystemVerilog添加了post_randomize()函数。B如A所料,使用了这个callback函数
我的理解:
本节介绍了post_randomize()回调函数,虽然与9.1引言强调项目之间的重用不同,但也能解释的通
callback函数
SV中:post_randomize()、pre_randomize()等
UVM中:pre_body()和post_body(),除此之外还有pre_do()、mid_do()和post_do()
9.1.2 callback机制的必要性
程序是固定的,其设计者有时不是使用者,所以作为使用者来说总希望程序的设计者能够提供一些接口满足自己的应用需求。作为这两者之间的协调,callback机制出现了。如上面例子,如果SV的设计者一意孤行只提供randomize函数,此函数执行完成之后就完成任务不做任何事情。幸运的是他听取意见加入了一个post_randomize的callback函数,这样可以使用户实现各自的想法
由上例可以看出:
- 程序的开发者其实是不需要callback机制的,它完全是由程序的使用者要求的
- 程序的开发者必须能够准确地获取使用者的需求,知道使用者希望在程序的什么地方提供callback函数接口,如果无法获取使用者的需求,那么程序的开发者只能尽可能地预测使用者的需求
对于VIP(Verification Intellectual Property)来说,一个很容易预测到的需求是在driver中,在发送transaction之前,用户可能会针对transaction做某些动作,因此应该提供一个pre_tran的接口,如用户A可能在pre_tran中将要发送内容的最后4个字节设置为发送的包的序号,这样在包出现比对错误时可以快速地定位,B用户可能在整个包发送之前先在线路上发送几个特殊的字节,C用户可能将整个包的长度截去一部分……总之不同的用户会有不同的需求。正是callback机制的存在满足了这种需求,扩大了VIP的应用范围
除上述情形外,还存在构建异常测试用例的需求。前面已经展示过多种构建异常测试用例的方式。如果在driver中实现测试用例,那么需要使用多个分支处理这些异常情况。在有callback机制的情况下,把异常测试用例的代码使用callback函数实现,而正常测试用例则正常处理。使用这种方式可以让driver的代码非常简洁。在没有factory机制的重载功能之前,使用callback函数构建异常测试用例是最好的实现方式
总结上面两段,callback在UVM中的主要作用有两个:
- 实现多种功能:VIP的设计者与使用者,实现多种功能
- 使代码更简洁:
9.1.3 callback机制原理
原文讲了如何使用SV手撸一个实现callback的场景,该实现没有使用factory机制重载,而是通过定义一个新类,并通过该类的衍生类的重载,实现callback的。在这个过程中,为了让调用callback的类得到重载后的实例,交代了一个概念A_pool
具体细节,如下
考虑如下pre_tran()这个callback函数/任务:
1 | |
假设这是一个成熟VIP中的driver,那么考虑如何实现pre_tran的callback函数/任务呢?它应该是my_driver的一个函数/任务。如果按照上面post_randomize的经验,那么应该从my_driver派生一个类new_driver,然后重写pre_tran这个函数/任务
但这种想法是行不通的,因为这是一个完整的VIP,虽然从my_driver派生了new_driver,但这个VIP中正常运行时使用的依然是my_driver,而不是new_driver。new_driver这个派生类根本就没有实例化过,所以pre_tran从来不会运行。当然,可以使用factory机制的重载功能,但那样是factory机制的功能,而不是callback机制的功能,所以暂不考虑factory机制的重载功能
为解决这个问题,尝试新引入一个类:
1 | |
这样可以避免重新定义一次my_driver,只需要重新定义A的pre_tran即可。重新派生A的代价是要远小于my_driver的
使用时只要从A派生一个类并将其实例化,然后重新定义其pre_tran函数,此时callback机制的目的就达到了
虽然看起来似乎一切顺利,但实际却忽略了一点。因为从A派生了一个类并实例化,但作为my_driver来说,怎么知道A派生了一个类呢?又怎么知道A实例化了呢?为应付这个问题,UVM中又引入了一个类,假设这个类称为A_pool,意思就是专门存放A或者A的派生类的一个池子。UVM约定会执行这个池子中所有实例的pre_tran函数/任务,即:
1 | |
这样在使用时,只要从A派生一个类并将其实例化,然后加入到A_pool中,那么系统运行到上面的foreach(A_pool[i])语句时,将会知道加入了一个实例,于是就会调用其pre_tran函数/任务
有了A和A_pool,真正的callback机制就可以实现了。UVM中的callback机制与此类似,不过其代码实现非常复杂
9.1.4 UVM中使用callback机制
1.两个项目
在这里我们要使用UVM的callback机制来实现重载,首先我们要确定的两个不同的项目A、B,这两个项目经过上一节的分析可以是:
- A:VIP的开发者(可以是开发验证平台、组件的人员),需要留出callback接口
- B:VIP的使用者(可以是编写测试用例的人员),需要使用callback接口
2.callback机制步骤总结
对于VIP的开发者来说,预留一个callback函数/任务接口时需要做以下几步:
- 定义:定义一个回调类型A,内部定义虚函数用作接口
- 注册:在调用位置的D类内,使用
`uvm_register_cb宏进行注册 - 调用:在要调用回调函数/任务接口的函数/任务中,使用
`uvm_do_callbacks宏调用
对于VIP的使用者来说,需要做如下几步:
- 定义:从A派生一个类my_A,在这个类中重载接口函数
- 添加:在测试用例的connect_phase(或其他phase,但一定要在使用此callback函数/任务的phase之前)中将从A派生的类实例化,使用
`uvm_callbacks#(D, my_A)::add(xxx.xxx.d, ins_my_a)将其加入A_pool中
为了方便VIP使用者调用,开发者可以声明一个A_pool来替代使用到的`uvm_callbacks#(D, my_A)调用:
1 | |
3.实例讲解
要实现真正的pre_tran,需要首先定义上节所说的类A(1):
1 | |
定义callback的父类A的步骤:
- A类一定要从uvm_callback派生
- 另外还需要定义一个pre_tran的任务,此任务的类型一定要是virtual的,因为从A派生的类需要重载这个任务
接下来声明一个A_pool类(2):
1 | |
A_pool的声明相当简单,只需要一个typedef语句即可。另外在这个声明中除了要指明这是一个A类型的池子外,还要指明这个池子将会被哪个类使用。本例中my_driver将会使用这个池子,所以要将此池子声明为my_driver专用的
之后,在my_driver中要做如下声明(3):
1 | |
这个声明与A_pool的类似,要指明my_driver和A
最后,在my_driver的main_phase中调用pre_tran时并不如上节所示的那么简单,而是调用了一个宏来实现(4):
1 | |
`uvm_do_callbacks宏的参数:
- 第一个参数是调用pre_tran的类的名字,这里自然是my_driver
- 第二个参数是哪个类具有pre_tran,这里是A
- 第三个参数是调用的是函数/任务,这里是pre_tran,指明是pre_tran时要顺便给出pre_tran的参数
到目前为止是VIP的开发者应该做的事情,作为使用VIP的用户来说,需要做如下事情:
首先从A派生一个类(1):
1 | |
其次,在测试用例中将my_callback实例化,并将其加入A_pool中(2):
1 | |
为什么在connect_phase实例化?
my_callback的实例化是在connect_phase中完成的,实例化完成后需要将
my_cb加入A_pool中。同时在加入时需要指定是给哪个my_driver使用的。因为很可能整个base_test中实例化了多个my_env,从而有多个my_driver的实例,所以要将my_driver的路径作为add函数的第一个参数
至此,一个简单的callback机制示例就完成了。这个示例几乎涵盖UVM中所有可能用到的callback机制的知识,大部分callback机制的使用都与这个例子相似
总结:对于VIP的开发者来说,预留一个callback函数/任务接口时需要做以下几步:
- 定义一个A类
- 声明一个A_pool类
- 在要预留callback函数/任务接口的类中调用
`uvm_register_cb宏,怼 - 在要调用callback函数/任务接口的函数/任务中,使用uvm_do_callbacks宏
对于VIP的使用者来说,需要做如下几步:
- 从A派生一个类,在这个类中定义好pre_tran
- 在测试用例的connect_phase(或其他phase,但一定要在使用此callback函数/任务的phase之前)中将从A派生的类实例化,并将其加入A_pool中
4.分工分析
本节的my_driver是自己写的,my_case0也是自己写的。完全不存在VIP与VIP使用者的情况。不过换个角度来说,可能有两个验证人员共同开发一个项目,一个负责搭建测试平台(testbench)及my_driver等的代码,另一位负责创建测试用例。负责搭建测试平台的人员为搭建测试用例的人员留下了callback函数/任务接口。即使my_driver与测试用例都由同一个人来写,也完全可以接受
因为不同测试用例肯定会引起不同driver的行为。这些不同的行为差异可以在sequence中实现,也可在driver中实现。在driver中实现时既可以用driver的factory机制重载,也可使用callback机制
9.1.5 子类继承父类的callback机制
1.问题背景
考虑如下情况:
某公司有前后两代产品,第一代产品已经成熟,有一个已经搭建好的验证平台,要在此基础上开发第二代产品,需搭建一个新验证平台
这个新验证平台大部分与旧验证平台一致,只是需要扩展my_driver的功能,即需要从原来的driver中派生一个新的类new_driver。另外需保证第一代产品的所有测试用例在尽量不改动的前提下能在新验证平台上通过
第一代产品的测试用例中大量使用了callback机制。由于callback池(即A_pool)在声明时指明了这个池子只能装载用于my_driver的callback。那怎样才能使原来的callback函数/任务能用于new_driver中呢?
这就牵扯到子类继承父类的callback函数/任务问题
我的理解
原来验证环境中,调用回调函数的类D,需要新的功能,因此派生出了new_D,但是如何让D中调用的回调函数,在newD中可以照样调用呢?使用子类继承父类的callback机制
2.子类继承父类的callback机制
这个问题是站在VIP重新设计者的角度,没有对回调内容进行更改,而是调用回调函数的类进行了转移
我们的步骤是,在新的类D中:
- 重新注册:使用宏
`uvm_set_super_type把子类和父类关联在一起 - 重新调用:使用宏
`uvm_do_callbacks重新调用回调函数(`uvm_do_callbacks内参数不用变)
2.实例讲解
my_driver使用上节中的定义,在此基础上派生新的类new_driver(1):
1 | |
这里使用
`uvm_set_super_type宏,把子类和父类关联在一起:
- 第一个参数是子类
- 第二个参数是父类
在main_phase中调用
`uvm_do_callbacks宏时:
- 其第一个参数是my_driver而不是new_driver,即调用方式与在my_driver中一样(意思是,如果
pre_tran(this,req)的this参数没有要求,可以直接不用对原有代码进行修改?我猜的)
在my_agent中实例化此new_driver(2):
1 | |
这样,上节的my_case0不用经过任何修改就可以在新的验证平台上通过
9.1.6 callback替代sequence
可以在pre_tran中做很多事情,那么是否可以将driver中的drive_one_pkt也移到pre_tran中呢?答案是可以的。更进一步,将seq_item_port.get_nex_item移到pre_tran中也是可以的。
其实完全可以不用sequence,只用callback函数/任务就可实现所有测试用例。假设A类定义如下:
1 | |
在my_driver的main_phase中去掉所有其他代码,只调用A的run:
1 | |
在建立新的测试用例时,只需要从A派生一个类,并重载其gen_tran函数:
1 | |
这种情况下新建测试用例相当于重载gen_tran。如果不满足要求,还可以将A类的run任务重载
在这个示例中完全丢弃了sequence机制,在A类的run任务中进行控制objection,激励产生在gen_tran中
9.1.7 callback机制、sequence机制和factory机制
上一节使用callback函数/任务实现所有测试用例,几乎完全颠覆从头到尾一直在强调的sequence机制。再到上一章,使用factory机制重载driver来实现所有测试用例的情况
callback机制、sequence机制和factory机制在某种程度上来说很像,它们都能实现搭建测试用例的目的。只是sequence机制是UVM一直提倡的生成激励的方式,UVM为此做了大量的工作,如构建了许多宏、嵌套的sequence、virtual sequence、可重用性等
factory机制列出的那四条理由,依然适用于callback机制。虽然callback机制能够实现所有的测试用例,但某些测试用例用sequence实现更加方便。virtual sequence的协调功能在callback机制中就很难实现
callback机制、sequence机制和factory机制并不是互斥的,三者都能分别实现同一目的。当这三者互相结合时,又会产生许多新的解决问题的方式。如果在建立验证平台和测试用例时,能够择优选择其中最简单的一种实现方式,那么搭建出来的验证平台一定是足够强大、足够简练的。实现同一事情有多种方式,为用户提供了多种选择,高扩展性是UVM取得成功的一个重要原因
我的理解
如何选择这三个机制:
- 择优选择其中最简单的一种实现方式
sequence不可替代的原因:
- UVM一直提倡的生成激励的方式,UVM为此做了大量的工作,如构建了许多宏、嵌套的sequence、virtual sequence、可重用性等
- 某些测试用例用sequence实现更加方便
- virtual sequence的协调功能在callback机制中就很难实现
补充:我对SV与UVM中的callback实现的不同的理解
- SV完全是通过重载虚方法实现的,在调用处使用父类句柄调用子类方法,是一种不完全的回调
- UVM的回调机制则分离了VIP设计者与VIP使用者,通过VIP设计者插入和调用,以及VIP使用者继承和注册实现
9.2 功能的模块化:小而美
9.2.1 Linux的设计哲学:小而美
广大IC开发者中,使用Linux的用户占绝大部分,尤其对验证人员来说更是如此。Linux+如此受欢迎的部分原因之一是它提供了众多的工具,如ls命令、grep命令、wc命令、echo命令等,使用这些命令的组合可以达到多种目的。这些小工具的共同点是每个都非常小但功能清晰。它们是Linux设计哲学中小而美的典型代表。
与小而美相对的就是大而全。比如下述命令就完全可以使用一个命令实现:
1 | |
这个命令组合起来相当于集合了ls、grep、wc三个命令的参数,将这个命令命名为lsgrepwc。当查看这个命令的用法时,很多用户会被冗长的参数列表吓坏。当看到一个参数时,用户要自己判断这个参数属于三个功能中的哪一个。多出来的判断时间就是用户为大而全付出的时间
小而美的本质是功能模块化、标准化,但小不一定意味着美。以前面的ls与grep命令为例,如果当初命令设计者取了ls一半的功能和grep一半的功能组成命令lgr,剩下的功能再拼凑成sep,这两个是什么命令?恐怕没有几个人会知道,这样的设计不知道会令多少用户崩溃。所以小而美的前提是功能模块划分要合理,一个不合理的划分是谈不上美的
同时,小而美也不能无限制地追求小。以ls为例,如果将ls、ls-a、ls-l分别当成三个不同的命令,那么也是一种不合理的划分。这三个新的命令有太多共同的参数,比如–color参数等。拆分的同时,参数却是原样拷贝到三个新的命令中,造成了参数的冗余
在验证平台的设计中要尽量做到小而美,避免大而全
9.2.2 factory重载的小而美
要点
factory的重载机制时,被重载的A类应该尽可能多的进行任务/函数的小型化,从而避免在重载过程中大段的代码复制
下面随便看看
factory机制重要的一点是提供重载功能。一般来说,如果要用B类重载A类,那么B类是要派生自A类的。在派生时要保留A类的大部分代码,只改变其中一小部分
假设原始A_driver的drive_one_pkt任务如下:
2
3
4
5task A_driver::drive_one_pkt;
drive_preamble();
drive_sfd();
drive_data();
endtask上述代码将一个drive_one_pkt任务又分成了三个子任务。现在如果要构造一个sfd错误的例子,那么只需要从A_driver派生一个B_driver,并且重载其drive_sfd任务即可
如果上述代码不是分成三个子任务,而是一个完整的任务:
2
3
4
5
6
7
8task A_driver::drive_one_pkt;
//drive preamble
…
//drive sfd
…
//drive data
…
endtask那么在B_driver中需要重载的是drive_one_pkt这个任务:
2
3
4
5
6
7
8task B_driver::drive_one_pkt;
//drive preamble
…
//drive new sfd
…
//drive data
…
endtask此时,drive preamble和drive data部分代码需要复制到新的drive_one_pkt中。对于程序员来说要尽量避免复制的使用:
- 在复制中由于不小心,很容易出现各种各样的错误。虽然这些错误只是短期的,马上就能修订,但毕竟要为此花费额外的时间
- 从长远来看,如果drive data相关的代码稍微有一点变动,此时A_driver和B_driver的drive_one_pkt都需要修改,这又需要额外花费时间。同样的代码只在验证平台上出现一处,如果要重用,将它们封装成可重载的函数/任务或者类
9.2.3 放弃建造强大sequence的想法
UVM的sequence功能非常强大,很多用户喜欢将他们的sequence写得非常完美,他们的目的是建造通用的sequence,有些用户甚至执着于一个sequence解决验证平台中所有的问题,使用时只需要配置参数即可
以一个my_sequence为例,有些用户可能希望这个sequence具有下列功能:
- 能够产生正常的以太网包
- 通过配置参数产生CRC错误的包
- 通过配置参数产生sfd错误的包
- 通过配置参数产生preamble错误的包
- 通过配置参数产生CRC与sfd同时错误的包
- 通过配置参数产生CRC与preamble同时错误的包
- 通过配置参数产生sfd与preamble同时错误的包
- 通过配置参数产生CRC、sfd与preamble同时错误的包
- 通过配置参数控制错误的概率
- 通过配置参数选择要发送的数据是随机化的还是从文件读取
- 通过配置参数选择如果从文件读取,那么是多文件还是单文件
- 通过配置参数选择如果从文件读取,那么使用哪一种文件格式
- 通过配置参数选择是否将发送出去的包写入文件中
- 通过配置参数选择长包、中包、短包各自的阈值长度
- 通过配置参数选择长包、中包、短包的发送比例通过配置参数选择是否在包的负载中加入当前要发送的包的序号,以便于调试
……
上述sequence确实是一个非常通用、强悍的sequence。但这个sequence存在两个问题:
- 这个sequence代码量非常大,分支众多,后期维护相当麻烦。如果代码编写者与维护者不是同个人,那么对维护者来说简直就是灾难。即使代码编写者与维护者是同个人,在一段时间之后自己也可能被自己以前写的东西感到迷惑不已
- 使用这个sequence的人面对如此多的参数要如何选择呢?他有时只想使用其中最基本的一个功能但却不知道怎么配置,只能所有参数都看一遍。如果看一遍能看懂还好,但有时即使看两三遍也看不懂
如果用户非常坚持上述超级强大的sequence,那么请一定要做到以下两点之一:
- 有一份完整的文档介绍它
- 有较多的代码注释
文档的重视程度因公司而异,目前国内外的IC公司对于验证文档的重视普遍不够,很少有公司会为一个sequence建立专门的文档。当代码完成后很少会有代码编写者愿意再写文档。即使公司制度规定必须写,文档的质量也有高低之分且存在文档的后期维护问题。当sequence建立后为其建一个文档,但后来sequence升级,文档却没有升级。文档与代码不一致,这是目前IC公司中经常存在的问题
代码的注释与代码编写者的编码习惯有关。目前仅有少数编码习惯好的人能做到质量较好的注释。验证人员编写的代码通常比较灵活且更新频率较快。当设计变更时相关的验证代码就要变更。很多验证人员并没有写注释的习惯,即使有写注释,但当后来代码变更时,注释可能已经落伍了
因此强烈建议不要使用强大的sequence。可将一个强大的sequence拆分成小的sequence,如:
- normal_sequence
- crc_err_sequence
- rd_from_txt_sequence
……
尽量做到一看名字就知道这个sequence的用处,这样可以最大程度上方便自己,方便大家
9.3 参数化的类
9.3.1 参数化类的必要性
代码的重用分为很多层次。凡是在某个项目中开发的代码用于其他项目,都可以称为重用,如:
- A用户在项目P中的代码被A用户自己用于项目P
- A用户在项目P中的代码被A用户自己用于项目Q
- A用户在项目P中的代码被B用户用于项目Q
- A用户在项目P中开发的代码被B用户或者更多的用户用于项目P或项目Q
以上四种应用场景对代码可重用性的要求逐渐提高。第一种可能只是几个sequence被几个不同的测试用例使用;在最后一种可能A用户开发的是一个总线功能模型,大家都会重用这些代码
为了增加代码的可重用性,参数化的类是一个很好的选择
UVM广泛使用了参数化的类。对用户来说使用最多的参数化的类莫过于uvm_sequence,其原型为:
1 | |
在派生uvm_sequence时指定参数的类型,即transaction的类型,可以方便产生transaction并建立测试用例。 除了uvm_sequence外,还有uvm_analysis_port等,不再一一列举
相比普通的类,参数化的类在定义时会有些复杂,其古怪的语法可能会使人望而却步。并非所有类一定要定义成参数化的类。对于很多类来说根本没有参数可言,如果定义成参数化的类,根本没有任何优势可言。所以定义成参数化的类的前提是这个参数是有意义的、可行的
9.3.2 UVM中的参数化
1.factory中的参数化
UVM对参数化类的支持首先体现在factory机制注册上。前面已经提到了`uvm_object_param_util和`uvm_component_param_utils这两个用于参数化的object和参数化的component注册的宏
2.config_db中的参数化
UVM的config_db机制可以用于传递virtual interface。SV支持参数化的interface:
1 | |
config_db机制同样支持传递参数化的interface:
1 | |
3.sequence中的参数化
sequence机制同样支持参数化的transaction:
1 | |
4.有默认参数的类
很多参数化的类都有默认参数,用户在使用时经常会使用默认参数。但UVM的factory机制不支持参数化类中的默认参数。假如有如下的agent定义:
1 | |
在声明agent时可以按照如下写法来省略参数:
1 | |
但在实例化时必须将省略的参数加上:
1 | |
9.4 模块级到芯片级的代码重用
9.4.1 基于env的重用
现代芯片的验证通常分为两个层次:
- 模块级别(block level,也称IP级别、unit级别)验证
- 芯片级别(也称SOC级别)验证
一个大的芯片在开发时是分成多个小模块来开发的。每个模块开发一套独立的验证环境,通常每个模块有专门的验证人员负责。当在模块级别验证完成后需要做整个系统的验证
为简单起见,假设某芯片分成了三个模块,如图所示:
这三个模块在模块级别验证时,分别有自己的driver和sequencer,如图9-2所示:
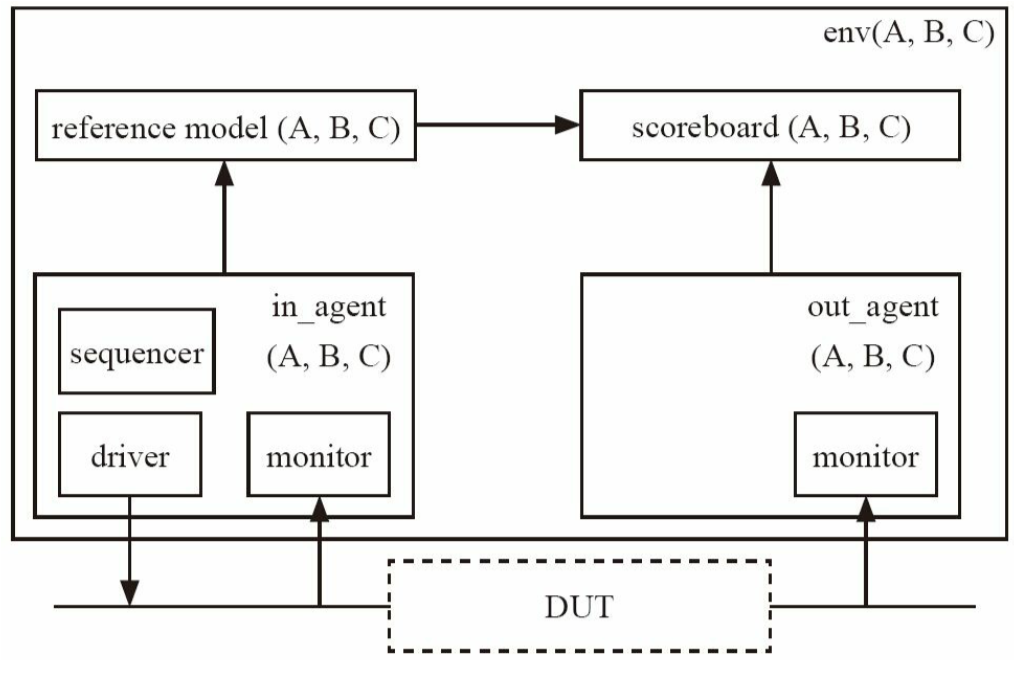
当在芯片级别验证时,如果采用env级别的重用,那么B和C中的driver分别取消(因为芯片级按照设计,只有A一个输入),这可以通过设置各自i_agt的is_active来控制, 如图9-3所示:
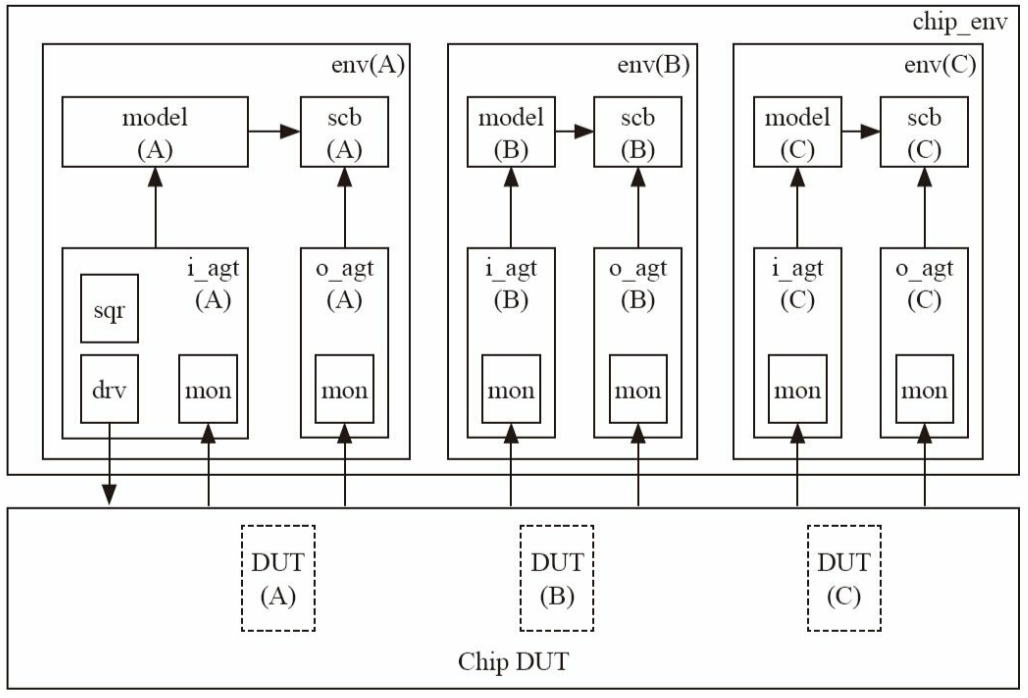
仔细观察图9-3,发现o_agt(A)和i_agt(B)两者监测的是同一接口,换言之,二者应该是同一个agent。在模块级别验证时,i_agt(B)被配置为active模式,在图9-3中则被配置为passive模式。被配置为passive模式的i_agt(B)其实和o_agt(A)完全一 样,二者监测同一接口,对外发出同样的transaction。或者说,其实可以将i_agt(B)取消,model(B)的数据来自o_agt(A)。o_agt(B)和i_agt(C)也是同样的情况。取消了i_agt(B)和i_agt(C)的芯片级别验证平台如图9-4所示:
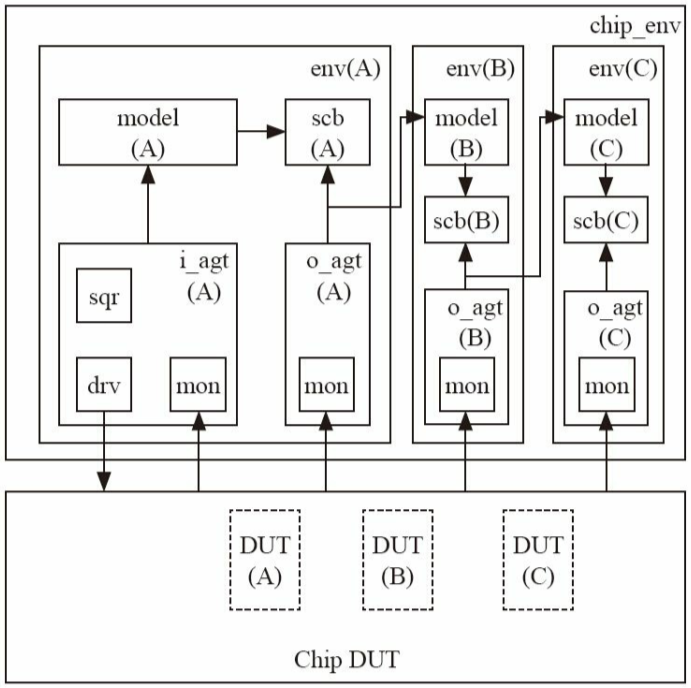
为了实现上面的结构,每个模块验证需要在其env中添加一个analysis_port用于数据输出;添加一个analysis_export用于数据输入;在env中设置in_chip用于辨别不同的数据来源(0为外部输入芯片,1则是验证平台内部):
1 | |
在chip_env中,实例化env_A、env_B、env_C,将env_B和env_C的in_chip设置为1,并将env_A的ap口与env_B的i_export相连, 将env_B的ap与env_C的i_export相连接:
1 | |
上面两种芯片级别验证平台各有其优缺点。前者的验证平台的各个env之间没有数据交互,从而各个env不必设置analysis_port及analysis_export,在连接上简单些。但推荐使用后者(9-4)的验证平台
- 整个验证平台中消除了冗余的monitor,这在一定程度上可以加快仿真速度
- 不同模块的验证环境之间有数据交互时,可以互相检查对方接口数据是否合乎规范。如A的数据送给了B,而B无法正常工作,那么要么是A收集的数据是错的,不符合B的要求,要么就是A收集的数据是对的,但B对接口数据理解有误
9.4.2 寄存器模型的重用
上节的重用中并没有考虑总线的重用。一般每个模块会有自已的寄存器配置总线。在集成到芯片时芯片有自己的配置总线,这些配置总线经过仲裁之后分别连接到各个模块,如下图所示:
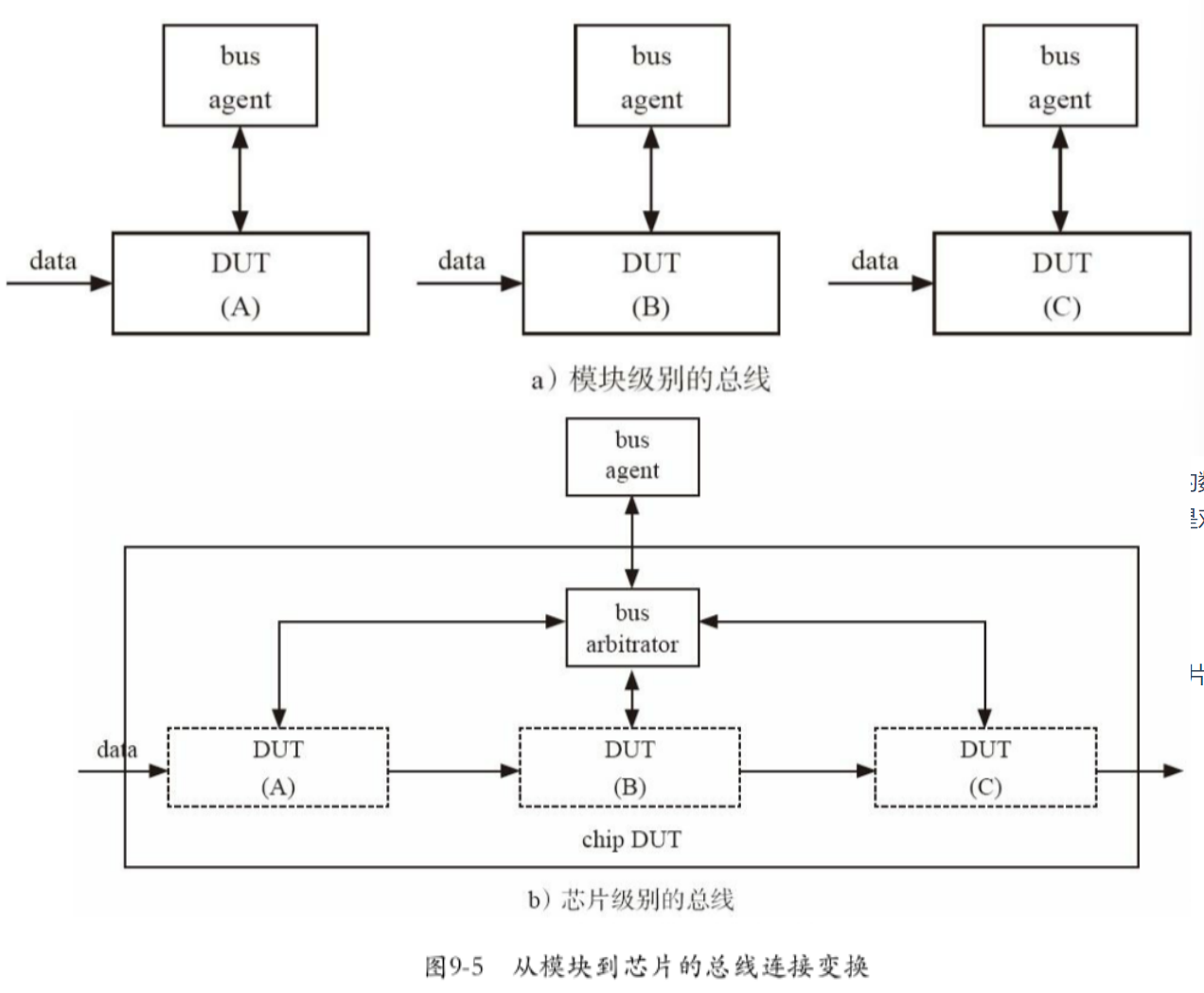
在图7-1中,bus_agt是作为env的一部分的。但是从图9-5可以看出,这样的一个env是不可重用的,下图为7-1:
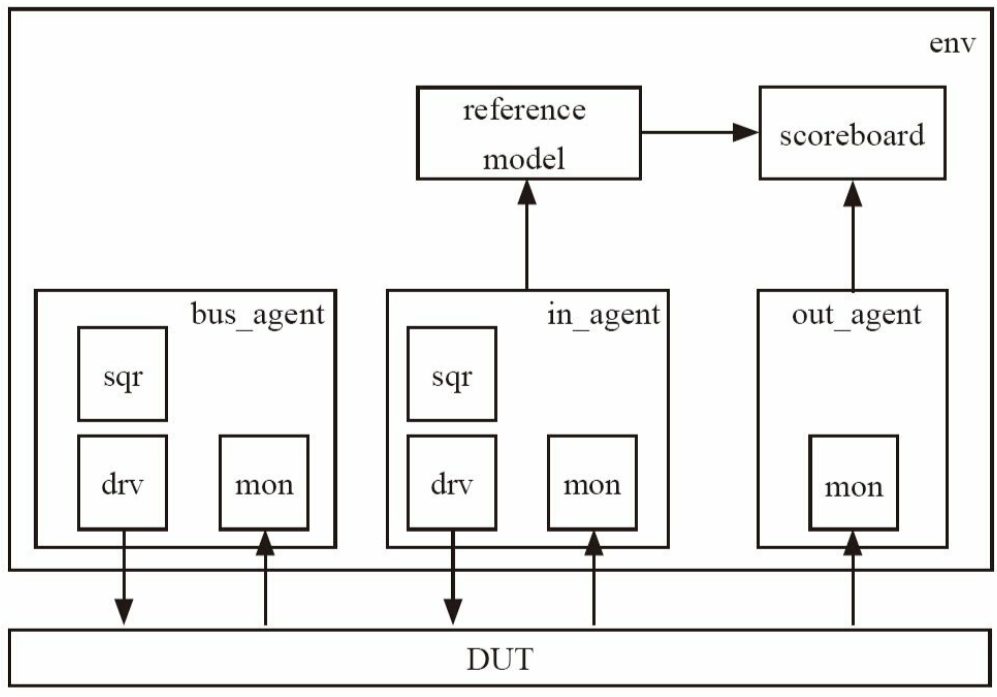
因此,为了提高可重用性(即实现env的重用),在模块级别时,图7-1的bus_agt应该从env中移到base_test中,如图9-6所示:
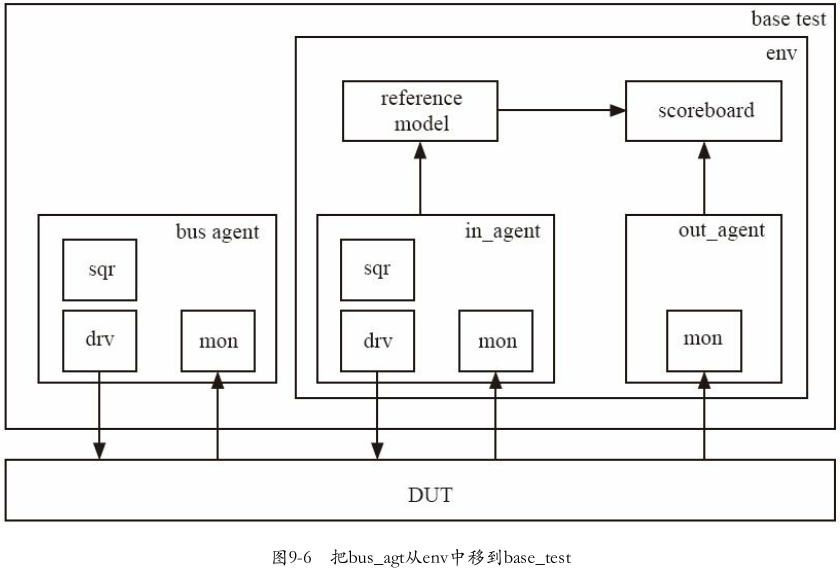
与bus_agt对应的是寄存器模型。在模块级别验证时,每个模块有各自的寄存器模型。很多用户习惯于在env中实例化寄存器模型:
1 | |
但如果要实现env级别的重用,就不能在env中实例化寄存器模型。每个模块都有其偏移地址,如A的偏移地址可能是'h0000,B是'h4000,C是'h8000(即16位地址的高两位用于辨识不同模块)。如果在env级例化寄存器模型,那么在芯片级时不能指定其偏移地址。因此在模块级验证时需要在base_test中实例化寄存器模型,在env中设置一个寄存器模型的指针,在base_test中对它赋值
我的理解
如果直接在env中实例化寄存器模型,而不是base_test,则每个模块的env都有对应的寄存器模型,访问也不需要指定偏移地址直接访问即可,最终导致与设计不符!
为了在芯片级别使用寄存器模型,需建立一个新的寄存器模型:
1 | |
这个新的寄存器模型中只需加入各个不同模块的寄存器模型并设置偏移地址和后门访问路径。建立芯片级寄存器模型的方式与建立多层次的寄存器模型一致
在chip_env中实例化此寄存器模型,并将各个模块的寄存器模型的指针赋值给各个env的p_rm:
1 | |
加入寄存器模型后,整个验证平台的框图变为下图所示的形式:
9.4.3 virtual sequence与virtual sequencer中的重用
对于9.4.1节的例子来说,每个模块的virtual sequencer分为两种情况:
- 一种是只适用于模块级别,不能用于芯片级别;
- 另外一种是适用于模块和芯片级别
前者的代表是B和C的virtual sequencer,后者的代表是A中的virtual sequencer。B和C的virtual sequencer不能出现在芯片级的验证环境中;A模块比较特殊是一个边界模块,它的virtual sequencer可以用于芯片级别验证中。所以不应在env中实例化virtual sequencer,而应在base_test中实例化(因为在env中实例化vsqr后,则无法对env进行重用,因为芯片级验证中B和C中是不需要vsqr的)
但前面只是一个简单的例子。现代的大型芯片可能不只一个边界输入,如下图所示:
D和F分别是边界输入模块。在整个芯片的virtual sequencer中,应该包含A、D和F的sequencer。因此A、D和F的virtual sequencer是不能直接用于芯片级验证的
无论是像B、C、E这样的内部模块还是A、D、F这样的边界输入模块,统一推荐其virtual sequencer在base_test中实例化。在芯片级建立自己的virtual sequencer
相对应的virtual sequence,通常来说virtual sequence都使用`uvm_declare_p_sequencer宏来指定sequencer。这些sequence在模块级别是存在的,但在芯片级根本不存在,所以这些virtual sequence无法用于芯片级别验证
有两种模块级别的sequence可以直接用于芯片级别的验证:
①一种如A、D和F这样的边界输入端的普通的sequence(不是virtual sequence),以A的某sequence为例,在模块级可以这样使用它:
1 | |
在芯片级这样使用它:
1 | |
②另外一种是寄存器配置的sequence(A_cfg_seq)。这种sequence一般在定义时不指定transaction类
如果这些sequence做成如下形式,也是无法重用的:
1 | |
要想能够在芯片级重用,需要使用如下的方式定义:
1 | |
在模块级以如下的方式启动它:
1 | |
在芯片级别以如下的方式启动:
1 | |
除这种指针传递的形式外,还可通过get_root_blocks()来获得。在芯片级root block已经和模块级不同,单纯靠get_root_blocks()已无法满足要求。此时需要find_blocks()、find_block()、get_blocks()和get_block_by_name()等函数,这里不再一一介绍
附录
要点
在验证平台的设计中要尽量做到小而美,避免大而全(UVM实战,9.2)
factory的重载机制时,被重载的A类应该尽可能多的进行任务/函数的小型化,从而避免在重载过程中大段的代码复制(9.2.2)
尽量做到一看名字就知道这个sequence的用处,这样可以最大程度上方便自己,方便大家(9.2.3)
运行时命令行参数
https://blog.csdn.net/weixin_41979380/article/details/121656117
命令行参数指的是运行时的命令行参数,而不是编译时的命令行参数(即可运行文件的命令行参数,而不是在编译时添加的宏定义)
- 打印出所有的命令行参数
1 | |
- 指定运行测试用例的名称:
1 | |
- 在命令行中设置冗余度阈值
1 | |
- 设置打印信息的不同行为
1 | |
- 重载冗余度
1 | |
- 设置全局的超时时间
1 | |
- ERROR到达一定数量退出仿真
1 | |
- 打开phase的调试功能
1 | |
- 打开objection的调试功能
1 | |
- 打开config_db的调试功能
1 | |
- 打开resource_db的调试功能
1 | |
- 使用factory机制重载某个实例
1 | |
- 类型重载
1 | |
- 类型重载
1 | |
- 类型重载
1 | |
- 类型重载
1 | |
- 在命令行中使用set_config
1 | |
常用宏汇总
https://blog.csdn.net/weixin_41979380/article/details/121656373
宏与运行时的命令行参数不同,它有两种定义方式:
- 一是直接在源文件中中使用
`define进行定义,以MACRO为例:
1 | |
- 二是在编译时的命令行添加,以MACRO为例:
1 | |
- 扩展寄存器模型中的数据位宽
1 | |
- 扩展寄存器模型中的地址位宽
1 | |
- 自定义字选择(byteenable)位宽
1 | |
- 去除OVM中过时的用法,使用纯净的UVM环境
1 | |
除上述通用的宏外,针对不同仿真工具需定义不同的宏:QUESTA、VCS、INCA分别对应Mentor、Synopsys和Cadence公司的仿真工具。由于UVM的源代码分为两部分(一部分是SV代码,另一部分是C/C++),针对不同的仿真工具,需要在SV与C++编译时分别定义各自的宏
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!