ysyx讲座笔记
SoC或CPU参考架构图
汇总:

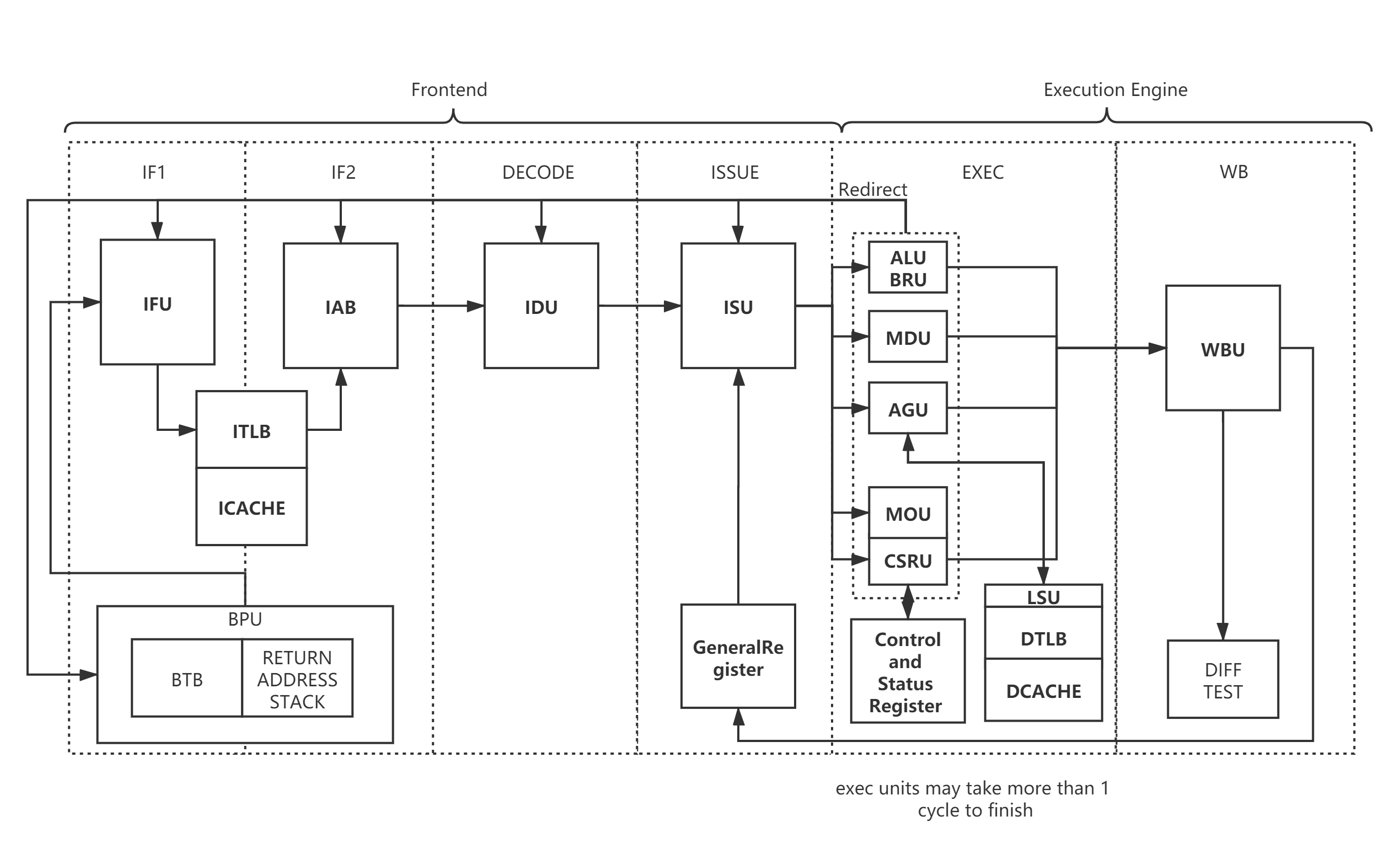
- https://blog.csdn.net/qq_40500005/article/details/117880249
- AGU(Address Generation Unit)
- LSU(Load Store Unit)
Chisel 初步
AXI4 连接

Chisel使用经验
- Chisel开发环境
- 用Chisel 写个简单的模块: Adder
- 创建这个模块的端口类
- 创建这个模块的伴生对象
- 创建这个模块的 Chisel-Testers 2 TB
- 继承这个模块的端口类
- 高阶实例: Adder Tree (map, foreach, case, forkjoin]
- 优化命令 (suggestName, dontTouch, dontCare)
- 几个个人习惯
Chisel开发环境
- 使用GitHub repo模板(mill)
- https://github.com/sequencer/chipsalliance-playground 大杂烩,需要自己删去一部分不需要的submodule
- https://github.com/SingularityKChen/chipsalliance-playground 没有冗余submodule
- 使用EasySoC Chisel插件 (sbt)

用Chisel 写个简单的模块: Adder

改进为创建模块的端口类

创建这个模块的伴生对象

- Adder
- class
- object(伴生对象)
- 例化时直接进行连接,不用在手动进行连接
一个class与两个object.apply(一个使用bundle,一个端口单独拿出来)


调用方法
1 | |
高级实例:adder tree 加法器树

- Vec(类似scala的seq)
- 参数一:个数
- 参数二:类型
- Array.map(x => function(x))
- array里面的元素,以x做迭代器,替代为=>后的函数表达式

优化命令(很少用)

个人习惯

重构与注释
- 经常refactor(代码重构)
- 整理代码结构
- 合并重复代码
- …
- 经常添加注释
- Scaladoc(官方scala注释)
更多技巧

补充
chisel在Nutshell中的使用
chisel在Nutshell中的使用
NutShell设计

确定架构

模块 分解

- 上面是一个单周期cpu
- 下面是nutshell cpu
参数定义

- 实例化显式传参
- 实例化时隐式传参(推荐)
- 作用:在一个类中声明隐式参数,则该类内部所有实例化类都传入了改参数


- 全局参数

- CDE(自己研究,较难)
- Diplomacy(自己研究,较难)
接口定义

模块组装

时序电路的组装

凡是两个流水级要连接,可以直接调用这个类

模块开发

- chisel 仲裁器Arbiter和队列Queue(ready-valid接口)
https://blog.csdn.net/qq_39507748/article/details/118887707
- 一个有初始值的二维寄存器示例

- chisel多使用for加速电路描述

测试和调试

NutShell中使用到的一些Chisel特性

- 可以看《scala函数式编程》
- 一个生成掩码的函数

设计MaskedRegMap来描述CSR

- 副作用:改一个csr对系统状态进行改变
- reg addr:csr在手册中的地址
- reg data source:实际硬件寄存器

- map(maskedregmap)
- Mstaatus:reg addr,一个常量
- mstatus:一个实例化的寄存器
- “hfffffffffffffffffffff”.U一个掩码
- mstatusUppdateSideEffect:一个函数
- maskedregmap.generator(进行完整实现)
maskedregmap:

总的MaskedRegMap一行

AXI4设备中的代码复用

- 使用面向对象的思想进行复用

UART就很简单,大量逻辑在AXI4Slave里面:


Chisel开发中的注意事项(坑)
注意事项

- 把scala看作宏一样的东西

坑


- DontCare非常危险,流片前消灭掉

提早发现错误
两种assert(俄则特)

什么是中断和异常
参考内容
The RISC-V Instruction Set Manual Volume II: Privileged Architecture Document Version 20190608-Priv-MSU-Ratified
中断异常简介
- 异常(狭义):一般指来源于核内部的异常
- -如:指令错误、访存错误等
- 中断:一般指来源于核外部的异常,属于广义的异常
- 包括外部中断、计时器中断以及软件中断
- 一个特别术语——trap: 由异常或中断引起的控制转移
什么是异常处理机制
- 处理器内核在执行程序的过程中,突然发生异常中止当前执行的程序,转而去做别的事情
- 当别的事情处理完后,回到之前的地方继续执行之前的程序
RISCV异常类型

要运行interrupt test ( am-kernels/tests/am-tests )暂时只需要实现时钟中断(计时器中专)+环境调用异常
RISCV特权级别
在任何时候,RISC-V处理器一定是运行在一个特权级别当中的

- 暂时只需要实现M模式
注意事项
- 中断嵌套
- 处理器内核正在处理中断时,出现了新的中断请求
- RISC-V在硬件层面不支持,需要软件层面的特殊处理
- 所以暂时不需要考虎
- 仲裁
- 当同时出现多个中断的时候,需要进行仲裁
- 出现在外部中断与内部中断、外部与外部中断之间
- 所以暂时不需要考虑
- 中断处理模式
- 分为向量处理模式和非向量处理模式
- 暂时只需要实现非向量处理模式
总结
需要实现M模式与非向量处理模式
实现环境调用异常
需要实现部分与环境调用异常有关的CSR
- 控制状态寄存器 Control and Status Registers

1. mstatus
- Machine-mode Status Register
- 跟院并控制处理器的当前运行状态
- 可读/写

- mstatus-MIE
- 启用/禁用全局中断
- 当硬件线程在特权模式M下执行时
- MIE=1:全局启用中断
- MIE=0:全局禁用中断

mstatus-MPIE & MPP
- 为了中断结束后能恢复原本的MIE位和特权模式
- MPIE:存储在trap 之前 MIE 位的值
- MPP:存储在trap 之前的特权模式 (目前可以写死为3,M->3)

2. mtvec
Machine Trap-Vector Base-Address Register
trap 向量配置 (异常入口地址)
- 可读/写
- 两部分:base, mode
- mode:direct(非向量处理模式)、vectored(向量处理模式)。我们只需要实现非向量处理模式,因此可以写死为00
- base:direct时被设置为异常入口地址的2到最高位

3. mepc
- Machine Exception Program Counter
- 遇到中断/异常的指令的pc
- 可读/写

4. mcause
- Machine Cause Register
- 指示导致 trap的事件
- 可读/写
- 如果 trap 是由中断引起的,中断位(Interrupt)则会置1,异常则为0
- code:手册上有不同异常中断对应不同mcause值,在实现中断和异常的时候根据这个查询中断或异常的不同,trap时修改这个mcause,反映了中断异常的原因

am中的注意事项:


定时器中断的产生需要三个条件:
- mstatus全局中断为1(软件实现)
- mie中MTIE为1(软件实现)
- mtime>=timecmp
1.2.条件如下所示



ecall:通过引发环境调用异常,来请求执行环境
hello_intr的内容
- 编写异常处理代码
- 设置异常处理入口地址
- 调用ecal指令
硬件工作(调用ecall后,cpu执行ecall指令的过程)
CPU捕获异常
保存/更新CSRs
mepc
异常:当前的指令的PC值(我们刚刚执行的是ecall,因此保存的是ecall指令的值)
mcause
- 记录当前的异常原因: 十进制11(ecall的异常原因是d11,因此这里需要记录为d11)
mstatus
- MPIE设为MIE的值0(即禁用环境异常)
- MIE设为0跳转到mtvec的异常入口地址
进行异常处理——软件
- 保存上下文:保存CPU的寄存器到内存中
- 跳转到异常处理程序进行异常处理 (ecall特有的会在软件中设置mepc为pc+4)
- 为什么是pc+4,因为pc是ecall,回卡死在ecall
- 为什么am里面使用原件修改为pc+4,而不直接使用硬件,因为RISCV规定发生异常时mepc必须是异常处的pc,所以我们使用ecall软件中断的时候必须手动设置mepc为pc+4不然就卡死在ecall了
- 恢复上下文: 从内存中恢复CPU的寄存器
- PS:RISCV是软件进行上下文管理的,RISC-V架构的处理器不实现硬件上的上下文保存/恢复,需要在软件上实现上下文的切换机制
退出异常(mret)
最后软件调用mret指令恢复异常,mret作用:
恢复mstatus
- MIE从MPIE中恢复,MPIE设置为1
跳转到mepc中的地址
实现定时器中断
需要实现部分与实现定时器中断有关的CSR
1. mip
- Machine interrupt-pending register
- 包含等待中断的信息
- 可读/写*
- 为什么有星号:因为mip并不是所有位都即可也可写,但是哪些不可以即可读也可写的位与计时器中断关系不大

2. mie
- Machine interrupt-enable register
- 包含各种中断的启用位
- 可读/写
- 我们需要实现的定时器中断MTIE:M模式计时器中断启用位

3. mtime(Clint)
- Machine time reqister
- 64位内存映射的M模式实时计数器(对于rv32也是64位的)
- 本质上不是CSR,可读/写
- 属于Clint (Core-Local Interruptor, 核心局部外设),本质上是核心外设,通过MMIO实现的
- 以恒定的频率增加(与mycycle不同,mycycle与外接时钟频率有关)
4. mtimecmp(Clint)
- Machine time compare register
- 64位内存映射的 M模式计时器比较寄存器
- 不是CSR
- 可读/写
- 当mtime >= mtimecmp 时,并且产生计时器中断mip的MTIP位置1

前面的步骤与环境调用异常类似
进入中断-硬件
- CPU捕获计时器中断
- 保存/更新CSRs
- mepc
- 中断:下一条指令的PC值(与环境调用异常中硬件保存的PC不同,这里是pc+4,但是这里的pc+4指的是发生中断时还未执行的那一条指令,即译码时期的指令),其实和环境调用异常中的ecall在硬件实现上一样,这里的下一条指的就是中断发生时正在执行的指令
- mcause
- 记录当前的异常原因:0x8000000000000007
- mstatus
- MPIE设为MIE的值,MIE设为0
- mepc
- 跳转到mtvec的异常入口地址
进行中断处理-软件
- 保存上下文: 保存CPU.的寄存器到内存中
- 跳转到中断处理程序进行中断处理 (mtimecmp)
- 恢复上下文: 从内存中恢复CPU 的寄存器
退出异常(mret)
最后软件调用mret指令恢复异常,mret作用:
- 恢复mstatus
- MIE从MPIE中恢复,MPIE设置为1
- 恢复mstatus
- 跳转到mepc中的地址
补充CLINT(Core Local Interruptor)
https://blog.csdn.net/qianniuwei321/article/details/123250492
中断全流程
小结:发现环境调用异常与定时器中断在很多时候是相通的,中断异常的实现如下

- 硬件除法异常或中断
- 硬件保存/更新 CSRs
- 硬件跳转到mtvec
- 软件…
- mret
其他注意事项
备注: csr指令中的5位立即数不需要符号位扩展。https://www.cnblogs.com/mikewolf2002/p/11196680.html
流水线

- 请参考这个符号位扩展的位置


- 命名规范
- i/o 输入输出
- IDRN隶属模块
- xxxxx具体功能

动态分支预测

2bit分支预测器与3/4/5/6…性能差不多,资料网上多就不赘述了
使用动态分支预测后的图


静态分支预测:永远猜他跳/不跳
AXI
握手
master发送给slave数据
- 有效信号valid:一方想发送
- 就绪信号ready:另一方能接受
- valid && ready:数据成进行一次传输
- 不重不漏

异步总线,每一路都有握手
- 读请求信号
- RAVALID ->
- RAREADY <-
- RADDR ->
- 读响应信号
- RDVALID <-
- RDREADY ->
- RDATA
- 写请求信号
- WAVALID(wen) ->
- WRAREADY <-
- WRADDR ->
- WDATA ->
- WMASK ->
- 写响应信号
- WDVALID <-
- WDREADY ->
AXI-Lite
AXI4-Lite 是一种异步存储器总线协议
五个通道
读地址 AR、读数据 R
- 与之前的异步总线完全一致
写地址 AW、写数据 W
- 将原先的写请求通道一分为二
写响应
时钟信号 ACLK 上升沿触发
- 同步复位 ARESETn 低电平有效
AXI读写事务transcation

AXI4-Lite 读地址 AR
- 读地址握手信号
- ARVALID->
- ARREADY <-
- 读地址
- ARADDR ->

AXI4-Lite 读数据 R
- 读地址握手信号
- RVALID->
- RREADY <-
- 读地址
- RDATA ->

AXI4-Lite 写地址 AW
- 写地址握手信号
- AMVALID ->
- AWREADY <-
- 写地址
- AWADDR ->

AXI4-Lite 写数据 W
- 写数据握手信号
- WVALID ->
- WREADY <-
- 写数据
- WDATA ->
- 写掩码
- WSTRB ->
STRB(Strobe)选通的意思

AXI4-Lite 写响应 B
写响应握手信号
- BVALID <-
- BREADY->

AXI4-Lite注意事项
- 读事务和写事务分别均为顺序响应(也就是第一个地址、第二个地址、第三个….)
- 写地址通道和写数据通道可以不同时有效
- 为了避免总线死锁,规定每个通道内
- valid 置有效不能依赖于 ready 是否有效
- ready 置有效可以依赖于valid 是否有效
AXI4-Lite信号一览

AXI4与AXI4-Lite的互联
AXI4协议和AXI4-Lite是可以互联的,唯一需要注意的是当主机是AXI4且从机是AXI4-Lite时,从机的AXI4-Lite协议需增加AXI ID信号以匹配主机的AXI ID

从AXI4-Lite到AXI4
如果我想从内存读一整页 (4K) 的内容
- 一次读 8 Bytes,则需要发送 512 次读请求
- -有没有更好的办法呢
什么是突发传输(Brust)
- 一段时间内,连续地传输多个地址相邻或相同的数据
突发传输burst
突发传输事务与普通传输的对比:

- 注意burst突发和transaction事务所代表的范围
突发传输三要素(x为W或R,代表读或写)
- 突发宽度 AxSIZE
- 突发类型 AxBURST
- 突发长度 AxLEN
突发宽度 AxSIZE
- 每个 transfer/beat 的数据宽度
- 必须小于该 transaction 中任一主从数据总线的宽度

突发类型AxBURST 有三种
- FIXED(固定)
- 所有的数据都使用AxADDR,通常用于FIFO,串口等,即每一次读/写数据都是AxADDR
- INCR
- 第一个数据的地址为 AxADDR
- 后一个数据在前一个数据的基础上递增“突发宽度
- 常用于RAM等
- WRAP


突发长度 AxLEN
burst 中 transfer/beat的个数 = AXLEN + 1
- AxLEN 位宽为8 位
- 对于INCR类型的突发传输,AxLEN 可取0~255
- 对于FIXED类型的突发传输,AxLEN 可取0~15
AXI4中的xID信号
五级流水线CPU 中,取指与访存都会发出读请求
- 取指和访存分别发出读请求,然后读数据返回
- 取指和访存都以为是自己的读数据
- 怎么解决这一问题呢
为通道新增ID信号,不同流水级可用不同ID
- master 发出的请求便用什么 ID,slave 返回的响应就使用什么ID
- master根据响应的 ID 判断是哪一流水级的响应

为什么没有WID写数据ID(AXI3中有,AXI4中不再使用)
答:
AXI4单主机传输事务规定
- 写数据顺序与写事务的顺序一致
- 这就使得我们不需要 WID信号
- ID相同的事务,从机需要按照主机发出事务的顺序执行,并按序返回数据或者回复信号
- ID不同的事务,之间不存在顺序约束,从机可以按照任意的顺序返回数据或回复
- 读写事务之间不存在顺序约束
- 或者,我们也可以干脆把IF级和MEM 级当作是两个 master 设备!
- IF级和 MEM 级都能读
- 只有MEM 级才能写
AXI4 多主机传输事务
如何支持多主机?实现一个仲裁器
- N-to-1 Interconnect
- 协议规定,不同主机间的事务是独立的,没有顺序约束
仲裁器如何将读数据和写响应返回给正确的主机?(两种方案)
- 方案1(简单粗暴):各主机保证自己的 ID与其他主机不同
- 方案2(推荐):仲裁器对不同主机请求的 ID 进行调整,使得即使不同主机发出的请求ID相同,从机看到的ID不同
- 仲裁器接收主机事务后,在原有事务 ID附加一个表示来源端口的前缓
- 仲裁器接收从机事务后,根据事务ID前缀判断应当返还给哪一个主机
- 返还给主机前,仲裁器需要将 ID 前缀去掉
- 协议建议主机端ID 不超过4位
- 协议建议仲裁器为ID 添加的前缀不超过4 位

AXI4仲裁器对写事务保序
- 写数据顺序与写事务顺序一致(即lock住了,其他master来了先存起来)
- 可以看作是之前单主机版本的约定的一个扩展
- 一个事务内的写数据间,不能插入其他事务的数据(AXI4新增,AXI3支持但可以实现的设备较少且难度较大,因此在AXI4中删除)
- 这些抓定讲一步保障了即使在多主机的情况下,我们也依然不需要WID
- 如果没有保序会搞乱
窄传输
当本次传输的突发宽度 (AxSIZE)小于通道本身的宽度(假设为 size) 时,这次传输被称为窄传输
- 数据在通道上传输的位置必须与 (数据的地址) % size 保持一致
AX4规定:
- master 必须保证 WSTRB只在对应字节有效时为高


非对齐传输
起始地址 AxADDR 与突发宽度 AxSIZE 不对齐
对于非对齐传输,master可以把它变成对齐的:
- 在首个 transfer 填充无效数据至对齐
- 将起始地址调整为对齐的地址
然后,问题就退化为了窄传输/正常传输
特别提示
- master 必须保证WSTRB 只在对应字节有效时为高

transaction的回复信号
读数据和写响应通道分别有一个回复信号 xRESP
- 写事务的回复信号针对整个事务
- 读事务的回复信号针对每个 transfer


- OKAY
- SLVERR从机问题
- DECERR解码错误(一般是不存在的地址)
总结
这里只介绍了一些最主要的信号和规范,若需了解更多,可以自行查阅手册
输入输出
那么,MMIO 在硬件上应该由谁来实现呢
- 访问设备由访存指令实现
- 访存需要经过总线
- 总线负责把不同地址的访问请求分发给不同的设备
- 1-to-N Interconnect 负责分发
1-to-N AXI4 Interconnect(单主机多从机,我们在设计CPU时一般参考这个就行)
- 也称为 decoder/router
- 根据 AxADDR将相应的请求转发到不同的从机

CPU 中的可能情况
- 多主机:IF,MEM
- 多从机:DRAM,UART,CLINT等

NEMU的MMIO
nemu 的设备及其内存映射
- 串口: 0xA10003F8,1字节
- 时钟: 0xA1000048,2 字节
- 键盘:0xA1000060,4字节
各设备寄存器的用法请自行查阅手册和阅读代码
一个有关interconnect的问题
axi4-interconnect
问题:axi interconnect 外围子系统包含一个 AXI crossbar,每个 S/M 端口带有couplers 。这些对不是标准的 AXI 对 IP,而是直接将 S_AXI 连接到 M_AXI 的自定义 IP。我猜这些是虚拟 IP,如果我不必在我的设计中实现耦合器,则不需要。我想得到一些关于设计的确认和见解。链接
回答:Each sub modules in the axi_interconnect are generated automatically by the tools per MI/SI protocols. Couples are needed for auto generation. If no signals conversion are needed, it’s only a dummy as you have seen. This doesn’t matter. If you really don’t want to see it(I cannot image the reason), don’t use axi_interconnect you can manually add each AXI infrastructure cores like Crossbar, converter, etc.



- CPU访问FPGA外设:crossbar->chiplink->FPGA
- CPU使用UART:crossbar->UART
- CPU上有两个AXI4接口,一个master一个slave,slave与dma接,没有则悬空
RAM替换

RAM/与cache

- 注意:数据输出会延后一个周期
设备和中断的扩展

时钟复位模块(RCG)

- 为什么要做一个时钟复位?
- 如果不做,异步的时候会出现亚稳态问题
- RCG模块:异步复位,同步撤离
- sys_clk 外部晶振输入
- pll_cfg pll配置信号
- clk_sel mux选择项,防止pll挂掉,从而提供外部晶振
- sys_rst 外部复位信号
- 左边两个D触发器作用:打两拍,实现同步释放
- Counter:做延迟,pll一开始不稳定
异步复位寄存器说明

外设介绍
1 UART

2 SPI

总线介绍

取指通路(红色线)

访存通路(红色线)

DMA通路
- 网卡
- Network接口处需要有一个中断

地址分配

- reserve(红色部分)意思是保留
第一个程序的加载

- 四种加载方式:
- 无
- cpu在执行第一条指令前使用verilator等仿真工具,将测试程序加载到memory中,并设置合适的pc起始地址。这样cpu就会根据起始地址,逐条指令执行
- flash存放一条跳转地址,跳转指令作用是跳转到memory中的测试程序的起始地址
- cpu在执行第一条指令前使用verilator等仿真工具,将测试程序加载到memory中,并设置起始地址为flash中的跳转指令的地址
- 在flash中放一个加载程序loader,cpu起始地址设置为loader起始地址
- 直接在flash中运行测试程序,但是flash中的xip地址空间智能读不能写,有些数据读写操作不能进行,因此需要对程序进行特殊处理
- 我们提供一XIP flash模式的rtthread

- 无
cache一致性问题

一个可以仿真的soc

MIPS(龙芯杯接入)

本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!