RISCV 入门
RISCV 入门
参考资料:
- 用户手册
- 特权手册
- 中文手册
- RISC-V 指令格式和6种基本整数指令:https://blog.csdn.net/qq_39507748/article/details/120150936
- RV32I基础整数指令集 :https://www.cnblogs.com/mikewolf2002/p/11196680.html
- RV64I基础整数指令集:https://www.cnblogs.com/mikewolf2002/p/11199014.html
- 外网概述:https://devopedia.org/risc-v-instruction-sets
- rv64i与rv32i区别、多少条指令的问题:https://blog.csdn.net/u011011827/article/details/121371305
- 旋转?与框图介绍:https://blog.csdn.net/limanjihe/article/details/122395354
- 颜色看起来很舒服,,类型归纳的不错,指令集分类写的还行:https://blog.csdn.net/weixin_40377195/article/details/123647133
- shamt:https://blog.csdn.net/zh328271057/article/details/82728958
- 这人写的比较通俗易懂、ret:https://blog.csdn.net/qq_43245691/article/details/110260112
- FENCE提到了一部分:https://blog.csdn.net/weixin_33767813/article/details/93521646
- FENCE与FENCE.I:https://zhuanlan.zhihu.com/p/139797515
- RV32M&RV64M扩展指令集 :https://www.cnblogs.com/mikewolf2002/p/9872287.html
- 算数溢出与指令详解(riscv-flxmcu):http://www.philisense.com/Risc/Risc-v-flxMCU.pdf
- 异常与中断:https://www.it610.com/article/1494953718276227072.htm
- RVZicsr指令集:https://www.cnblogs.com/mikewolf2002/p/11305031.html
RV32I
0)特权结构与可选扩展
特权结构:
RISC-V官方标准主要分为两部分:用户指令集、特权模式
根据不同的应用场景和需求,同一指令集根据不用特权模式在设计上采取不同的策略;为了加强对操作系统和信息安全的支持,定义三种模式,每一钟模式对应一个特权层级,机器模式层级最高,普通用户模式层级最低,层级越高软件可操作的权限就越高;在处理器设计时,机器模式是必须要实现的,其他两个模式根据需求加以实现,如果目标是简易的MCU,因此也只需要实现机器模式即可
U-mode:应用程序代码通常在用户模式或 U 模式下运行,RV32I 和 RV32G 是用户模式 ISA。
S-mode:用于支持 Linux、FreeBSD 或 Windows 等操作系统需求。这比U模式具有更高的特权,但比 M 模式具有更低的特权。当操作系统需要处理异常/中断时,异常委托用于选择性地将控制传递给 S 模式。 S-mode 还提供了一个虚拟内存系统。
- M-mode:机器模式(M-mode):用于运行受信任的代码。这是 RISC-V 中最高特权的模式,可以完全访问内存、I/O 和其他任何东西来引导和配置系统。它最重要的功能是处理同步异常和中断。最简单的 RISC-V 微控制器只需要支持 M 模式
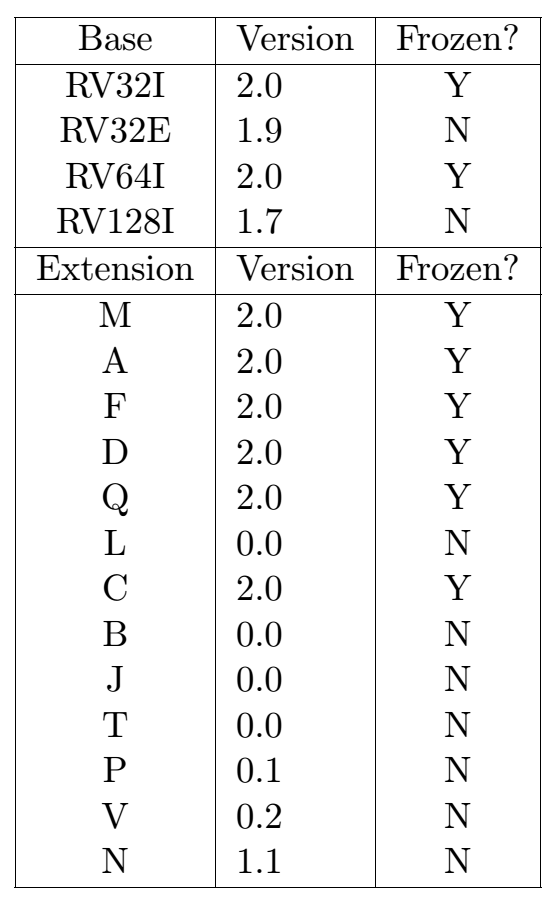
可选扩展
RISC-V 定义了许多扩展,所有这些都是可选的。
其中一些是Frozen的,这些记录如下:
- M: Integer multiplication and division.
- A: Atomic
- F: Single-precision floating point compliant with IEEE 754-2008.
- D: Double-precision floating point compliant with IEEE 754-2008.
- Q: Quad-precision floating point compliant with IEEE 754-2008.
- C: Compressed instructions (16-bit instructions) to yield about 25-30% reduced code size. “RVC” refers to compressed instruction set.
不断发展或未来的扩展:
- L (decimal float)
- B (bit manipulation)
- J (dynamically translated languages)
- T (transactional memory)
- P (packed SIMD)
- V (vector operations)
- N (user-level interrupts)
- H (hypervisor support)
当支持多个扩展时,可以通过连接字母来描述该 ISA 变体;例如,RV64IMAFD。为了表示标准通用ISA,“G”被定义为“IMAFD”的缩写形式
参考资料1:https://blog.csdn.net/weixin_40377195/article/details/123647133
参考资料2:https://devopedia.org/risc-v-instruction-sets
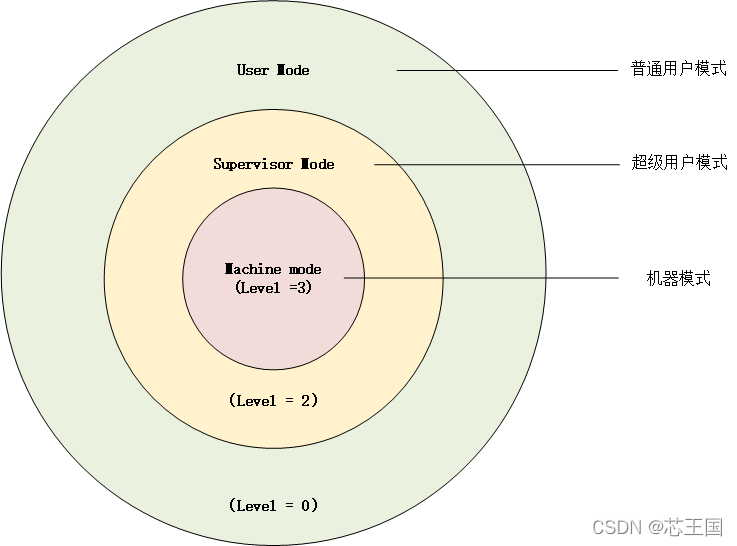
1)非特权态的32个寄存器:
- 长度XLEN=32bits
- x0始终为0
- 通用寄存器x1-x32有各种不同解释
- 除此32个寄存器外,非特权态还有一个pc寄存器,保存当前指令的地址
除此之外:
RISCV采用load-store架构,对比RV64I使用了64位地址空间
2)rs、rd与立即数
源(rs1和rs2)和目标(rd)寄存器保持在所有格式的相同位置,以简化解码
指令提供三个寄存器操作数,避免了只有两个寄存器操作数的 ISA 所需的额外移动。它们也位于相同的位置,因此可以在解码指令之前开始访问。https://devopedia.org/risc-v-instruction-sets
立即数:除了CSR指令(第10章)中使用的5位即时消息外,立即数始终是符号扩展的,并且通常打包到指令中最左边的可用位,并已分配以降低硬件复杂性。
- 特别是,所有立即数的符号位始终位于指令的第31位,以加快符号扩展电路。
3)四种基本整数指令格式
在基本 RV32I ISA 中,有四种核心指令格式(R/I/S/U)
RV32I指令格式包括以下6种,每种指令格式都是固定的32位指令,所以指令在内存中必须4字节对齐。比如一个分支跳转指令,当条件判定是跳转的时候,而目的地址不是4字节对齐,则产生指令地址不对齐异常。无条件跳转指令也是如此,目的地址不是4字节对齐,则产生指令地址不对齐异常。备注:但在实际应用中,很难会产生这种错误,因为在汇编语言中,我们用label作为跳转目的,汇编器会自动帮我们产生字节对齐的偏移地址。[5]
- 所有的长度都是固定的 32 位,并且必须在内存中的四字节边界上对齐
- 如果目标地址不是四字节对齐的,则会在采用分支或无条件跳转时生成指令地址未对齐异常。 此异常在分支或跳转指令上报告,而不是在目标指令上。 对于未采用的条件分支,不会生成指令地址未对齐的异常
- 每个立即数子字段都labeled正在产生的立即值中的位位置 (imm[x]),而不是通常在指令的立即字段中的位位置

- 其中 opcode 表示 7 位指令操作码,其作用是区分不同的指令
- funct3 表示 3 位 的功能码,funct7 表示 7 位的功能码,它们可以辅助区分不同种类的指令
- rs1 和 rs2表示两个 5 位的源寄存器
- rd 是 5 位的目的寄存器,指令运算的结果就存储 rd 中
- imm 代表不同长度的立即数,可直接作为操作数使用
imm:imm表示指令中的立即数,比如imm[11:0],表示一个12位的立即数,它的高20位会符号位扩展,也就是用最左边的位imm[11]来进行扩展。imm[31:12]表示一个32位的立即数,它的低12位会补0。备注: csr指令中的5位立即数不需要符号位扩展 - shamt 表示位移指令中的位移量比如sll $t0,$s1,4 的shamt就是4
下图是各种指令格式扩展后的32位立即数。
4)6中基本整数指令集
关于处理立即数还有两种变体(B/J),分支指令(B 类型)的立即数字段在 S 类型的基础上旋转了 1 位。跳转指令(J类型)的直接字段在 U 类型的基础上旋转了 12 位。因此,RISC-V 实际上只有四种基本格式,但我们可以保守地认为它有六种格式[5]
S和B格式之间的唯一区别是,12位立即数字段用于以B格式中2的倍数对分支偏移进行编码。在硬件中,将指令编码的所有位按常规左移一位,而不是将中间位(imm[10:1])和符号位保持在固定位置,而S格式的最低位(inst[7])将高阶位编码为B格式。
类似地,U和J格式之间的唯一区别是,20位立即数左移12位以形成U立即数,左移1位以形成J立即数。选择U和J格式的指令位的位置是为了最大限度地与其他格式和彼此重叠。 [1]

![Types of immediate produced by RISC-V instructions. The fields are labeled with the
instruction bits used to construct their value. Sign extension always uses inst[31].](http://raw.githubusercontent.com/GreensCH/blog-drawbed/main/common/image-20220511172510014.png)
每种基本指令格式产生的立即数,并标记为显示哪个指令位(inst[y])产生立即数值的每一位
Figure shows the immediates produced by each of the base instruction formats, and is labeled
to show which instruction bit (inst[y]) produces each bit of the immediate value.Types of immediate produced by RISC-V instructions. The fields are labeled with the instruction bits used to construct their value. Sign extension always uses inst[31].
- R-type: register-register
- R-typed 指令是最常用的运算指令,具有三个寄存器地址,每个都用 5bit 的数表示。指令的操作由 7 位的 opcode、7 位的 funct7 以及 3 位的 funct3 共同决定的。R-typed 是不包含立即数的所有整数计算指令,一般表示寄存器-寄存器操作的指令。
- I-type: short immediates and loads
- I-typed 具有两个寄存器地址和一个立即数,其中一个是源寄存器 rs1,一个是目的寄存器 rd,指令的高 12 位是立即数。指令的操作仅由 7 位的 opcode 和 3 位的funct3两者决定。值得注意的是,在执行运算时需要先把 12 位立即数扩展到 32 位之后再进行运算。I-typed 指令相当于将 R-typed 指令格式中的一个操作数改为立即数。一般表示短立即数和访存 load 操作的指令
- S-type: stores
- S-typed 的指令功能由 7 位 opcode 和 3 位 funct3 决定,指令中包含两个源寄存器和指令的imm[31:25]和 imm[11:7]构成的一个12位的立即数,在执行指令运算时需要把12 位立即数扩展到 32 位,然后再进行运算,S-typed 一般表示访存 store 操作指令,如存储字(sw)、半字(sh)、字节(sb)等指令
- B-type: conditional branches, a variation of S-type
- B-typed 的指令操作由 7 位 opcode 和 3 位 funct3 决定,指令中具有两个源寄存器和一个 12 位的立即数,该立即数构成是指令的第32位是 imm[12]、第7位是imm[11]、25 到 30 是 imm[10:5]、8 到 11 位是 imm[4:1],同样的,在执行运算时需要把12 位立即数扩展到 32 位,然后再进行运算。B-typed 一般表示条件跳转操作指令,如相等(beq)、不相等(bne)、大于等于(bge)以及小于(blt)等跳转指令。
- U-type: long immediates
- U-typed 的指令操作仅由 7 位 opcode 决定,指令中包括一个目的寄存器 rd 和高20 位表示的 20 位立即数。U-typed 一般表示长立即数操作指令,例如 lui 指令,将立即数左移 12 位,并将低 12 位置零,结果写回目的寄存器中。
- J-type: unconditional jumps, a variation of U-type
- J-typed 的指令操作由 7 位 opcode 决定,与 U-typed 一样只有一个目的寄存器 rd和一个 20 位的立即数,但是 20 位的立即数组成不同,即指令的 31 位是 imm[20]、 12 到 19 位是 imm[19:12]、20 位是 imm[11]、21 到 30 位是 imm[10:1],J-typed 一般表示无条件跳转指令,如 jal 指令。
[参考资料——外网概述]:https://devopedia.org/risc-v-instruction-sets
[参考资料——6种类型分类详解]:https://blog.csdn.net/qq_39507748/article/details/120150936
5)ABI与寄存器
在Risc-V汇编语言中,每个通用寄存器都有一个对应的ABI名字,也就是说在汇编语言中,x1等价于ra,它们都会汇编成相同的机器码。对于RV32I,通用寄存器是32位的寄存器,xlen=32;对于RV64I,通用寄存器是64位寄存器,xlen=64
| 寄存器 | ABI名字 | 注释 | Saver |
|---|---|---|---|
| x0 | zero | Hard-wired zero,常数0 | |
| x1 | ra | Return address | caller,调用函数的指令pc |
| x2 | sp | Stack pointer | callee,被调用的函数指令pc |
| x3 | gp | Global pointer | |
| x4 | tp | Thread pointer | |
| x5 | t0 | Temporary/alternate link register | caller |
| x6 | t1 | Temporaries | caller |
| x7 | t2 | Temporaries | caller |
| x8 | s0/fp | Saved register/frame pointer | caller |
| x9 | s1 | Saved register | caller |
| x10 | a0 | Function arguments/return values | caller |
| x11 | a1 | Function arguments/return values | caller |
| x12 | a2 | Function arguments | caller |
| x13 | a3 | Function arguments | caller |
| x14 | a4 | Function arguments | caller |
| x15 | a5 | Function arguments | caller |
| x16 | a6 | Function arguments | caller |
| x17 | a7 | Function arguments | caller |
| x18 | s2 | Saved registers | caller |
| x19 | s3 | Saved registers | caller |
| x20 | s4 | Saved registers | caller |
| x21 | s5 | Saved registers | caller |
| x22 | s6 | Saved registers | caller |
| x23 | s7 | Saved registers | caller |
| x24 | s8 | Saved registers | caller |
| x25 | s9 | Saved registers | caller |
| x26 | s10 | Saved registers | caller |
| x27 | s11 | Saved registers | caller |
| x28 | t3 | Temporaries | caller |
| x29 | t4 | Temporaries | caller |
| x30 | t5 | Temporaries | caller |
| x31 | t6 | Temporaries | caller |
参考资料——博客RV32I基础整数指令集:https://www.cnblogs.com/mikewolf2002/p/11196680.html
6)说了那么半天,一共有多少指令呢?
RV32I:[8]
- 之前是47条指令
- 现在是41条指令,即40条基本指令+Zifencei扩展指令集:1个 (也就是fence.i扩展指令)
现在的47条指令:40条基本指令+1条Zifencei扩展指令 (也就是fence.i扩展指令)+6条csr指令
如果要实现RV32I还有机器模式,还需要6条csr指令
[13]Risc-V在多个hart(硬件线程)之间使用的是松散一致性模型,所以需要存储器fence指令。
fence指令能够保证存储器访问的执行顺序。在fence指令之前的所有存储器访问指令,比该fence之后的所有数据存储器访问指令先执行。
Risc-V架构将数据存储器的地址空间分为设备IO(device IO)和普通存储器空间,因此其读写访问分为四种类型:
I:设备读(device-input)
O:设备写(device-ouput)
R:存储器读(memory-reads)
W:存储器写(memory-writes)
[8]如果用更简单的实现方式
比如对于ECALL和EBREAK指令,调用时候,系统总是自陷(trap),所以可以减一条指令
以及用NOP指令模拟Fence指令(备注:在RISC V中,NOP指令是伪代码,其实就是addi, x0,x0,0),所以可以减一条指令
则RV32I甚至可以减少到38条指令:40-fence-nop=38RV64I
ADDIW rd, rs1, 0 将寄存器 rs1 的低32位的符号扩展写入寄存器 rd (伪指令 SEXT.W)
- RV32M[3],8条(不用实现)
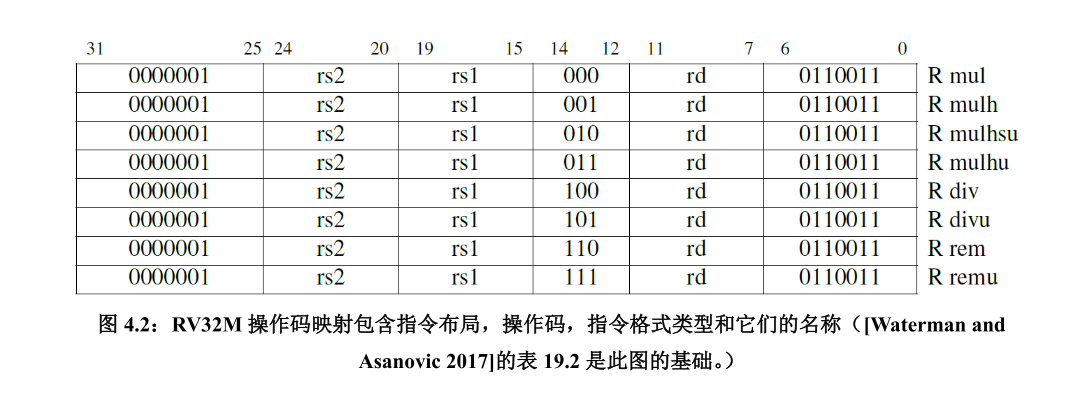
- RV64M
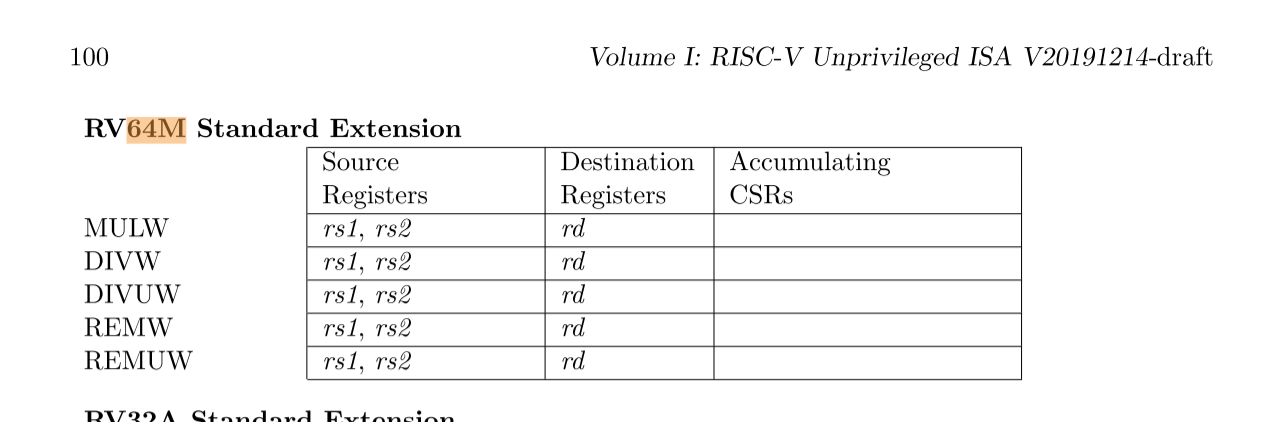
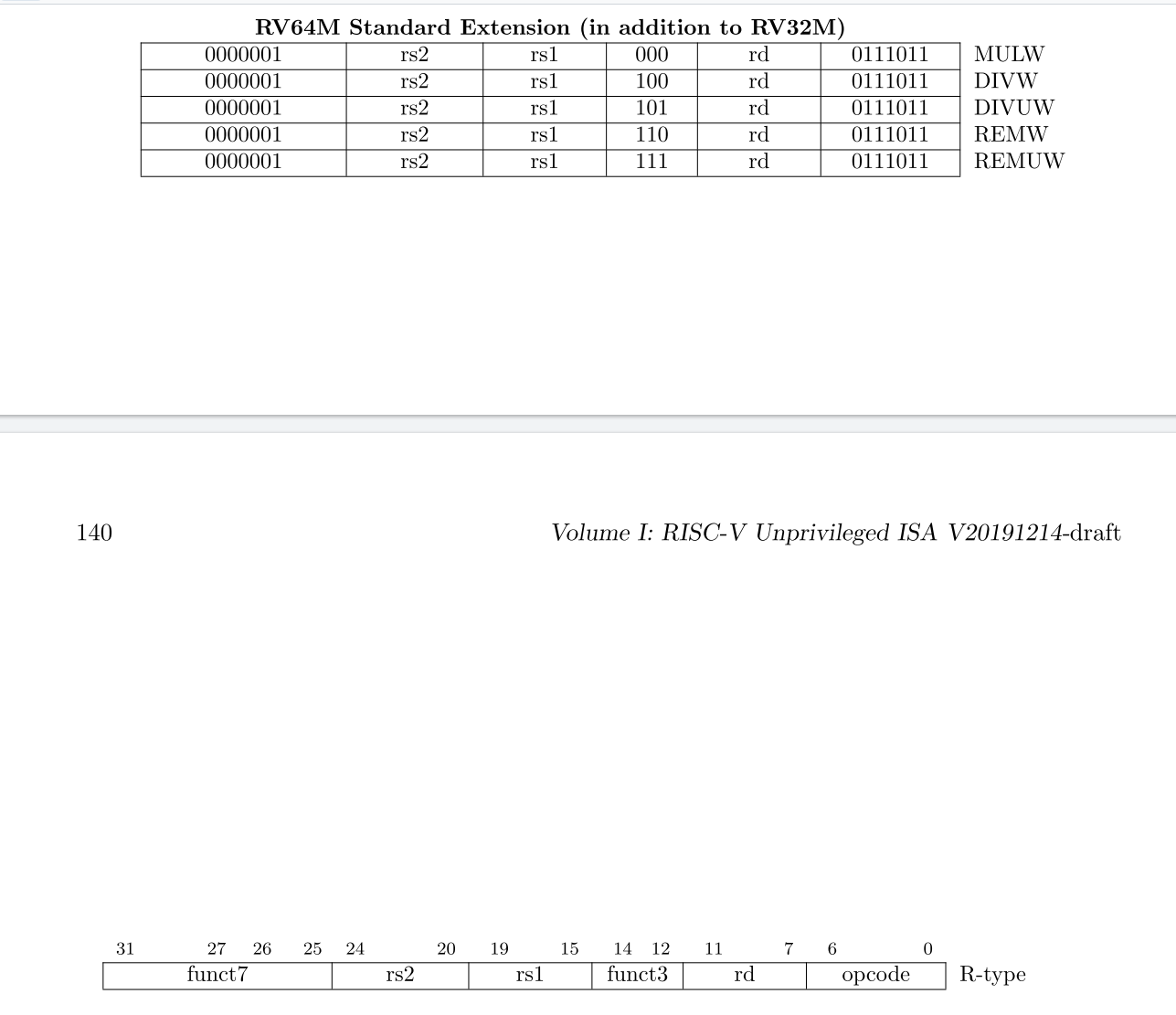
- RV64I:[8]
- 53:38+3+12 或者 41+12
- RV32I原版38条(40基本+1ifence)
- 改动3条位移指令(slli, srli,srai)
- 新增12条RV32I中没有的指令
- 53:38+3+12 或者 41+12
- RV64I指令集:41+12个 增41+12个
- RVZicsr指令集:6个 共6个
- [privileged instructions:4个] 共4个
1 | |
RV32I类型分析:[10]
U-type:2条,区分方式操作码不一样
- lui
- auipc
J-type:2条,区分方式操作码不一样
- jal
- jalr
B-type:6条
该指令将源寄存器1、2相比较,条件成立跳转至目标地址;将其携带的12位立即数做符号扩展,并左移1位,产生一个32位的立即数,与PC值相加,得到目标地址,可跳转至PC±4KB的地址范围;
I-type:5+9=14条;
主要功能1:5条,读取数据存储器的数据
立即数做符号扩展,与源寄存器1做逻辑运算,将结果存入目标寄存器;
其中比较指令:源寄存器1值小于符号扩展后的立即数,则条件成立,目标寄存器置1,否则置0;
而其他指令:将逻辑运算的结果存入目标寄存器;主要功能2:9条,立即数运算
立即数做符号扩展,与源寄存器1做逻辑运算,将结果存入目标寄存器;
其中比较指令:源寄存器1值小于符号扩展后的立即数,则条件成立,目标寄存器置1,否则置0;
而其他指令:将逻辑运算的结果存入目标寄存器;
S-type:3条
立即数做符号扩展,与源寄存器1相加作为 数据存储器的地址;而源寄存器2中的数据将存储到目标地址的数据存储器中;
汇编写法:R-type:10条
对源寄存器1、2进行运算,结果将被写入目标寄存器中;
RV32M
1)MUL Operations[1]
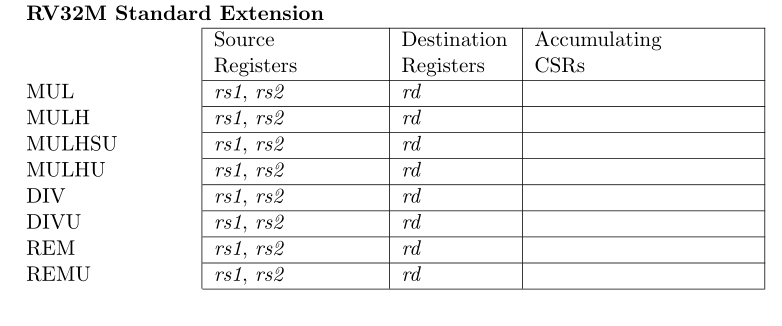
- MUL执行rs1与rs2的XLEN位×XLEN位乘法,并将较低的XLEN位放入目标寄存器。
- MULH、MULHU和MULHSU执行相同的乘法,但返回完整2×XLEN位乘积的高位XLEN位,分别用于有符号×有符号、无符号×无符号和有符号rs1×无符号rs2乘法。
如果需要同一产品的高位和低位,则建议的代码序列为:MULH[[S]U]rdh,rs1,rs2;MUL rdl、rs1、rs2(源寄存器说明符的顺序必须相同,rdh不能与rs1或rs2相同)。微体系结构可以将这些信息融合到一个乘法运算中,而不是执行两个单独的乘法运算。
2)DIV Operations[1]
DIV和DIVU将rs1除以rs2,并将其四舍五入到零,然后执行一个由XLEN位乘以有符号和无符号整数除法的XLEN位运算。
REM和REMU提供相应除法运算的剩余部分。对于REM,结果的符号等于股息的符号
对于有符号除法和无符号除法,它都认为除数=除数×商+余数
3)零除与除法溢出:
表8.1总结了按零除法和除法溢出的语义。
- 零除的商设置了所有位,零除的余数等于被除数。
- 只有当最负整数除以−1.带溢出的有符号除法的商等于被除数,余数为零。无法发生无符号除法溢出。

如果语言标准要求“零除”异常必须立即导致控制流更改,则每个除法操作只需添加一条分支指令,并且该分支指令可以在除法之后插入,并且通常不应被采用,从而增加很少的运行时开销。为简化除法器电路,无符号和有符号除法均返回所有位集的值。所有1的值既是无符号除法返回的自然值(表示最大的无符号数),也是简单无符号除法实现的自然结果。有符号除法通常使用无符号除法电路实现,指定相同的溢出结果可以简化硬件
RV64M
MUL Operations[1]
MULW是一条RV64指令,它将源寄存器的低32位相乘,将结果的低32位的符号扩展放入目标寄存器
在RV64中,MUL可用于获取64位乘积的高32位,但有符号参数必须是正确的32位有符号值,而无符号参数必须清除其上32位。如果不知道参数是符号扩展还是零扩展,另一种方法是将两个参数左移32位,然后使用MULH[[S]U]
2)DIV Operations[1]
DIVW和DIVUW是RV64指令,将rs1的低32位除以rs2的低32位,分别将其视为有符号整数和无符号整数,将32位商放入rd中,符号扩展到64位。
REMW和REMUW是RV64指令,分别提供相应的有符号和无符号余数运算。REMW和REMUW总是将32位结果扩展到64位,包括除以零。
3)Zmmul扩展
Zmmul扩展实现了M扩展的乘法子集。它添加了第8.1节中定义的所有指令,即:MUL、MULH、MULHU、MULHSU和(仅适用于RV64)MULW。编码与相应M扩展指令的编码相同。
3)溢出
除以零和除法溢出的语义如下图所示。除以零,结果商的所有位被置为 1, 也即是说,对于无符号除法来说,商是 2XLEN-1,对于有符号除法来说,商是-1。除以零,结果的余数等于被除数。有符号除法溢出仅当用最小的负整数, -2XLEN-1,除以-1 时,才会出现。有符号除法溢出的商等于被除数,余数等于零。无符号除法不会产生溢出

RV64I
RV64I将整数寄存器和支持的用户地址空间扩大到64位 (图2.1中的XLEN = 64)
- RV32I 带有指令布局,操作码,格式类型和名称的操作码映射。(此图基于[Waterman and Asanovi’c 2017]的表 19.2
![RV32I 带有指令布局,操作码,格式类型和名称的操作码映射。(此图基于[Waterman and
Asanovi'c 2017]的表 19.2。](http://raw.githubusercontent.com/GreensCH/blog-drawbed/main/common/image-20220511203959665.png)
- RV64I Satndard Extension (in addition to RV32I)
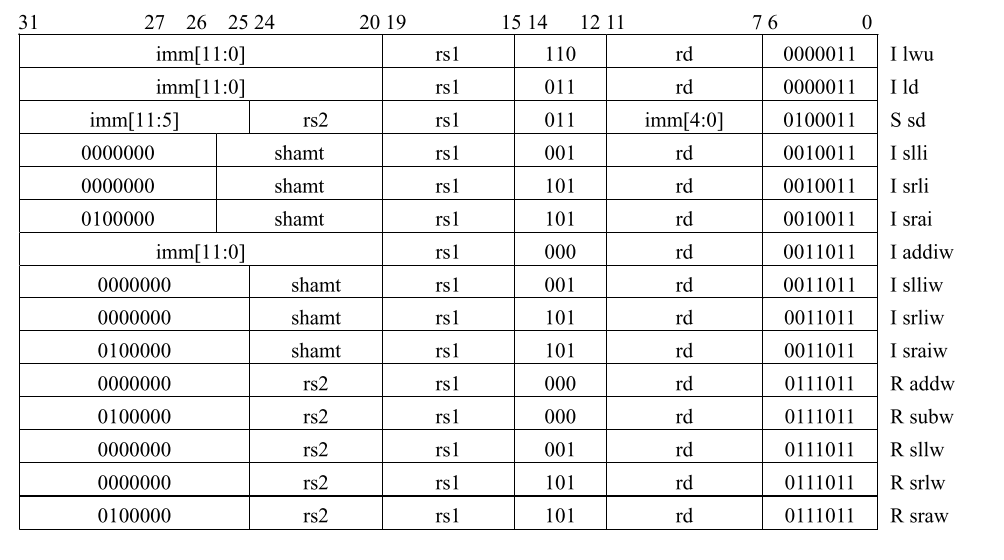
RV64特性(数依然从0开始)
编译器和调用约定保持不变,即所有32位值都以符号扩展格式保存在64位寄存器中。甚至32位无符号整数将位31扩展为位63到32。因此,无符号和有符号32位整数之间的转换是no-op,,从有符号32位整数转换为有符号64位整数也是如此。现有的64位宽SLTU和无符号分支比较仍然在此不变量下对无符号32位整数正确操作。类似地,对32位符号扩展整数的现有64位宽逻辑操作保留符号扩展属性。
添加和移位需要一些新指令(ADD[I]W/SUBW/SxxW),以确保32位值的合理性能。[1]
RV64 和 RV32 有什么不同总览
| RV32 | RV64 | |
|---|---|---|
| 寄存器位宽 | 32 | 64 |
| 指令位宽 | 32 | 32 |
| 指令 | RV32IMAFDC(RV64IMAFDC的子集?) | RV64IMAFDC |
| 寄存器种类 | 4096CSR+32G+32F+PC | 4096CSR+32G+32F+PC |
| RV64CPU是否可以跑RV32代码 | 应该可以跑 | 但是不能跑所有(不完全兼容)的RV32代码 |
1 | |
补充说明
FENCE
[14]:https://zhuanlan.zhihu.com/p/139797515
1)FENCE
对于简单的单hart理器来说,FENCE指令可以当做NOP来处理。如果想以简单的硬件实现FENCE的功能可以将其实现为一个trap,把工作量转嫁到软件上去。Rocket对于FENCE的实现是在decode stage停下来,知道cache通知它可以继续。
2)FENCE.I
RV32I also provides an instruction to synchronize the instruction stream with data memory accesses, called FENCE.I. A store to instruction memory is only guaranteed to be reflected by subsequent instruction fetches after a FENCE.I has been executed.
FENCE.I是条扩展指令,处理的是指令存取一致性的问题。假设我们的CPU里并无分离的I$和D$,也无prefetch buffer等任何缓存,可以想象,指令被修改了之后,下次执行此条指令一定是修改后的指令,并不需要做任何特殊处理。然而如果系统有了分离的I$和D$,或者有了prefetch buffer,我们就有可能面临这样的问题:指令所在的地址的内容被修改了,但是最新的值存在D$里,而I$或prefetch buffer还有旧的值,此时如果不加处理,就会得到不想要的结果。这个scenario存在于self-modifying的程序中,也存在于software breakpoint的调试过程中。
x86体系结构对于此类问题有着不同的解决方案,它通过snoop的方式监视I$和D$从而保证coherence。但这种实现方式的硬件实现代价较大,RISC-V引入FENCE.I指令解放了硬件实现,从软件层面来保证instruction coherence。
所以,FENCE.I和FENCE指令不同,并不是必须的指令,解决的也是不同类型的问题。
对于有I$的CPU来说,FENCE.I一般可以采用invalidate I$来解决(当然这不是唯一的途径),prefetch一并clear掉。如果只有prefetch buffer的就可以像处理跳转指令一样把prefetch buffer clear掉,就像Ibex的处理方式一样。
但是也不能对FENCE.I指令期望过高,它解决的仅仅是单hart上的code coherence问题。 其他hart上的code改动并不能保证一定被当前的hart及时取到。这个时候就需要在OS层面用诸如system call之类的软件方案去实现指令存取一致性。这也就是为什么FENCE.I指令被从I指令集移了出来的原因之一了,另一个原因是对于一些系统实现FENCE.I的代价太大。
CSR Control and Status Registers
- CSR地址映射的约定(原文查看卷II即可)
标准RISC-V ISA为多达4,096个csr留出12位编码空间(csr[11:0])。按照约定,CSR地址的前4位(CSR[11:8])根据权限级别对CSR的读写可访问性进行编码,最上面的两位(csr[11:10])表示寄存器是读/写(00、01或10)还是只读(11),接下来的两位(csr[9:8])编码可以访问csr的最低特权级别。
原文链接:https://blog.csdn.net/dai_xiangjun/article/details/123373303
RISCV 的交叉编译环境搭建
参考文章
- 我主要参考的:https://blog.csdn.net/qq_44881486/article/details/121712865
- 内容较全,有上面文章中的一些行为的解释:https://blog.csdn.net/weixin_42454243/article/details/124087611
- 正常的拉取步骤、riscv32版本可以参考这个configure、QEMU安装:https://blog.csdn.net/limanjihe/article/details/122373942
- 这里是一个汇总了不同版本的,配置选项的链接:https://blog.csdn.net/lizhao_yang_/article/details/121809405
- 一篇不明不白地博客:https://blog.csdn.net/qq_40836704/article/details/120391584
正文
方式一(主要介绍这一种):gitee riscv-toolchain
riscv工具链整个工程太大,在github下载再递归下载子文件夹,以国内的网络很容易超时断开。一般去码云gitee上面找镜像文件
1)clone riscv-toolchain
1 | |
- 建立git clone目录
- git clone riscv-toolchain
- 删除原有riscv-*子目录
2)clone submodule
1 | |
- 码云上的子模块的地址仍然为github的地址,所以需要分别拉取其子模块在码云上的镜像
- riscv-binutils与riscv-gdb来自于同一个仓库,且与本地要求的文件夹名称不同,需用命令指定本地名,riscv-gdb同理
补充内容:
1 | |
- 子模块对应的分支:(工具链可能会更新,要使用最新版本大家自行切换具体分支)
1 | |
3)下载依赖库
1 | |
4)配置与编译
1 | |
5)添加环境变量
1 | |
6)测试
1 | |
方式二:github riscv-toolchain
1 | |
其他问题
如何生成riscv64-unknown-linux-gnu-gcc
指定make linux,否则默认为unknown-elf
1 | |
riscv-gnu-toolchain不同版本
riscv-gnu-toolchain 工具链分elf-gcc,linux-gnu-gcc两个版本,以及他们对应的32位和64位版本。两个的主要区别在于参考链接:
- riscv32-unknown-elf-gcc,riscv64-unknown-elf-gcc:使用的riscv-newlib库(面向嵌入式的C库),而且只支持静态链接,不支持动态链接
- riscv32-unknown-linux-gnu-gcc,riscv64-unknown-linux-gnu-gcc:使用的是glibc标准库,支持动态链接
个人认为从名字上便可以区分两者的使用场景,如果是编译简单,较小的elf程序,使用elf-gcc版本即可,如果编译比较大的程序或者需要动态库(比如编译linux,或opencv库等),推荐使用linux-gnu-gcc版本
这里是一个汇总了不同版本的,配置选项的链接:https://blog.csdn.net/lizhao_yang_/article/details/121809405
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!