ysyx 工作进度与重点
工作任务
- 6/27 阅读 IHI0022H
- 7/07
测试AXI过程中,发现了一个 致命问题:
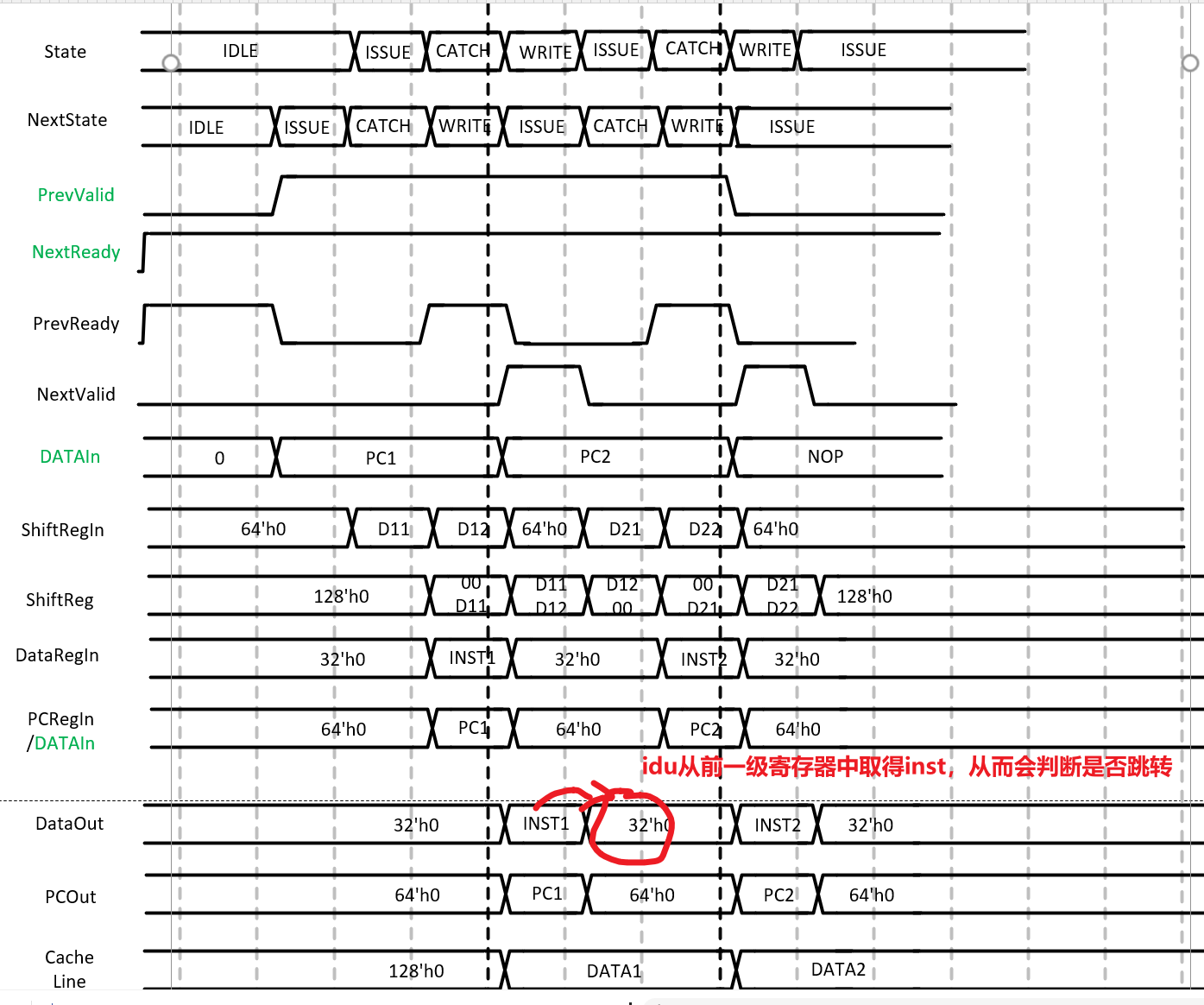
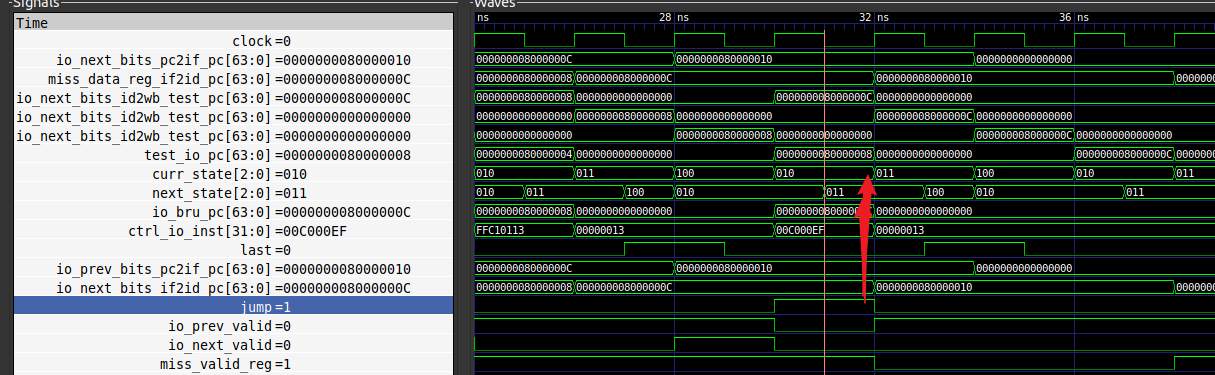
branch/jal/jalr时,若之前一个指令cache miss,则IDU生成jump时,curr_state为预测错误指令的issue状态,此时ready=0,导致pcu无法接收到jump的信号
解决办法:在pcu中对jump进行缓存
- 7.16
- 7.24增加mmio
修改内容:
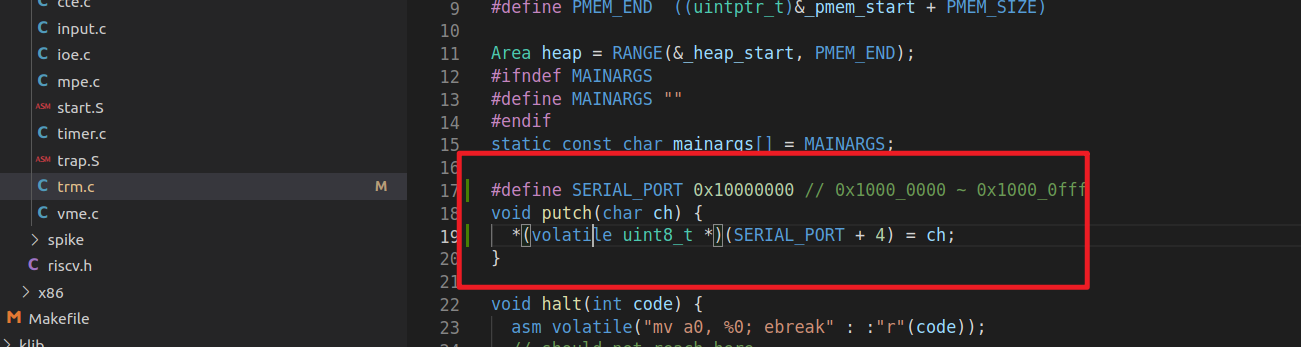
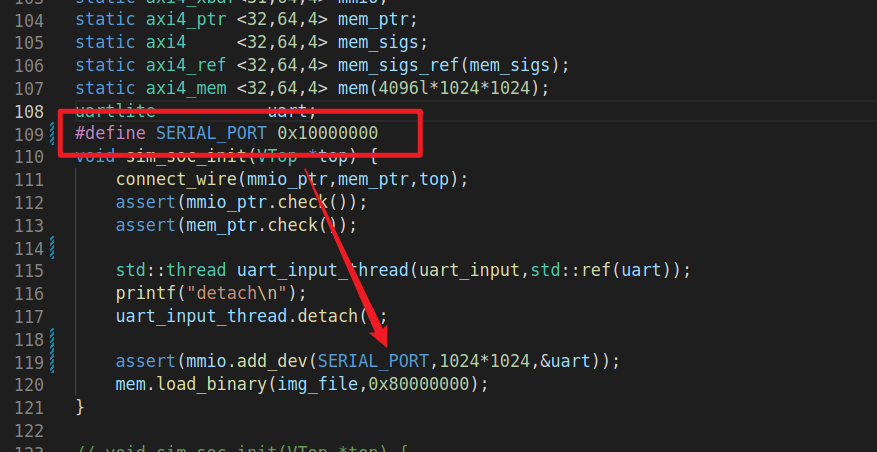
emulator:
- 修改am与soc-simulator中的uart地址(为什么SERIAL_PORT + 4, 因为soc-simulator目前的write_buff是+4的,有bug)
- 修改difftest
- npc中增加difftest适配(test_is_device)
- 线程相关,不然卡死:(CONFIG_MMIO_THREAD)
测试:
make ARCH=riscv64-npc ALL=test run
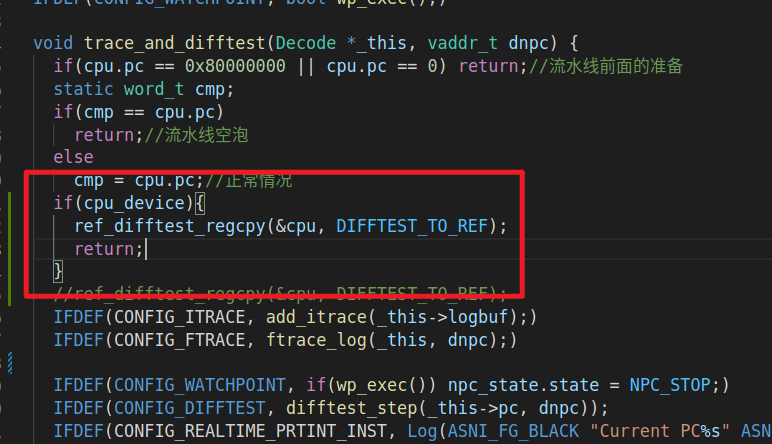
控制信号
bru产生分支预测错误的信号(jump)
这个信号需要上级的所有寄存器除了pc寄存器输入为dnpc其他的寄存器flush,也就是断言jump时reg的prev.in为0
Cache
Cache的组织形式(VIVT、VIPT、PIPT)
- 推荐!Cache 组织形式(VIVT、VIPT、PIPT):https://blog.csdn.net/qq_41596356/article/details/122302652
- 推荐!Cache的基本原理(直接映射、组相联、全相联)https://blog.csdn.net/qq_41596356/article/details/122360914
- Cache的相关知识:https://blog.csdn.net/m0_47799526/article/details/111186953
MMU/TLB
地址空间sv32
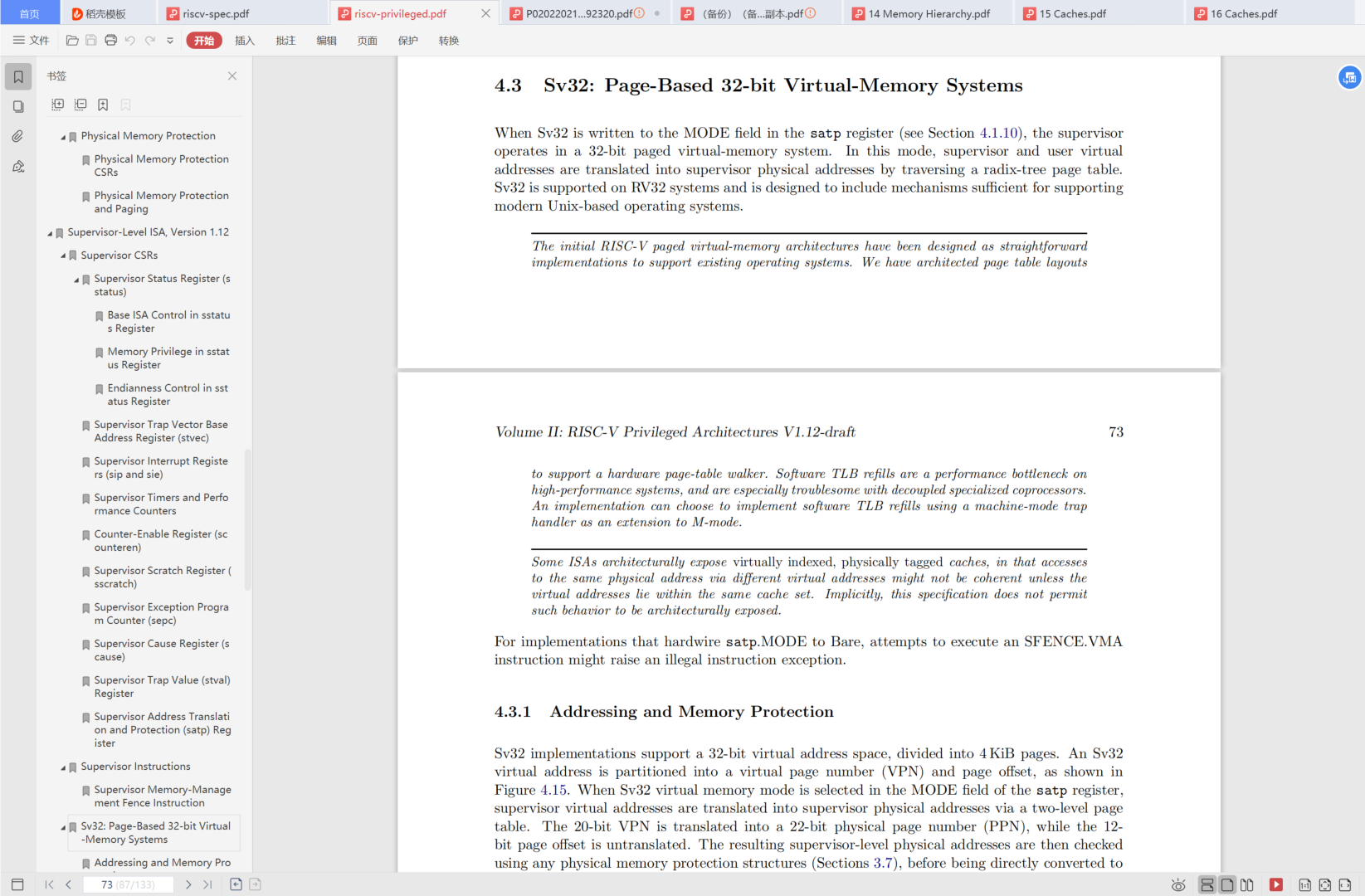

https://blog.csdn.net/weixin_39871788/article/details/119541873
设计指标
2way
data array = 4KB
ram规格:128B * 64
sv39
对齐访问
指令:
1.2 指令长度编码
基本 RISC-V ISA 具有 32 位固定长度指令,并且必须在 32 位边界对齐。然而,标准 RISC-V编码模式被设计成支持变长指令的扩展,在这个扩展中,每条指令长度可以是 16 位指令包裹(parcel)长度的整数倍,并且这些指令包裹必须在 16 位边界对齐。第 14 章中描述的标准压缩 ISA 扩展,通过提供压缩的 16 位指令,减少了代码大小,并放松了对齐要求,允许所有指令(16 位和 32 位)对齐到任意 16 位边界,以提高代码密度。
手册第二章

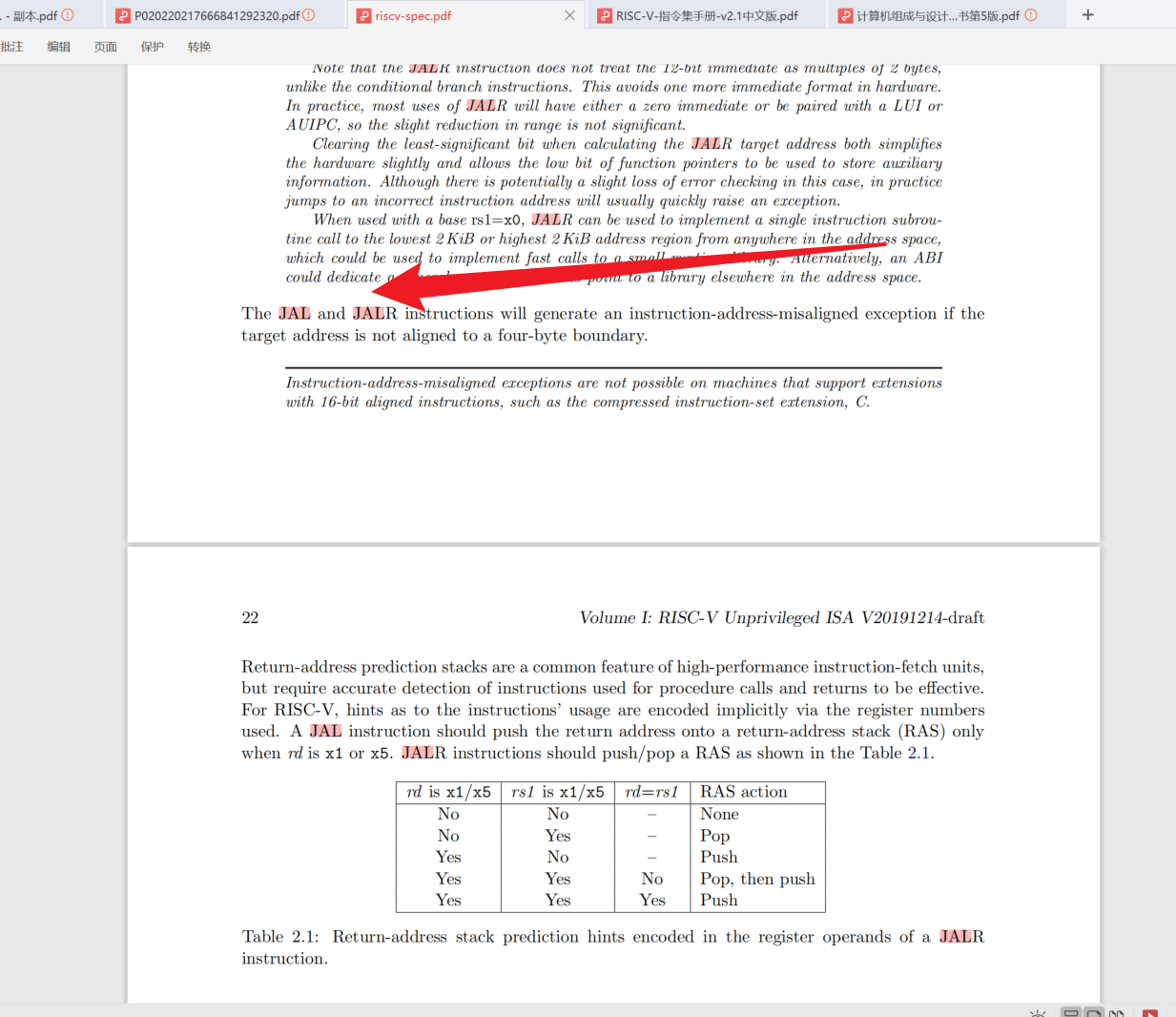
取值不对齐异常:
在基本ISA中,有四种核心指令格式(R/I/S/U),如图 2.2所示。所有的指令都是固定32位长度的,并且在存储器中必须在4字节边界对齐。当发生一个条件分支或者无条件转移而且目标地址不是对齐到4字节时,将会产生一个指令地址不对齐的异常。如果条件分支没有发生(not taken),那么将不会产生一个取指不对齐异常

访存:
为了获得最高的性能,所有load和store指令的有效地址,应该与该指令对应的数据类型相对齐(也就是说,32位访问应该在4字节边界对齐,16位访问应该在2字节边界对齐)。基本ISA支持非对齐的访问,但是根据实现的不同,这可能会运行得非常慢。更进一步的,对齐的load和store访问执行时,可以确保是原子性的,而非对齐的load和store可能不能原子性的完成,因此需要额外的同步来确保原子性(译者注:具体实现非对齐访问时,可能一次访问会被分解为两次存储器访问,这就不是不可分割的原子性操作,有潜在的危险)
riscv需要支持非对齐,以便兼容老程序

cache 一致性
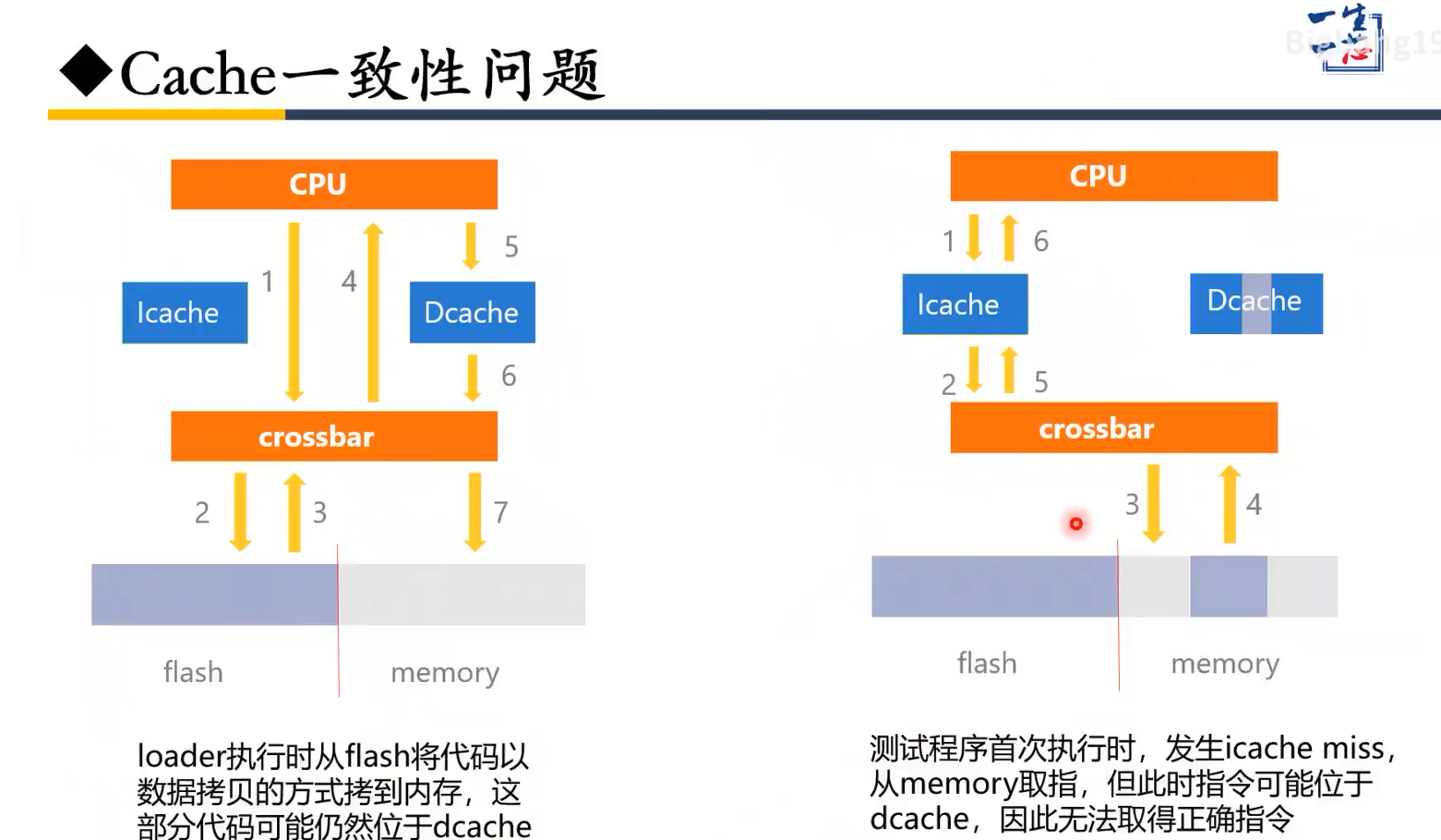
产生原因:
loader执行时将flash中的指令数据拷贝到memory中(调用save指令进行),因此DCache中存在这些save指令缓存的指令,当程序跳转到memory中的指令中执行时,某些指令很可能还在DCache中
TLB
操作系统实验我这么熟悉,主要还是CPU硬件上要做好异常处理以及MMU(对于软件定义页表的MIPS就是个TLB),于是我便与之前参加NSCSCC比赛的同学组了个队。然后便在他们之前参加比赛的CPU上开展了后续的工作,完成了TLB的设计以及CP0中所需功能的加入与调试
SRAM(Data Array)

- 官方的单口
1 | |
- 教程的单口
1 | |
- 如何实现双口?
Vivado的BRAM最多支持真·双端口,按照对应的Verilog模板逆向编写Chisel,然后用编译器把Chisel转换成Verilog。但此时编译器生成的Verilog代码并不能被Vivado的综合器识别出来。原因在于SyncReadMem生成的Verilog代码是用一级寄存器保存输入的读地址,然后用读地址寄存器去异步读取RAM的数据,而Vivado的综合器识别不出这种模式的RAM。读者必须手动修改成用一级寄存器保存异步读取的数据而不是读地址,然后把读数据寄存器的内容用assign语句赋值给读数据端口,这样才能被识别成真·双端口BRAM。尚不清楚其它综合器是否有这个问题。经过咨询SiFive的工作人员,对方答复因为当前转换的代码把延迟放在地址一侧,所以流水线的节拍设计也是根据这个来的。考虑到贸然修改SyncReadMem的行为,可能会潜在地影响其它用户对流水线的设计,故而没有修改计划。如果确实需要自定义的、对综合器友好的Verilog代码,可以使用黑盒功能替代,或者给Firrtl编译器传入参数,改用自定义脚本来编译Chisel。
soc指标
Master
1)global
| 方向 | 名称 | 位宽(留空则为1位) | 功能描述 | 备注 |
|---|---|---|---|---|
| input | clock | 时钟信号 | ||
| input | reset | 复位信号 | 高电平有效 | |
| input | io_interrupt | 外部中断信号 |
2) AW
| 方向 | 名称 | 位宽(留空则为1位) | 功能描述 | 备注 |
|---|---|---|---|---|
| input | io_master_awready | AXI4写地址通道,master | ||
| output | io_master_awvalid | |||
| output | io_master_awaddr | [31:0] | ||
| output | io_master_awid | [3:0] | ||
| output | io_master_awlen | [7:0] | ||
| output | io_master_awsize | [2:0] | ||
| output | io_master_awburst | [1:0] |
3)W
| 方向 | 名称 | 位宽(留空则为1位) | 功能描述 | 备注 |
|---|---|---|---|---|
| input | io_master_wready | AXI4写数据通道,master | ||
| output | io_master_wvalid | |||
| output | io_master_wdata | [63:0] | ||
| output | io_master_wstrb | [7:0] | ||
| output | io_master_wlast |
4)B
| 方向 | 名称 | 位宽(留空则为1位) | 功能描述 | 备注 |
|---|---|---|---|---|
| input | io_master_arready | AXI4读地址通道,master | ||
| ——— | ————————- | ——— | ——————————— | —— |
| output | io_master_arvalid | |||
| output | io_master_araddr | [31:0] | ||
| output | io_master_arid | [3:0] | ||
| output | io_master_arlen | [7:0] | ||
| output | io_master_arsize | [2:0] | ||
| output | io_master_arburst | [1:0] |
5)AR
| 方向 | 名称 | 位宽(留空则为1位) | 功能描述 | 备注 |
|---|---|---|---|---|
| input | io_master_arready | AXI4读地址通道,master | ||
| output | io_master_arvalid | |||
| output | io_master_araddr | [31:0] | ||
| output | io_master_arid | [3:0] | ||
| output | io_master_arlen | [7:0] | ||
| output | io_master_arsize | [2:0] | ||
| output | io_master_arburst | [1:0] |
6)R
| 方向 | 名称 | 位宽(留空则为1位) | 功能描述 | 备注 |
|---|---|---|---|---|
| output | io_master_rready | AXI4读数据通道,master | ||
| input | io_master_rvalid | |||
| input | io_master_rresp | [1:0] | ||
| input | io_master_rdata | [63:0] | ||
| input | io_master_rlast | |||
| input | io_master_rid | [3:0] |
除法优化
1 | |
国科大-秦永盛
https://blog.csdn.net/tianxieeryang/article/details/86687065
国科大-秦永盛
这里有个dowhile0的解释
Flush & Counter
1 | |
sfence
PA3提到的:链接
以支持现代操作系统的RISC-V处理器为例, 它们存在M, S, U三个特权模式, 分别代表机器模式, 监管者模式和用户模式. M模式特权级最高, U模式特权级最低, 低特权级能访问的资源, 高特权级也能访问. 那CPU是怎么判断一个进程是否执行了无权限操作呢? 答案很简单, 只要在硬件上维护一个用于标识当前特权模式的寄存器(属于计算机状态的一部分), 然后在访问那些高特权级才能访问的资源时, 对当前特权模式进行检查. 例如RISC-V中有一条特权指令sfence.vma, 手册要求只有当处理器当前的特权模式不低于S模式才能执行, 因此我们可以在硬件上添加一些简单的逻辑来实现特权模式的检查:
1 | |
特权模式的检查只不过时一些门电路而已. 如果检查不通过, 此次操作将会被判定为非法操作, CPU将会抛出异常信号, 并跳转到一个和操作系统约定好的内存位置, 交由操作系统进行后续
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!