Scala(一):基础篇
1 概论
官方文档:https://docs.scala-lang.org/zh-cn/
1.1 导论
Scala来源于scalable(可扩展的)这个单词,它的可扩展性非常强
Scala基于JVM,和Java完全兼容,同样具有跨平台、可移植性好、方便的垃圾回收等特性
- Scala比Java更加面向对象
- Scala是一门函数式编程语言(java1.8引入的中的lamuda表达式就是函数编程的重要概念,实际上就是借鉴Scala)
- 同样运行在JVM上,可以与现存程序同时运行
- 可直接使用Java类库
- 同Java一样静态类型
- 语法和Java类似,比Java更加简洁(简洁而并不是简单),表达性更强。
关注点
- 类型推断、不变量、函数式编程、高级程序构造
- 并发:actor模型
- 和现有Java代码交互、相比Java异同和优缺
Scala更适合大数据的处理Scala对集合类型数据处理有非常好的支持Spark的底层用Scala编写
和Java关系:
1
2
3
4javac java
.java --------> .class ----------> run on JVM
.scala -------> .class ----------> run on JVM
scalac scala- Java很多语法源自Cpp
- Java面向对象不是很彻底,有八大基本数据类型,同时又有包装类型(继承自Object)
- 对更加复杂的高端应用
- 函数式编程语言可以解决上述问题
- Scala最重要的是引入了类型推断和lamuda表达式
1.2 总结特点
Scala是一门以Java虚拟机(JVM)为运行环境并将面向对象和函数式编程的最佳特性结合在一起的静态类型编程语言(静态语言需要提前编译的如:Java、c、c++等,动态语言如:js)
- Scala是一门多范式的编程语言,Scla支持面向对象和函数式编程。(多范式,就是多种编程方法的意思。有面向过程、面向对像、泛型、函数式四种程序设计方法)
- Scala源代码(.scala)会被编译成Java字节码(.class),然后运行于JVM文上,并可以调用现有的Java类库,实现两种语言的无缝对接。
- Scala单作为一门语言来看,非常的简洁高效。
- Scaa在设计时,马丁奥德斯基是参考了Java的设计思想,可以说Scala是源于Java,同时马丁奥德斯基也加入了自己的思想,将函数式编程语言的特点融合到JAVA中,因此,对于学习Java的同学,只要在学习Scala的过程中,搞清楚Scala和Java相同点和不同点,就可以快速的拿握Scaa这门语言
2 环境
2.1 交互式命令行
- 交互式执行环境(cmd直接输入scala):
1 | |

- 定义常量
1 | |
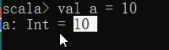
对比Java的system.out.println("");确实简洁不少
1 | |

- 推出交互式执行环境
1 | |
2.2 完整编译流程
和Java差不多
源程序
1 | |
object关键字:定义单例对象(直接定义对象而不是类)def关键字:声明函数或方法args:在类型前面,表明我们更关心参数而不是类型:Array[String]:Array集合类型,[String]一个泛型,表明内部是String的集合:Unit:返回值为void={}:函数体- 没有分号
编译生成字节码文件
1 | |
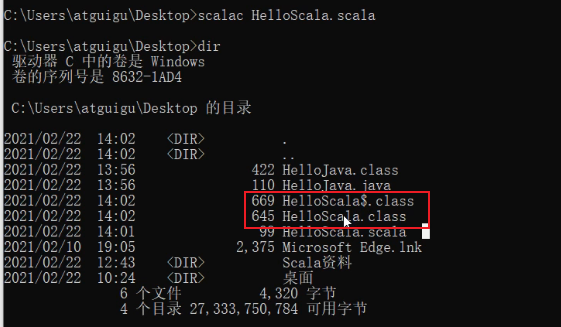
为什么有HelloScala$.class和HelloScala.class两个文件?
底层机制:
HelloScala.class:要执行程序的入口类
HelloScala$.class:上面类所属类,被调用
进一步补充:
如果编译的话会生成2个
.class字节码文件,HelloScala.class和HelloScala$.class。都是字节码但是不能通过java直接运行。但对于HelloWorld这个例子来说,java源代码编译而成的字节码是可以通过scala命令运行的。原因是没有引入Scala的库,添加
classpath就可以通过java执行scala编译成的字节码了:
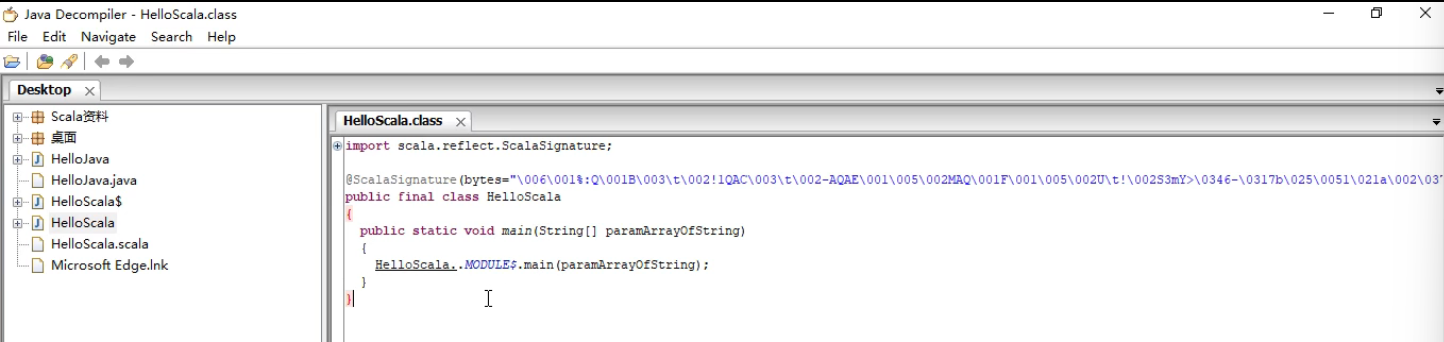
java -cp %SCALA_HOME%/lib/scala-library.jar; HelloScala使用Java Decompiler反编译字节码到java源文件可以看到引入Scala库的逻辑。并且:
- scala源文件中的
HelloScala对象编译后成为了一个类,但对象本身编译后就是生成的另一个类HelloScala$类的单例对象HelloScala$.MODULE$,称之为伴生对象。HelloScala$有一个main实例方法,HelloScala类的静态方法通过这个单例对象转调这个实例方法。完成打印。- Scala比Java更面向对象。
运行
1 | |

反编译
暂时不管项目配置,还是单文件编译执行为主,项目开发肯定要以包的形式组织可以使用IntelliJ IDEA开发,使用maven或者sbt进行项目配置
使用VSCode编辑器,安装插件Scala Syntax (official)和Scala (Mentals)
- 新建文件
HelloScala.scala
1 | |
- 可以使用插件CodeRunner直接快捷键运行。也可以在命令行编译为字节码后再运行:
1 | |
- 或者直接运行scala源文件:
1 | |
3 变量与数据类型
3.1 注释
- 和java一样
//单行/* */多行/** */文档,方法或者类前面,便于scaladoc生成文档。
3.2 变量与常量
1 | |
因为Scala的函数式编程要素,所以一个指导意见就是能用常量就不要用变量
- 推断类型:声明变量时,类型可以省略,编译器会自动推导
- 静态类型:类型经过给定或推导确定后就不能修改**
- 初始化:变量和常量声明时,必须有初始值
- 变量与常量:变量可变,常量不可变
- 引用类型常量:不能改变常量指向的对象,可以改变对象的字段
- 结尾:不以
;作为语句结尾,scala编译器自动识别语句结尾
3.3 Scala的基本类型
静态语言
Scala是静态语言,在编译期间会检查每个对象的类型。对于类型不匹配的非法操作,在编译时就能被发现。对于动态语言而言,这种非法操作需要等到运行时才能被发现,此时可能造成严重错误
静态语言相比诸如Python这样的动态语言在某些方面是有优势的。对于Chisel而言,我们就需要这种优势。因为Chisel需要编译成Verilog,我们不能产生非法的Verilog语句并且等到模块运行时才去发现它
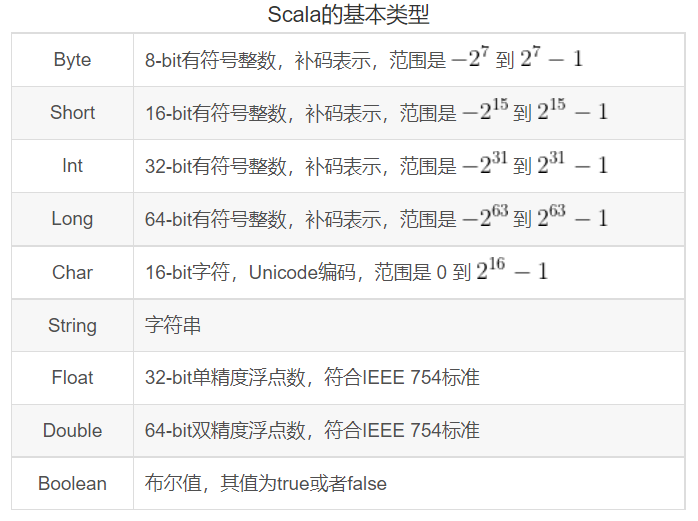
基本类型
Scala标准库定义了一些基本类型,如下表所示。除了“String”类型是属于java.lang包之外,其余都在Scala的包里。
定义变量
事实上,在定义变量时,应该指明变量的类型,只不过Scala的编译器具有自动推断类型的功能,可以根据赋给变量的对象的类型,来自动推断出变量的类型。
如果要显式声明变量的类型,或者无法推断时,则只需在变量名后面加上一个冒号“ : ”,然后在等号与冒号之间写出类型名即可。例如:
1 | |
字面量
整数有四种类型,默认情况下推断为Int类型。如果字面量的结尾有“l”或者“L”,则推断为Long类型。此外,Byte和Short则需要定义变量时显式声明。注意,赋给的字面值不能超过类型的表示范围。
整数字面量默认是十进制的,但如果以“0x”或者“0X”开头,则字面量被认为是十六进制。十六进制的字母不区分大小写。例如:
1 | |
浮点数的字面量都是十进制的,类型默认是Double类型。可以增加一个字母“e”或“E”,再添加一个整数作为指数,这样就构成10的n次幂。最末尾可以写一个“f”或者“F”,表示Float类型;也可以写一个“d”或者“D”,表示Double类型。
注意,Double类型的字面量不能赋给Float类型的变量。虽然Float允许扩展成Double类型,但是会发生精度损失
1 | |
字符字面量
**字符**字面量是以**单引号' '**包起来的一个字符,Scala中字符采用Unicode编码,可以用**'\u'编码号'**的方式来**转义**一个Unicode字符,而且**Unicode编码**可以出现在代码的任何地方,甚至是名称命名。此外,还支持转义字符。例如
1 | |
字符串字面量
字符串就是用双引号” “包起来的字符序列,长度任意,允许掺杂转义字符。此外,也可以用前后各三个双引号””” “””包起来,这样字符串里也能出现双引号,而且转义字符不会被解读
1 | |
字符串插值
Scala包括了一个灵活的机制来支持字符串插值,这使得表达式可以被嵌入在字符串字面量中并被求值。
- 第一种形式是s插值器,即在字符串的双引号前加一个s,形如s“…${表达式}…”,s插值器会对内嵌的每个表达式求值,对求值结果调用内置的toString方法,替换掉字面量中的表达式。从美元符号开始到首个非标识符字符(字母、数字、下划线和操作符的组合,以及反引号对包起来的字符串,称为标识符)的部分会被当作表达式,如果有非标识符字符,就必须放在花括号里,且左花括号要紧跟美元符号
- 第二种形式是raw插值器,它与s插值器类似,只不过不识别转义字符
- 第三种形式是f插值器,允许给内嵌的表达式加上printf风格的指令,指令放在表达式之后并以百分号开始。指令语法来自java.util.Formatter
1 | |
4 函数及其几种形式
4.1 定义一个函数
(1) 定义一个函数
Scala的函数定义以“def”开头,然后是一个自定义的函数名(推荐驼峰命名法),接着是用圆括号“( )”包起来的参数列表。在参数列表里,多个参数用逗号隔开,并且每个参数名后面要紧跟一个冒号以及显式声明的参数类型,因为编译器在编译期间无法推断出入参类型。写完参数列表后,应该紧跟一个冒号,再添加函数返回结果的类型。最后,再写一个等号“=”,等号后面是用花括号“{ }”包起来的函数体。例如:
1 | |
(2) 分号推断
在Scala的代码里,语句末尾的分号是可选的,因为编译器会自动推断分号。如果一行只有一条完整的语句,那么分号可写可不写;如果一行有多条语句,则必须用分号隔开,有三种情况句末不会推断出分号:
- 句末是以非法结尾字符结尾,例如以句点符号“.”或中缀操作符结尾
- 下一行的句首是以非法起始字符开始,例如以句点符号“.”开头
- 跨行出现的圆括号对“( )”或者方括号对“[ ]”,因为它们里面不能进行分号的自动推断,要么只包含一条完整语句,要么包含用分号显式隔开的多条语句。另外,花括号对“{ }”的里面可以进行分号的自动推断
为了简洁起见,同时不产生无意的错误和歧义,建议一行只写一条完整的语句,句末分号省略,让编译器自动推断。而且内层的语句最好比外一层语句向内缩进两个空格,使得代码层次分明。
(3) 函数返回结果
在Scala里,“return”关键字也是可选的。默认情况下,编译器会自动为函数体里的最后一个表达式加上“return”,将其作为返回结果。建议不要显式声明“return”,这会引发warning,而且使得代码风格看上去像指令式风格。
返回结果的类型也是可以根据参数类型和返回的表达式来自动推断的,也就是说,上例中的“: Int”通常是可以省略的。
返回结果Unit,表示没有值返回。也就是说,这是一个有副作用的函数,并不能提供任何可引用的返回结果。Unit类型同样可以被推断出来,但如果显式声明为Unit类型的函数,则即使函数体最后有一个可以返回具体值的表达式,也不会把表达式的结果返回。例如:
1 | |
(4) 函数体与等号
Scala的函数体是用花括号包起来的,这与C、C++、Java等语言类似。函数体里可以有多条语句,并自动推断分号、返回最后一个表达式。如果只有一条语句,那么花括号也可以省略。
Scala的函数定义还有一个等号,这使得它看起来类似数学里的函数“f(x) = …”。当函数的返回类型没有显式声明时,那么这个等号可以省略,但是返回类型一定会被推断成Unit类型,不管有没有值返回,而且函数体必须有花括号。当函数的返回类型显式声明时,则无论如何都不能省略等号。建议写代码时不要省略等号,避免产生不必要的错误,返回类型最好也显式声明。
总结:
- 花括号:
- 可以省略:只有一条语句
- 不可以省略:省略”=”时
- “=”:
- 可以省略:返回值没有显式声明,此时返回值一定是Unit类型
- 不可以省略:返回值显式声明
(5) 无参函数
无参函数可以写一个空括号作参数列表,或者不写。如果有空括号,那么调用时可以写也可以不写空括号;如果没有空括号,那么调用时就一定不能写空括号。原则上,无副作用的无参函数省略括号,有副作用的无参函数添加括号,这提醒使用者需要额外小心
无参函数总结:
- 写括号
- 建议有副作用函数
- 调用时可以不写括号,也可以写括号
- 不写括号
- 建议无副作用函数
- 调用时只可以不写括号
4.2 方法
方法其实就是定义在class、object、trait里面的函数,这种函数叫做“成员函数”或者“方法”,与多数oop(object-oriented programming)语言一样
4.3 嵌套函数
函数体内部还可以定义函数,这种函数的作用域是局部的,只能被定义它的外层函数调用,外部无法访问。局部函数可以直接使用外层函数的参数,也可以直接使用外层函数的内部变量。例如:
1 | |
4.4 函数字面量
函数式编程有两个主要思想,其中之一就是:函数是一等(first-class)的值。换句话说,一个函数的地位与一个Int值、一个String值等等,是一样的(既然一个Int值可以成为函数的参数、函数的返回值、定义在函数体里、存储在变量里,那么,作为地位相同的函数,也可以这样)。
你可以把一个函数当参数传递给另一个函数,也可以让一个函数返回一个函数,亦可以把函数赋给一个变量,又或者像定义一个值那样在函数里定义别的函数(即前述的嵌套函数)。就像写一个整数字面量“1”那样,Scala也可以定义函数的字面量。函数字面量是一种匿名函数的形式,它可以存储在变量里、成为函数参数或者当作函数返回值,其定义形式为:
1 | |
通常,函数字面量会赋给一个变量,这样就能通过“变量名(参数)”的形式来使用函数字面量。在参数类型可以被推断的情况下,可以省略类型,并且参数只有一个时,圆括号也可以省略。
- 圆括号省略:参数只有一个时
- 类型省略:类型可以被推断时
只保留函数体时,用下划线“_”作为占位符来代替参数。在参数类型不明确时,需要在下划线后面显式声明其类型。多个占位符代表多个参数(占位符也可以在大括号函数体内),即第一个占位符是第一个参数,第二个占位符是第二个参数……因此不能重复使用某个参数。例如:
1 | |
函数字面量作为返回值:无论是用“def”定义的函数,还是函数字面量,它们的函数体都可以把一个函数字面量作为一个返回结果,这样就成为了返回函数的函数;它们的参数变量的类型也可以是一个函数,这样调用时给的入参就可以是一个函数字面量。类型为函数的变量,其冒号后面的类型写法是“(参数1类型, 参数2类型,…) => 返回结果的类型”。例如:
1 | |
在第一个例子中,变量add被赋予了一个返回函数的函数字面量。在调用时,第一个括号里的“1”是传递给参数x,第二个括号里的“10”是传递给参数y。如果没有第二个括号,得到的就不是11,而是“(y: Int) => 1 + y”这个函数字面量。
在第二个例子中,函数aFunc的参数f是一个函数,并且该函数要求是一个入参为Int类型、返回结果也是Int类型的函数。在调用时,给出了函数字面量“x => x + 1”。这里没有显式声明x的类型,因为可以通过f的类型来推断出x必须是一个Int类型。在执行时,首先求值f(1),结合参数“1”和函数字面量,可以算出结果是2。那么,“f(1) + 1”就等于3了。
4.5 部分应用函数
部分应用函数(使得def函数实现函数一等值效果):给出一部分参数的情况下,赋值给一个变量
上面介绍的函数字面量实现了函数作为一等值的功能,而用“def”定义的函数也具有同样的功能,只不过需要借助部分应用函数的形式来实现。例如,有一个函数定义为“def max(…) …”,若想要把这个函数存储在某个变量里,不能直接写成“val x = max”的形式,而必须像函数调用那样,给出一部分参数,故而称作部分应用函数(如果参数全给了,就成了函数调用)。部分应用函数的作用,就是把def函数打包到一个函数值里,使它可以赋给变量,或当作函数参数进行传递。例如:
1 | |
变量a其实是获得了函数sum调用的返回结果,变量b则是获得了部分应用函数打包的sum函数,因为只给出了参数x和z的值,参数y没有给出。注意,没给出的参数用下划线代替,而且必须显式声明参数类型。变量c也是部分应用函数,只不过一个参数都没有明确给出。像这样一个参数都不给的部分应用函数,只需要在函数名后面给一个下划线即可,注意函数名和下划线之间必须有空格。
如果部分应用函数一个参数都没有给出,比如例子中的c,那么在需要该函数作入参的地方,下划线也可以省略(注:不要和前面给变量赋值的部分应用函数混淆,前者需要有下划线)。例如:
1 | |
4.6 闭包
一个函数除了可以使用它的参数外,还能使用定义在函数以外的其他变量。
函数的参数称为绑定变量,因为完全可以根据函数的定义得知参数的信息
函数以外的变量称为自由变量,因为函数自身无法给出这些变量的定义
这样的函数称为闭包,因为它要在运行期间捕获自由变量,让函数闭合,定义明确。自由变量必须在函数前面定义,否则编译器就找不到,会报错。
闭包捕获的自由变量是闭包创建时活跃的那个自由变量,后续若新建同名的自由变量来覆盖前面的定义,由于闭包已经闭合完成,所以新自由变量与已创建的闭包无关。如果闭包捕获的自由变量本身是一个可变对象(例如var类型变量),那么闭包会随之改变。例如:
1 | |
4.7 函数的体术调用形式
(1)具名参数(就是普通用法)
普通函数调用形式是按参数的先后顺序逐个传递的,但如果调用时显式声明参数名并给其赋值,则可以无视参数顺序。按位置传递的参数和按名字传递的参数可以混用,例如:
1 | |
(2)默认参数值(和以前学的一样)
1 | |
(3)重复参数(类似C中的arg*)
Scala允许把函数的最后一个参数标记为重复参数
形式为在最后一个参数的类型后面加上星号“*”。重复参数的意思是可以在运行时传入任意个相同类型的元素,包括零个。类型为“T*”的参数的实际类型是“Array[T]”,即若干个T类型对象构成的数组(尽管是T类型的数组,但要求传入参数的类型仍然是T,如果传入的实参是T类型对象构成的数组,则会报错,除非用“变量名: _*”的形式告诉编译器把数组元素一个一个地传入)
1 | |
4.8 柯里化
对大多数编程语言来说,函数只能有一个参数列表,但是列表里可以有若干个用逗号间隔的参数。
Scala有一个独特的语法——柯里化,也就是一个函数可以有任意个参数列表。
柯里化往往与另一个语法结合使用:当参数列表里只有一个参数时,在调用该函数时允许单个参数不用圆括号包起来,改用花括号也是可行的。
这样做的好处是:在自定义类库时,自定义方法就好像“if(…) {…}”、“while(…) {…}”、“for(…) {…}”等内建控制结构一样,让人看上去以为是内建控制,丝毫看不出是自定义语法。例如:
1 | |
4.9 传名参数(把函数作为形参情况下的简洁用法)
4.4介绍了函数字面量如何作为函数的参数进行传递,以及如何表示类型为函数时参数的类型。如果某个函数的入参类型是一个无参函数,那么通常的类型表示法是“() => 函数的返回类型”。在调用这个函数时,给出的参数就必须写成形如“() => 函数体”这样的函数字面量
(1)传名参数是什么
为了让代码看起来更舒服,也为了让自定义控制结构更像内建结构,Scala又提供了一个特殊语法——传名参数。
传名参数是类型是一个无参函数的函数入参。传名参数的类型表示法是“=> 函数的返回类型”,即相对常规表示法去掉了前面的空括号。在调用该函数时,传递进去的函数字面量则可以只写“函数体”,去掉了“() =>”。例如:
1 | |
(2)调用函数与传名参数的一致性写法
可以看到,传名参数使得代码更加简洁、自然,而常规写法则很别扭。事实上,predicate的类型可以改成Boolean的一个变量,而不必是一个返回Boolean的函数,这样调用函数时与传名参数是一致的。例如:
1 | |
(3)调用机制说明
尽管byNameAssert和boolAssert在调用形式上是一样的,但是两者的运行机制却不完全一样。如果给函数的实参是一个表达式,比如“5 > 3”这样的表达式,那么boolAssert在运行之前会先对表达式求值,然后把求得的值传递给函数去运行。而myAssert和byNameAssert则不会一开始就对表达式求值,它们是直接运行函数,直到函数调用入参时才会对表达式求值,也就是例子中的代码运行到“!predicate”时才会求“5 > 3”的值。
为了说明这一点,可以传入一个产生异常的表达式,例如除数为零的异常。例子中,逻辑与“&&”具有短路机制:如果&&的左侧是false,那么直接跳过右侧语句的运行(事实上,这种短路机制也是通过传名参数实现的)。所以,布尔型参数版本会抛出除零异常,常规版本和传名参数版本则不会发生任何事。例如:
1 | |
如果把变量assertionEnabled设置为true,让&&右侧的代码执行,那么三个函数都会抛出除零异常:
1 | |
4.10 章节总结
本章内容是对Scala的函数的讲解,重点在于理解函数作为一等值的概念,函数字面量的作用以及部分应用函数的作用。在阅读复杂的代码时,常常遇见诸如“def xxx(f: T => U, …) …”或 “def xxx(…): T => U”的代码,要理解前者表示需要传入一个函数作为参数,后者表示函数返回的对象是一个函数。在学习初期,理解函数是一等值的概念可能有些费力,通过大量阅读和编写代码才能熟能生巧。同时不要忘记前一章说过,函数的参数都是val类型的,在函数体内不能修改传入的参数。
5 类和对象
5.1 类
说了一堆废话,和Java差不多就是
在Scala里,类是用关键字“class”开头的代码定义。它是对象的蓝图,一旦定义完成,就可以通过“new 类名”的方式来构造一个对象。而这个对象的类型,就是这个类。换句话说,一个类就是一个类型,不同的类就是不同的类型。在后续的章节中,会讲到类的继承关系,以及超类、子类和子类型多态的概念。
在类里可以定义val或var类型的变量,它们被称为“字段”;还可以定义“def”函数,它们被称为“方法”;字段和方法统称“成员”。字段通常用于保存对象的状态或数据,而方法则用于承担对象的计算任务。字段也叫“实例变量”
介绍对象在操作系统中的情况:
因为每个被构造出来的对象都有其自己的字段。在运行时,操作系统会为每个对象分配一定的内存空间,用于保存对象的字段。方法则不同,对所有对象来说,方法都是一样的程序段,因此不需要为某个对象单独保存其方法。而且,方法的代码只有在被调用时才会被执行,如果一个对象在生命周期内都没有调用某些方法,那么完全没必要浪费内存为某个对象去保存这些无用的代码
访问对象:
需要注意的是,val类型的变量只能与初始化时的对象绑定,不能再被赋予新的对象(相同类也不行)
1 | |
Scala的类成员默认都是公有的,没有“public”这个关键字,有private作为私有成员,示例代码如下:
1 | |
5.2 类的构造方法
(1)主构造方法
Scala不需要显式定义构造方法 ,而是把类内部非字段、非方法的代码都当作“主构造方法”
- 大白话:没有用函数框框起来的都是主构造方法
类名后面可以定义若干个参数列表,用于接收参数,这些参数将在构造对象时用于初始化字段并传递给主构造方法使用。例如:
1
2
3
4
5
6
7
8
9scala> class Students(n: String) {undefined
| val name = n
| println("A student named " + n + " has been registered.")
| }
defined class Students
scala> val stu = new Students("Tom")
A student named Tom has been registered.
stu: Students = Students@5464eb28
(了解)在这个例子中,Students类接收一个String参数n,并用n来初始化字段name。这样做,就无需像之前那样把name定义成var类型,而是使用函数式风格的val类型,而且不再需要一个register方法在构造对象时来更新name的数据
函数println既不是字段,也不是方法定义,所以被当成是主构造函数的一部分。在构造对象时,主构造函数被执行,因此在解释器里打印了相关信息
(2)辅助构造方法
除了主构造方法,还可以定义若干个辅助构造方法。辅助构造方法都是以“def this(……)”来开头的,而且第一步行为必须是调用该类的另一个构造方法,即第一条语句必须是“this(……)”——要么是主构造方法,要么是之前的另一个辅助构造方法。这种规则的结果就是任何构造方法最终都会调用该类的主构造方法,使得主构造方法成为类的单一入口。例如:
1 | |
在这个例子中,定义了一个辅助构造方法,该方法是无参的,其行为也仅是给主构造方法传递一个字符串“None”。在后面创建对象时,缺省了参数,这样与主构造方法的参数列表是不匹配的,但是与辅助构造方法匹配,所以stu指向的对象是用辅助构造方法构造的。
在Java里,辅助构造方法可以调用超类的构造方法,而Scala加强了限制,只允许主构造方法调用超类的构造方法(详情见后续章节)。这种限制源于Scala为了代码简洁性与简单性做出的折衷处理。
(3)析构函数(也就是没有)
因为Scala没有指针,同时使用了Java的垃圾回收器,所以不需要像C++那样定义析构函数
(4)私有主构造方法
在类名与类的参数列表之间加上关键字“private”,那么主构造方法就是私有的,只能被内部定义访问,外部代码构造对象时就不能通过主构造方法进行,而必须使用其他公有的辅助构造方法或工厂方法(专门用于构造对象的方法)。例如:
1 | |
5.3 重写toString方法
toString构造完一个对象时自动被调用的那个方法
细心的读者会发现,在前面构造一个Students类的对象时,Scala解释器打印了一串晦涩的信息“Students@7509b8e7”。这其实来自于Students类的toString方法,这个方法返回一个字符串,并在构造完一个对象时被自动调用,返回结果交给解释器打印。该方法是所有Scala类隐式继承来的,如果不重写这个方法,就会用默认继承的版本。
默认的toString方法来自于java.lang.Object类,其行为只是简单地打印类名、一个“@”符号和一个十六进制数。如果想让解释器输出更多有用的信息,则可以自定义toString方法。不过,这个方法是继承来的,要重写它必须在前面加上关键字“override”(后续章节会讲到override的作用)。例如:
1 | |
5.4 方法重载
在类里定义了多个同名的方法,但是每个方法的参数(主要是参数类型)不一样,那么就称这个方法有多个不同的版本。这就叫方法重载,它是面向对象里多态属性的一种表现。这些方法虽然同名,但是它们是不同的,因为函数真正的特征标是它的参数,而不是函数名或返回类型。
注意重载与前面的重写的区别,重载是一个类里有多个不同版本的同名方法,重写是子类覆盖定义了超类的某个方法。
5.5 类的参数
- 前面的例子:从前面的例子可以发现,很多时候类的参数仅仅是直接赋给某些字段。
- 参数自动复制到内部成员:Scala为了进一步简化代码,允许在类参数前加上val或var来修饰,这样就会在类的内部会生成一个与参数同名的公有字段。构造对象时,这些参数会直接复制给同名字段。
- 参数限定权限:除此之外,还可以加上关键字private、protected或override来表明字段的权限(关于权限修饰见后续章节)。如果参数没有任何关键字,那它就仅仅是“参数”,不是类的成员,只能用来初始化字段或给方法使用。外部不能访问这样的参数,内部也不能修改它。例如:
1 | |
5.6 单例对象与伴生对象(静态变量)
在Scala里,除了用new可以构造一个对象,也可以用“object”开头定义一个对象。它类似于类的定义,只不过不能像类那样有参数,也没有构造方法。因此,不能用new来实例化一个object的定义,因为它已经是一个对象了。
单例对象定义:用“object”开头定义一个对象对象和用new实例化出来的对象没有什么区别,只不过new实例的对象是以类为蓝本构建的,并且数量没限制,而object定义的对象只能有这一个,故而得名“单例对象”。
class:定义一个类
object:定义一个单例对象
new:实例化一个对象
伴生对象定义:如果某个单例对象和某个类同名,那么单例对象称为这个类的“伴生对象”,同样,类称为这个单例对象的“伴生类”。伴生类和伴生对象必须在同一个文件里,而且两者可以互访对方所有成员。
- 同名的某个类:伴生类
- 同名的单例对象:伴生对象
- 伴生类和伴生对象必须在同一文件中
在C++、Java等oop语言里,类内部可以定义静态变量。这些静态变量不属于任何一个用new实例化的对象,而是它们的公有部分。Scala追求纯粹的面向对象属性,即所有的事物都是类或对象,但是静态变量这种不属于类也不属于对象的事物显然违背了Scala的理念。所以,Scala的做法是把类内所有的静态变量从类里移除,转而集中定义在伴生对象里,让静态变量属于伴生对象这个独一无二的对象。
既然单例对象和new实例的对象一样,那么类内可以定义的代码,单例对象同样可以拥有。例如,单例对象里面可以定义字段和方法。Scala允许在类里定义别的类和单例对象,所以单例对象也可以包含别的类和单例对象的定义。
单例对象的作用:
- 用作伴生对象
- 打包某方面功能的函数系列成为一个工具集
- 包含主函数成为程序的入口
“object”后面定义的单例对象名可以认为是这个单例对象的名称标签,因此可以通过句点符号访问单例对象的成员——“单例对象名.成员”,也可以赋给一个变量——“val 变量 = 单例对象名”,就像用new实例的对象那样。
名称标签:“object”后面定义的单例对象名
定义方式:object可以赋值给一个变量,就和new实例化一样
例如:
1 | |
object.type:
前面说过,定义一个类,就是定义了一种类型。从抽象层面讲,定义单例对象却并没有定义一种类型。实际上每个单例对象有自己独特的类型,即object.type(可以认为新类型出现了,只不过这个类型并不能用来归类某个对象集合,等同于没有定义新类型)
即使是伴生对象也没有定义类型,而是由伴生类定义了同名的类型。后续章节将讲到,单例对象可以继承自超类或混入特质,这样它就能出现在需要超类对象的地方。例如下面的例子中,可以明确看到X.type和Y.type两种新类型出现,并且是不一样的:
1 | |
5.7 工厂对象与工厂方法
如果定义一个方法专门用来构造某一个类的对象,那么这种方法就称为“工厂方法”。包含这些工厂方法集合的单例对象,也就叫“工厂对象” 。
工厂对象的使用场景和好处:
+ 通常,**工厂方法会定义在伴生对象里**。
+ 当一系列类存在继承关系时,可以在基类的伴生对象里定义一系列对应的工厂方法。
+ **使用工厂方法的好处**是可以不用直接使用new来实例化对象,改用方法调用,而且方法名可以是任意的,这样**对外隐藏了类的实现细节**。例如:
1 | |
将文件students.scala编译后,并在解释器里用“import Students._”导入单例对象后,就能这样使用:
1 | |
5.8 一个特殊的方法:apply方法
如果定义了这个方法,那么既可以显式调用——“对象.apply(参数)” ,也可以隐式调用——“对象(参数)”。隐式调用时,编译器会自动插入缺失的“.apply”。如果apply是无参方法,应该写出空括号,否则无法隐式调用。无论是类还是单例对象,都能定义这样的apply方法。
apply方法特殊点:这个方法可以进行隐式调用,如果是无参方法应有空括号,无论是类还是单例对象都可以定义apply方法
apply方法的调用:
1 | |
apply方法使用场景:
- 在伴生对象里定义名为apply的工厂方法,就能通过“伴生对象名(参数)”来构造一个对象。
- 也常常在类里定义一个与类相关的、具有特定行为的apply方法,让使用者可以隐式调用,进而隐藏相应的实现细节。例如:
1 | |
5.9 主函数
主函数是Scala程序唯一的入口,即程序是从主函数开始运行的。要提供这样的入口,则必须在某个单例对象里定义一个名为“main”的函数,而且该函数只有一个参数,类型为字符串数组Array[String],函数的返回类型是Unit。任何符合条件的单例对象都能成为程序的入口。例如:
1 | |
使用命令
scalac students2.scala main.scala将两个文件编译后用命令
scala Start 参数1 参数2来运行程序。(命令里的“Start”就是包含主函数的单例对象的名字,后面可以输入若干个用空格间隔的参数。这些参数被打包成字符串数组供主函数使用,也就是代码里的args(0)、args(1)。)
示例代码如下:
1 | |
主函数的一种简化写法是让单例对象混入“App”特质(特质在后续章节讲解),这样就只要在单例对象里编写主函数的函数体。例如:
1 | |
将文件编译后,就可以如下使用:
1 | |
5.10 章节总结
本章讲解了Scala的类和对象,从中可以初窥Scala在语法精简和便捷上的努力。难点是理解单例对象的概念、类与类型的关系和工厂方法的作用。如果读者有其他oop语言基础,在这里也并不是能一下就接受Scala的语法。最后一个重点就是学会灵活使用apply方法。
6 操作符即方法
6.1 操作符在Scala里的解释
在诸如C++、Java等oop语言里,定义了像byte、short、int、char、float之类的基本类型,但是这些基本类型不属于面向对象的范畴。就好比C语言也有这些类型,但是C语言根本没有面向对象的概念。 比如只能说“1”是一个int类型的常量,却不能说它是一个int类型的对象。与之对应的,这些语言还定义了与基本类型相关的操作符。例如,有算术操作符加法“+”,它可以连接左、右两个操作数,然后算出相应的总和。
前面提到,Scala追求纯粹的面向对象,像这种不属于面向对象范畴的基本类型及其操作符都是有违宗旨的。那么,Scala如何实现这些基本类型呢?实际在Scala标准库里定义了“class Byte”、“class Short”、“class Char”、“class Int”、“class Long”、“class Float”、“class Double”、“class Boolean”和“class Unit”九种值类,只不过这些类是抽象的、不可继承的,因此不能通过“new Int”这种语句来构造一个Int对象,也不能编写它们的子类,它们的对象都是由字面量来表示。例如,整数字面量“1”就是一个Int的对象。在运行时,前八种值类会被转换成对应的Java基本类型。第九个Unit类对应Java的“void”类型,即表示空值,这样就能理解返回值类型为Unit的、有副作用的函数其实是空函数。Unit类的对象由一个空括号作为字面量来表示。
简而言之,Scala做到了真正的“万物皆对象”。
还有,与基本类型相关的操作符该如何处理呢?严格来讲,Scala并不存在操作符的概念,这些所谓的操作符,例如算术运算的加减乘除,逻辑运算的与或非,比较运算的大于小于等等,其实都是定义在“class Int”、“class Double”等类里的成员方法。也就是说,在Scala里,操作符即方法。例如,Int类定义了一个名为“+”的方法,那么表达式“1 + 2”的真正形式应该是“1.+(2)”。它的释义是:Int对象“1”调用了它的成员方法“+”,并把Int对象“2”当作参数传递给了该方法,最后这个方法会返回一个新的Int对象“3”。
//////重要使用方法:类似操作符的方法调用(省略句号)///////
推而广之,“操作符即方法”的概念不仅仅限于九种值类的操作符,Scala里任何类定义的成员方法都是操作符,而且方法调用都能写成操作符的形式:去掉句点符号,并且方法参数只有一个时可以省略圆括号。示例代码:
1 | |
6.2 三种操作符
(1)前缀操作符(+-!~)
写在操作数前面的操作符称为前缀操作符,并且操作数只有一个。
前缀操作符对应一个无参方法,操作数是调用该方法的对象。前缀操作符只有“+”、“-”、“!”和“~”四个,相对应的方法名分别是“unary_+”,“unary_-”、“unary_!”和“unary_~”
如果自定义的方法名是 “unary_”加上这四个操作符之外的操作符,那么就不能写成前缀操作符的形式。假设定义了方法“unary_*”(意思是unary_与乘号结合),那么写成“p”的形式让人误以为这是一个指针,实际Scala并不存在指针,因此只能写成“p.unary_\”或后缀操作符“p unary_*”的形式。例如:
1 | |
(2)中缀操作符(可以带很多操作数)
中缀操作符的左右两边都接收操作数,它对应普通的有参方法。两个操作数中的一个是调用该方法的对象,一个是传入该方法的参数,参数那一边没有数量限制,只是多个参数需要放在圆括号里。
Scala规定,以冒号“ : ”结尾的操作符,其右操作数是调用该方法的对象,其余操作符都是把左操作数当调用该方法的对象。 例如:
1 | |
对于系统打印函数“print”、“printf”和“println”,其实也是中缀操作符,不过左侧的操作数是调用对象——控制台Console,右侧是要打印的内容。例如:
1 | |
(3)后缀操作符(类似方法调用)
写在操作数后面的操作符称为后缀操作符,并且操作数只有一个,即调用该方法的对象。
后缀操作符也对应一个无参方法,但是要注意方法名如果构成前缀操作符的条件,那么既可以写成前缀操作符,也可以把完整的方法名写成后缀操作符。例如:
1 | |
6.3 操作符的优先级和结核性
(1)优先级
在数学运算中,乘、除法的优先级要高于加、减法,这是算术操作符的优先级。Scala也保留了这种特性,并有一套判断操作符优先级的规则:通过操作符的首个字符来判断。因为操作符都是方法,所以也就是通过方法名的首个字符来比较优先级,注意前缀操作符的方法名要去掉关键字。当然,圆括号内的优先级是最高的,圆括号可以改变操作符的结合顺序。
上图给出了各种字符的优先级顺序。例如,常规算术运算法则在计算表达式“1 + 2 3”时,会先算乘法,后算加法。类似地,如果有一个表达式“1 +++ 2 ** 3”,那么结合顺序就是“1 +++ (2 * 3)”。
这个规则有一个例外(就是比较,+=一系列的,不用看):如果操作符以等号结尾,并且不是“>=”、“<=”、“==”或“!=”四个比较操作符之一,那么就认为是赋值操作符,优先级最低。例如,表达式“sum *= 1 + 2”会先算“1 + 2”,再把得出的3和sum相乘并赋给sum。也就是说,“*=”的优先级并不会因为以乘号开头就比加号高,而是被当作了一种赋值操作。
(2)结合性(注意冒号这玩意就行)
一般情况下,同级的操作符都是从左往右结合的。但是,前面说了,以冒号结尾的中缀操作符的调用对象在右侧,所以这些操作符是从右往左结合的。例如,“a + b + c + d”的结合顺序是“((a + b) + c) + d”,而“a ::: b ::: c ::: d”的结合顺序则是“a ::: (b ::: (c ::: d))”。
一个好的编程习惯是让代码简洁易懂,不造成歧义。所以,在操作符的结合顺序不能一眼就看明白时,最好加上圆括号来表示前后顺序,即使不加圆括号也能得到预期的结果。例如,想要得到“x + y << z”的默认结果,最好写成“(x + y) << z”,以便阅读。
(3)预设操作符
| + | 算术加法 |
|---|---|
| - | 算术减法 |
| * | 算术乘法 |
| / | 算术除法 |
| % | 算术取余 |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| == | 等于 |
| != | 不等于 |
| &&、& | 逻辑与,前者短路,后者不短路 |
| ||、| | 逻辑或,前者短路,后者不短路 |
| ! | 逻辑非 |
| & | 位与 |
| | | 位或 |
| ^ | 位异或 |
| ~ | 位取反 |
| >> | 算术右移 |
| << | 左移 |
| >>> | 逻辑右移 |
6.5 对象的相等性
在编程时,常常需要比较两个对象的相等性。其实相等性有两种:
- 自然相等性,也就是常见的相等性。只要字面上的值相等,就认为两个对象相等
- 引用相等性。构造的对象常常会赋给一个变量,即让变量引用该对象。引用相等性用于比较两个变量是否引用了同一个对象,即是否指向JVM的堆里的同一个内存空间。如果两个变量引用了两个完全一样的对象,那么它们的自然相等性为true,但是引用相等性为false
在Java里,这两种相等性都是由操作符“==”和“!=”比较的。
Scala为了区分得更细致,也为了符合常规思维,只让“==”和“!=”比较自然相等性。这两个方法是所有类隐式继承来的,但是它们不能被子类重写。自定义类可能需要不同行为的相等性比较,因此可以重写隐式继承来的“equals”方法。为了比较引用相等性,Scala提供了“eq”和“ne”方法,它们也是被所有类隐式继承的,且不可被子类重写。例如:
Scala比较自然相等性:
- 只让“==”和“!=”方法比较,被所有类隐式继承的,且不可被子类重写
Scala比较引用相等性:
- 提供了“eq”和“ne”方法,它们也是被所有类隐式继承的,且不可被子类重写
自定义相等性行为:
- 可以重写隐式继承来的“equals”方法
1 | |
6.6 章节总结
本章又进一步阐释了Scala追求的纯粹的面向对象,介绍了“操作符即方法”这个重要概念。这一概念对构建良好的DSL语言很重要,因为它使得不仅内建类型可以写成表达式,也让自定义的类在计算时可以写出自然的表达式风格。
关于对象相等性,这是一个较为复杂的概念。在自定义类里,如果要比较对象相等性,则不仅是简单地重写equals方法,还需要其他手段。这里不再赘述,如有必要,后续会继续讨论。
7 extends类继承
7.1 Scala的类集成
在类的参数列表后面加上关键字“extends”和被继承类的类名,就完成了一个继承的过程。通常使用的三个名词:
- 超类:基本的一种继承关系
- 父类:只限定于一级继承时这么称呼
- 子类
被继承的类称为“超类”或者“父类”,而派生出来的类称为“子类”。如果继承层次较深,最顶层的类通常也叫“基类”。继承关系只有“超类”和“子类”的概念,即超类的超类也叫超类,子类的子类还叫子类。例如:
示例代码(纯粹演示Scala语法,没有实际意义):
1 | |
7.2 构造方法
子类调用超类的构造方法的语法是:
1 | |
父类构造方法没有参数:6.1中的例子中,父类的构造方法没有参数,所以“extends A”也就不需要参数
只有主构造方法才能调用超类的构造方法:Scala只允许主构造方法调用超类的构造方法,而这种写法就是子类的主构造方法在调用超类的构造方法。例如:
1 | |
7.3 一些特殊性质
(1)覆盖:override
覆盖超类的成员时,应该在定义的开头加上关键字“override”。例如:
1 | |
(2)不可覆盖的成员、不可被继承的类:final
如果超类成员在开头用关键字“final”修饰,那么子类就只能继承,而不能重写。
“final”也可以用于修饰class,那么这个类就禁止被其他类继承。
(3)无参方法与字段
Scala的无参方法在调用时,可以省略空括号。
鉴于此,对用户代码而言,如果看不到类库的具体实现,那么调用无参方法和调用同名的字段则没有什么不同,甚至无法区分其具体实现到底是方法还是字段。如果把类库里的无参方法改成字段,或是把字段改成无参方法,那么客户代码不用更改也能运行。
为了方便在这两种定义之间进行切换,Scala允许超类的无参方法被子类重写为字段,但字段不能反过来被重写为无参方法,而且方法的返回类型必须和字段的类型一致。示例代码如下:
1 | |
字段与方法的区别在于:字段一旦被初始化之后,就会被保存在内存中,以后每次调用都只需直接读取内存即可;方法不会占用内存空间,但是每次调用都需要执行一遍程序段,速度比字段要慢。因此,到底定义成无参方法还是字段,就是在速度和内存之间折衷。
字段能重写无参方法的原理是Scala只有两种命名空间:
- 值——字段、方法、包、单例对象
- 类型——类、特质。
因为字段和方法同处一个命名空间,所以字段可以重写无参方法。这也告诉我们,同处一个命名空间的定义类型,在同一个作用域内不能以相同的名字同时出现。例如,同一个类里不能同时出现同名的字段、无参方法和单例对象:
7.4 多态与动态绑定
类型为超类的变量可以指向子类的对象,这一现象被称为子类型多态,也是面向对象的多态之一。但是对于方法而言,尽管变量的类型是超类,方法的版本却是“动态绑定”的。也就是说,调用的方法要运行哪个版本,是由变量指向的对象来决定。例如:
1 | |
7.5 抽象类(abstract)
抽象类:
- 类里包含了没有具体定义的成员(没有初始化的字段或没有函数体的方法)
- 必须用关键字“abstract”修饰
抽象成员:
- 没有具体定义的成员
- 不需要“abstract”的修饰
抽象类无法构造出具体的对象,不能通过”new”构造实例对象
如果类里包含了没有具体定义的成员(没有初始化的字段或没有函数体的方法),那么这个类就是抽象类,必须用关键字“abstract”修饰。相应的成员称为抽象成员,不需要“abstract”的修饰。因为存在抽象成员,所以这个类不可能构造出具体的对象,因为有无法初始化抽象字段或者无法执行抽象方法,所以抽象类不能通过“new”来构造实例对象。
抽象类的子类可以对父类抽象成员进行定义,此时关键字”override”可以不写
抽象类常用于定义基类,因为基类会派生出很多不同的子类,这些子类往往具有行为不同的同名成员,所以基类只需要声明有哪些公共成员,让子类去实现它们各自期望的版本。
抽象类缺失的抽象成员的定义,可以由抽象类的子类来补充。也就是说,抽象类“声明”了抽象成员,却没有立即“定义”它。如果子类补齐了抽象成员的相关定义,就称子类“实现”了超类的抽象成员。相对的,我们称超类的成员是“抽象”的,而子类的成员是“具体”的。子类实现超类的抽象成员时,关键字“override”可写可不写。例如
1 | |
7.6 没有多重继承
Scala没有多重继承,也就是说,在“extends”后面只能有一个类,这与大多数oop语言不同。多重继承其实是一个很让人头疼的问题,使用起来很复杂,也很容易出错。在笔者学习C++的时候,看到了C++为了使用多重继承而不得不做出的大量语法规则修改,和单个继承混在一起时常把人搞晕。Scala舍弃多重继承的做法,对于程序员而言是莫大的帮助,不用在编写代码时考虑冗长的代码设计。尤其是对超类方法的调用,当存在多个超类时,为了避免歧义而不得不仔细设计方法的行为。
虽然多重继承不好用,但是它实现的功能在某些时候又不可或缺。为此,Scala专门设计了“特质”来实现相同的功能,并且特质的规则更简单、更明了。特质将在后一章介绍。
7.7 Scala类的层次结构
Scala所有的类——不管是标准库里已有的类还是自定义的类都存在层次关系。这种关系如下图所示,其中实线箭头表示属于指向的类的子类,虚线箭头表示可以隐式转换成指向的类:
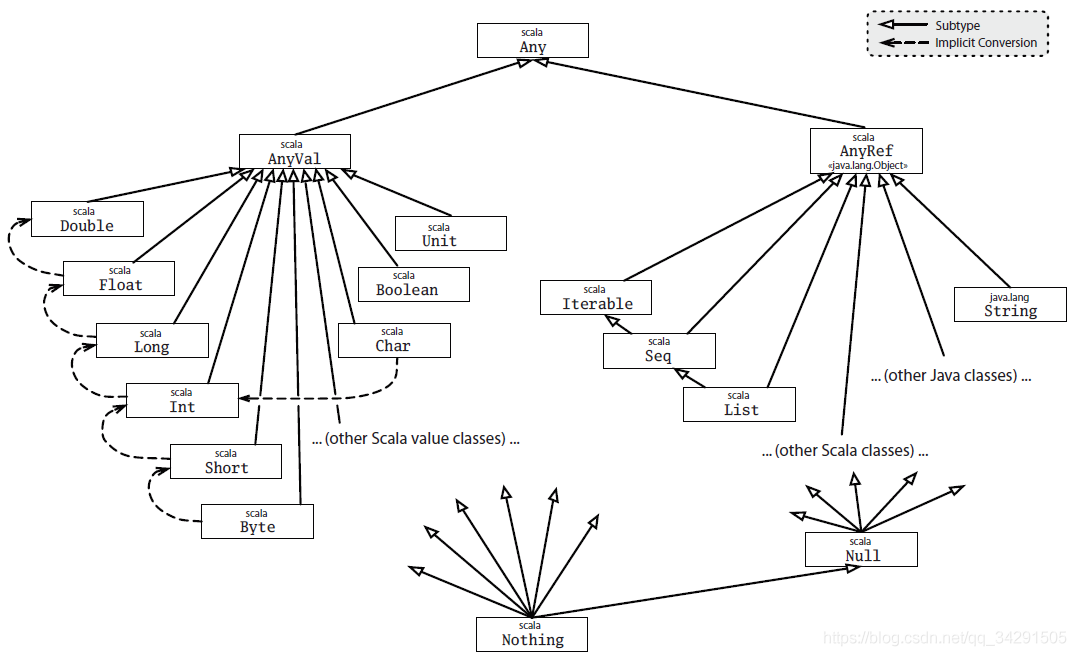
最顶部的类是抽象类Any,它是所有类的超类,Any类定义了几个成员方法,如下表所示:
| 方法定义 | 属性 | 说明 |
|---|---|---|
| def getClass(): Class[_] | 抽象 | 返回运行时对象所属的类的表示 |
| final def !=(arg0: Any): Boolean | 具体 | 比较两个对象的自然相等性是否不相等 |
| final def ==(arg0: Any): Boolean | 具体 | 比较两个对象的自然相等性是否相等 |
| def equals(arg0: Any): Boolean | 具体 | 比较两个对象的自然相等性,被!=和==调用 |
| final def ##(): Int | 具体 | 计算对象的哈希值,等同于hashCode,但是自然相等性相等的两个对象会得到相同的哈希值,并且不能计算null对象 |
| def hashCode(): Int | 具体 | 计算对象的哈希值 |
| final def asInstanceOf[T]: T | 具体 | 把对象强制转换为T类型 |
| final def isInstanceOf[T]: Boolean | 具体 | 判断对象是否属于T类型,或T的子类 |
| def toString(): String | 具体 | 返回一个字符串来表示对象 |
也就是说,任何类都有这几个方法。注意,不能出现同名的方法,若确实需要自定义版本,则记得带上“override”。
再往下一层,Any类有两个子类:AnyVal和AnyRef。也就是说,所有类被分成两大部分:值类和引用类。值类也就是前面讲过的对应Java的九种基本类型,并且其中七个存在一定的隐式转换,例如Byte可以扩展成Short等等。隐式转换是Scala的一个语法,用于对象在两个类之间进行类型转换,后面章节会讲到。除了标准库里已有的隐式转换,也可以自定义隐式转换。
除了这九个值类,也可以自定义值类,即定义时显式地继承自AnyVal类。如果没有显式地继承自AnyVal类,则都认为是AnyRef类的子类,也就是说一般自定义的类都属于引用类。大部分标准库里的类都是引用类,比如常见的字符串类String,还有后续会讲解的列表类、映射类、集合类等等。Java的类都属于引用类,因为Java的基本类型都在值类里面。
前面讲过引用相等性,很显然只有引用类才有引用相等性。事实上,比较引用相等性的两个方法——eq和ne,都定义在AnyRef类里。值类AnyVal是没有这两个方法的,也不需要。
在层次结构的底部有两个底类型——Null类和Nothing类。其中Null类是所有引用类的子类,表示空引用,即指向JVM里的空内存,这与Java的null概念是一样的。但是Null并不兼容值类,所以Scala还有一个类——Nothing,它是所有值类和引用类的子类,甚至还是Null类的子类。因此Nothing不仅表示空引用,还表示空值。Scala里有一个可选值语法,也就是把各种类型打包成一个特殊的可选值。为了表示“空”、“没有”这个特殊的概念,以及兼容各种自定义、非自定义的值和引用类,这个特殊的可选值其实就是把Nothing类进行打包。
除了自定义的普通类属于引用类,后一章讲解的特质,也是属于引用类的范畴。
7.8 章节总结
本章介绍了类继承的语法,其内容不多,也简单易懂。这一章真正的难点是阅读大型系统软件时,遇到的纷繁复杂的类层次,要梳理这些类的继承关系往往费时费力。还有自己编写代码时,如何设计类的结构,让系统稳定、简单、逻辑清晰,也不是一件容易事。
在编写Chisel时,类继承主要用于编写接口,因为接口可以扩展,但是实际的硬件电路并没有很强烈的继承关系。
8 trait特质
8.1 什么是特质
(1)特质trait
Scala没有多重继承,为了提高代码复用率,故而创造了新的编程概念——特质
特质是用关键字“trait”为开头来定义的
特质与单例对象很像,两者都不能有入参。类、单例对象、特质三者一样,内部可以包含字段和方法,甚至包含其他类、单例对象、特质的定义。
| 特质 | 单例对象 |
|---|---|
| 不能有入参 | 不能有入参 |
| 抽象的,但不需要用“abstract”来说明 | 具体的 |
| 可以包含抽象成员 | 不能包含抽象成员 |
| 不能用new来实例化 | 不能用new来实例化 |
(2)混入:
- 特质可以被其它类、单例对象和特质“混入”。这里使用术语“混入”而不是“继承”,是因为特质在超类方法调用上采用线性化机制,与多重继承有很大的区别。
- 其它方面,“混入”和“继承”其实是一样的。例如,某个类混入一个特质后,就包含了特质的所有公有成员,而且也可以用“override”来重写特质的成员
- 要混入一个特质,在当前类没有继承的情况下可以使用关键字“extends”,否则通过关键字“with”来混入其他特质。例如:
Scala只允许继承自一个类,但是对特质的混入数量却没有限制,故而可用于替代多重继承语法,同时也拥有多态的特性
1 | |
(3)特质拥有多态的特性:
特质也定义了一个类型,而且类型为该特质的变量,可以指向混入该特质的对象。例如:
1 | |
8.2 特质的继承和混入
特质也可以继承自其他类,或混入任意个特质,这样该特质就是关键字“extends”引入的那个类/特质的子特质。如果没有继承和混入,那么这个特质就是AnyRef类的子特质。前面讲过AnyRef类是所有非值类和特质的超类。
当某个类、单例对象或特质用关键字“extends”混入一个特质时,会隐式继承自这个特质的超类。(也就是说,类/单例对象/特质的超类,都是由“extends”引入的类或特质决定的。)
特质对混入有一个限制条件:那就是要混入该特质的类/单例对象/特质,它的超类必须是待混入特质的超类,或者是待混入特质的超类的子类。因为特质是多重继承的替代品,那就有“继承”的意思。既然是继承,混入特质的类/单例对象/特质的层次,就必须比待混入特质的层次要低。例如:
1 | |
上例中,类Test1直接混入特质D,这样隐式继承自D的超类——类A,所以合法。类Test2和Test3分别继承自类A和A的子类,所以也允许混入特质D。类Test4的超类是C,而C与A没有任何关系,所以非法。类Test5的超类是A,特质E的超类是B,尽管类A是类B的超类,这也仍然是非法的。从提示的错误信息也可以看出,混入特质的类/单例对象/特质,其超类必须是待混入特质的超类或超类的子类。
8.3 混入特质的简便方法
- 快速构造一个混入某些特质的实例:
1 | |
上面代码其实是定义了一个匿名类,这个匿名类混入了这些特质,并且花括号内是该匿名类的定义。然后使用new构造了这个匿名类的一个对象,其等效的代码就是:
2
3>class AnonymousClass extends Trait1 with Trait2 ... { definition }
>new AnonymousClass一个例子:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18scala> trait T {undefined
| val tt = "T__T"
| }
defined trait T
scala> trait X {undefined
| val xx = "X__X"
| }
defined trait X
scala> val a = new T with X
a: T with X = $anon$1@4c1fed69
scala> a.tt
res0: String = T__T
scala> a.xx
res1: String = X__X
- 除此之外,还可以在最前面加上一个想要继承的超类
1 | |
8.4 特质的线性化叠加的计算
多重继承一个很明显的问题:多个超特质的方法调用
当子类特质调用超类的方法时,若多个超类都有该方法的不同实现,那么需要附加额外的语法来确定具体调用哪个版本。
Scala特质采取一种线性化的规则来调用特质中的方法,这与大多数语言不一样。在特质里,“super”调用是动态绑定的。也就是说,按特质本身的定义,无法确定super调用的具体行为;直到特质混入某个类或别的特质,有了具体的超类方法,才能确定super的行为。这是实现线性化的基础。
线性化叠加特点总结:
① 超特质的方法实现前用关键字组合“abstract override”进行声明
注意这不是重写,而是告诉编译器该方法用于线性叠加。这个关键字组合只能用在特质里,不允许用在其他地方。
② 超特质对该方法的定义必须出现“super.方法名(参数)”
③ 被混入的类应有同名同参的方法(内部定义、继承、重写都可以)
这个关键字组合也意味着该特质必须被某个拥有该方法具体定义的类混入(这个类的方法可以是自己实现或者重写的,也可以是继承的,总之它拥有该方法),也就是这个类定义了该方法的最终行为。如果被没有拥有该方法具体定义的类给混入了,那么就会报错。
④ 被混入的类不能立刻混入,应该把他再作为父类定义一个子类,用子类混入各种特质;同时也可以使用简便方法,定义新的匿名类如:
1 | |
需要混入特质进行线性化计算的类,在定义时不能立即混入特质。这样做会让编译器认为这个类是在重写末尾那个特质的方法,而且当类的上一层超类是抽象类时还会报错。应该先定义这个类的子类来混入特质,然后构造子类的对象。或者直接用第三点讲的“new SuperClass with Trait1 with Trait2 …”来快速构造一个子类对象。
⑤ 方法的执行顺序遵循线性化计算公式:起点最右边特质,同时从起点处接收参数,结果返回作为参数传递给右边第二个参数,最后回到最左边的被混入的类本身
可以理解为特质是按一定顺序对入参进行各种变换,最后把变换后的入参交给类来计算。
⑥ 回到被混入的类本身,说明此类直接或间接override或实现了基类的方法,且直接实现时需使用override关键词
- 如果此类同名同参方法的实现使用了“super.方法名(参数)”,那么会调用它的上一层超类的实现版本
- 此类没有override,那就一定要对该同名同参方法的实现,或也调用上一层超类的实现版本
线性化计算公式(定义被混入类的匿名子类的规则):
- ① 最左边是被混入类本身。
- ② 左边第二个写最后混入的那个特质,往右按继承顺序写下该特质的所有超类和超特质
- ③ 写完第二个带着的所有超类和特质后,往右写下倒数第二个混入的特质,以及其超类和超特质,直到写完所有特质。
- ④ 所有重复项只保留最右边那个,并在最右边加上
AnyRef和Any。
为了具体说明,以如下代码为例:
1 | |
实例运行结果:
PS E:\Microsoft VS\Scala> scala test.scala
G -> D -> C -> E -> F -> B -> End 首先,需要混入特质进行线性化计算的类G在定义时没有立即混入特质,即只有“class G extends X”,而是通过“new G with D with E with F with B”来构造G的匿名子类的对象。其次,注意基类A是一个抽象类,类X实现了抽象方法m,类G重写了X的m,其余特质也用“abstract override”重写了m,这保证了m最终会回到类G。最后,基类A的m的返回类型“String”的声明是必须的,因为抽象方法无法推断返回类型,不声明就默认是Unit。
根据线性化计算公式可得(蓝色表示起点,红色表示重复,类X不参与计算):
① G
② G→B(蓝色)→A
③ G→B→A→F→C→A
④ G→B→A→F→C→A→E→C→A
⑤ G→B→A→F→C→A→E→C→A→D→A
⑥ G→B→F→E→C→D→A
⑦ G→B→F→E→C→D→A→AnyRef→Any
起点是B,传入参数“End”会得到“B -> End”;然后B的super.m调用F的m,并传入计算得到的“B -> End”,那么F会得到“F -> B -> End”,再继续向右调用;最后A的m是抽象的,无操作可执行,转而回到G的m,所以最后传给G的参数实际是“D -> C -> E -> F -> B -> End”,得到的结果也就是“G -> D -> C -> E -> F -> B -> End”。
8.5 特殊情况的验证
- 如果G的m也有super或没有重写,那么会调用X的m,最后的结果是最左边多个X(也就是第六点):
1 | |
PS E:\Microsoft VS\Scala> scala test.scala
X -> G -> D -> C -> E -> F -> B -> End
- 如果立即混入特质,则相当于普通的方法重写:
1 | |
PS E:\Microsoft VS\Scala> scala test.scala
G -> End
- 如果上一层超类是抽象类,立即混入会引发错误:
1 | |
PS E:\Microsoft VS\Scala> scala test.scala
E:\Microsoft VS\Scala\Chapter 12.\traittest.scala:23: error: overriding method m in trait B of type (s: String)String;
method m needs `abstract override’ modifiers
override def m(s: String) = “G -> “ + s
^
one error found
8.6 章节总结
特质用于代码重用,这与抽象基类的作用相似。不过,特质常用于混入在不相关的类中,而抽象基类则用于构成有继承层次的一系列相关类。在Chisel中,特质常用于硬件电路模块的公有属性的提取,在需要这些属性的电路中混入相应的特质,在不需要的时候删去,就能快速地修改电路设计
9 package包
9.1 包的定义、命名方式、内容、编译
当代码过于庞大时,为了让整个系统层次分明,各个功能部分划分明显,常常需要把整体划分成若干独立的模块。与Java一样,Scala把代码以“包”的形式划分。
包定义:以关键字“package”为开头来定义的,有两种风格的定义方式:
- 可以用花括号把包的范围包起来(这种风格类似C++和C#的命名空间)
- 好处:而且这种方法使得一个文件可以包含多个不同的包
- 也可以不用花括号标注范围(这种风格类似Java)
- 好处:但包的声明必须在文件最前面,这样使得整个文件的内容都属于这个包
包的命名方式:推荐使用Java的反转域名法,即“com.xxx.xxx”的形式
包的内容:可以定义class、object和trait,也可以定义别的package
包的编译:如果编译一个包文件,那么会在当前路径下生成一个与包名相同的文件夹,文件夹里是包内class、object和trait编译后生成的文件,或者是包内层的包生成的更深一层文件夹。如果多个文件的顶层包的包名相同,那么编译后的文件会放在同一个文件夹内。也就是说,一个包的定义可以由多个文件的源代码组成
9.2 包的访问、层次、精确代码访问
因为包里还可以定义包,所以包也有层次结构。包的层次不仅便于人们按模块阅读,同时也告诉编译器这些代码存在某些层次联系。
(1)包的访问:
- 方法一(注:如果包名中就出现了句点,那么编译器也会按层次编译):
- 如果一个包仅仅是包含了其他的包,没有额外的class、object和trait定义,推荐使用这种方式访问,这样内部代码省去了一次缩进。
1 | |
- 方法二:
- 可用于声明不同的包,方法一不行
1 | |
(2)编译的先后顺序:先编译出一个名为one的文件夹,然后在里面又编译出一个名为two的文件夹
(3)Scala的包是嵌套的而不是分级的:而不像Java那样只是分级的。这体现在Java访问包内的内容必须从最顶层的包开始把全部路径写齐,而Scala则可以按照一定的规则书写更简短的形式。例如:
1 | |
嵌套的几个特点:
- 访问同一个包内的class、object和trait不需要增加路径前缀
因为“new StarMap”和“class StarMap”都位于bobsrockets.navigation包内,所以这条代码能够通过编译。
- 访问同一个包内更深一层的包所含的class、object和trait,只需要写出那层更深的包。
因为“class Ship”和“package navigation”都位于bobsrockets包内,所以要访问navigation包内的class、object和trait只需要增加“navigation.”,而不是完整的路径。
- 当使用花括号显式表明包的作用范围时,包外所有可访问的class、object和trait在包内也可以直接访问
因为“package fleets”位于外层包bobsrockets,所以bobsrockets包内、fleets包外的所有class、object和trait可以直接访问,故而“new Ship”不需要完整路径也能通过编译。
- 以上规则只在同一个文件内显式嵌套时可以生效
- 通过包名带句点来访问嵌套(即使把这两个文件合并),无法编译。例如下面的代码就不能通过编译:
1 | |
- 但是当第二个文件把每个包分开声明时,上述规则又能生效。例如下面的代码是合法的:
1 | |
(4)访问最顶包的内容:root
为了访问不同文件最顶层包的内容,Scala定义了一个隐式的顶层包“_root_”,所有自定义的包其实都包含在这个包里。例如:
1 | |
Booster3必须通过“root”才能访问,否则就和Booster1混淆,造成歧义。
9.3 import导入
和python类似,如果每次都按第二点的精确访问方式来编程,则显得过于繁琐和复杂。因此,可以通过关键字“import”来导入相应的内容。
(1)Scala的import的特点:
- ①可以出现在代码的任意位置,而不仅仅是开头
- ②除了导入包内所含的内容,还能导入对象(单例对象和new构造的对象都可以)和包自身,甚至函数的参数都能作为对象来导入
- ③可以重命名或隐藏某些成员,(类似python import as)例如:
1 | |
通过语句“import A.B”就能把包B导入。当要访问M时,只需要写“B.M”而不需要完整的路径。通过“import A.B.M”和“import A.C.N”就分别导入了类M和对象N。此时访问它们只需要写M和N即可。
(2)import多个元素:
路径最后的元素可以放在花括号里,这样就能导入一个或多个元素
例如通过import A.{B, C}就导入了两个包。花括号内的语句也叫“引入选择器子句”。
(3)导入所有的元素
使用下划线。例如import A._或import A.{_}就把包B和C都导入了,其中通配符“_”代指其余元素
(4)导入时对包重命名
如果写成import A.{B => packageB},就是在导入包B的同时重命名为“packageB”,此时可以用packageB指代包B,也仍能用“A.B”显式访问
(5)导入时对包隐藏
如果写成import A.{B => _, _},就是把包B进行隐藏,而导入A的其他元素。注意,指代其余元素的下划线通配符必须放在最后。
(6)导入时注意相对路径问题
包导入是相对路径,也就是代码里有import A._的文件要和包A编译后的文件夹要在同一级目录下
9.4 this自引用
Scala有一个关键字“this”,用于指代对象自己。
简单的理解就是:
- 如果this用在类的方法里,则指代正在调用方法的那个对象;
- 如果用在类的构造方法里,则指代当前正在构建的对象。
9.5 访问修饰符
包、类、对象的成员都可以标上访问修饰符“private”和“protected”。
- 用“private”修饰的成员是私有的,只能被包含它的包、类或对象的内部代码访问;
- 用“protected”修饰的成员是受保护的,除了能被包含它的包、类或对象的内部代码访问,还能被子类访问(只有类才有子类)。
9.6 限定词与自限定
限定词:除此之外,还可以加上限定词,使被修饰对象能被限定词访问,语法为:[限定词]
假设X指代某个包、类或对象,那么private[X]和protected[X]就是在不加限定词的基础上,把访问权限扩大到X的内部。例如:
2
3
4
5
6
7
8
9
10
11
12
13
14
15package A {
package B {
private[A] class JustA
}
class MakeA {
val a = new B.JustA // OK
}
}
package C {
class Error {
val a = new A.B.JustA // error
}
}
限定词还能是自引用关键字“this”
private[this]比private更严格,不仅只能由内部代码访问,还必须是调用方法的对象或构造方法正在构造的对象来访问
protected[this]则在private[this]的基础上扩展到定义时的子类,例如:
1 | |
MyInt1可以编译成功,但是MyInt2却不行,因为add传入的对象不是调用方法的对象,所以不能访问字段mi2,尽管这还是代码内部。换句话说,用private[this]和protected[this]修饰的成员x,只能通过“this.x”的方式来访问。
对于类、对象和特质,不建议直接用private和protected修饰,容易造成作用域混乱,应该用带有限定词的访问修饰符来修饰,显式声明它们在包内的作用域。
前面说过,伴生对象和伴生类共享访问权限,即两者可以互访对方的所有私有成员。在伴生对象里使用“protected”没有意义,因为伴生对象没有子类。特质使用“private”和“protected”修饰成员也没有意义。
9.7 package object包对象
包里可直接包含的元素有类、特质和单例对象,但其实类内可定义的元素都能放在包里(只不过字段和方法不能直接定义在包里)
包对象可以理解为(我自己想的):包中唯一的可定义字段和方法且直属该包的区域/对象)
Scala把字段和方法放在一个“包对象”中,每个包都允许有一个包对象。
包对象用关键字组合“package object”为开头来定义,其名称与关联的包名相同,有点类似伴生类与伴生对象的关系。
包对象不是包,也不是对象,它会被编译成名为“package.class”的文件,该文件位于与它关联的包的对应文件夹里。为了保持路径同步,建议定义包对象的文件命名为“package.scala”,并和定义关联包的文件放在同一个目录下。
9.8 章节总结
本章讲解了包的概念,以及Scala独有的一些语法特点。这一章并不是重点,主要是方便读者在阅读别人的代码时能理解层次结构、模块划分,以及根据import的路径来快速寻找相应的定义
10 集合
不管是用Scala编写软件,还是用Chisel开发硬件电路,集合都是非常有用的数据结构。
Scala里常见的集合有:数组、列表、集、映射、序列、元组、数组缓冲、列表缓冲。
了解这些集合的概念并熟练掌握基本使用方法,对提高工作效率大有帮助。本章的内容便是逐一讲解这些集合类,所涉内容均为基础,对编写、阅读Chisel代码有用即可。如果想深入了解集合的原理,请读者自行学习。
10.1 Array数组(一个类)
数组是最基本的集合,实际是计算机内一片地址连续的内存空间,通过指针来访问每一个数组元素。因为数组是结构最简单的集合,所以它在访问速度上要比其它集合要更快
关于数组你必须知道的事情:
- Scala的数组类名为Array, Array是一个具体的类,通过new来构造一个数组对象。数组元素的类型任意的,所有元素的类型必须一致。且数组在运行时会保存类型参数信息。
Scala编译器的泛型机制是擦除式的,在运行时并不会保留类型参数的信息。但是数组的特点使得它成为唯一的例外,因为数组的元素类型跟数组保存在一起
数组的性质:数组对象必须是定长的,也就是在构造时可以选择任意长度的数组,构造完毕后就不能再更改长度了
构造数组对象的语法如下:
- T表示元素的类型,可以显式声明,也可以通过传入给构造方法的对象来自动推断(构造对象时,除了可以用值参数来“配置”对象,也可以用类型参数来“配置”。这其实是oop里一种重要的多态,称为全类型多态或参数多态,即通过已有的各种类型创建新的各种类型。)
- n代表元素个数,它必须是一个非负整数,如果n等于0则表示空数组
常用的构造方法实例:
1 | |
特殊的构造方法实例:
- 特殊的构造方法:除此之外,Array的伴生对象里还定义了一个apply工厂方法,因此也可以按如下方式构造数组对象:
1 | |
- 数组的访问:数组可以用过
(下标)来索引每个元素(用括号索引的原因是让编译器隐式插入apply方法的调用)
和大多数语言一样,Scala的数组下标也是从0开始的。不过,有一点不同的是,其他语言的数组下标都是写在方括号里,而Scala的数组下标却是写在圆括号里。还记得“操作符即方法吗”?Scala并没有什么下标索引操作符,而是在Array类里定义了一个apply方法,该方法接收一个Int类型的参数,返回对应下标的数组元素。所以,Scala的数组下标才要写在圆括号里,这其实是让编译器隐式插入apply方法的调用,当然读者也可以显式调用。
1 | |
10.2 List列表(一个抽象类,类似不可写入的Array)
列表是一种基于链表的数据结构,这使得列表访问头部元素很快,往头部增加新元素也是消耗定长时间,但是对尾部进行操作则需要线性化的时间,也就是列表越大时间越长。
- List列表是一个抽象类,因此不能用new来构造列表对象。但是伴生对象里有一个apply工厂方法,接收若干个参数,以数组的形式转换成列表(链表)。列表也是定长的,且每个元素的类型相同、不可再重新赋值
List有点像不可写入的Array
列表元素的访问:同Array
常用的构造与访问方法实例:
1 | |
- 列表添加新元素(不是修改旧表,列表不可变,而是构造新表):列表定义了一个名为
::的方法,在列表头部添加新元素。其写法如下:
因为列表的数据结构特性使得在头部添加元素很快,而尾部很慢,所以列表定义了一个名为“::”的方法,在列表头部添加新元素。注意,这会构造一个新的列表对象,而不是直接修改旧列表,因为列表是不可变的
1 | |
左侧的x是一个T类型的元素
右侧的xs是一个List[T]类型的列表。
这种写法符合直观表示。
还记得前面说过以冒号结尾的中缀操作符,其调用对象在右侧吗?其实正是出自这里。因为x是任意类型的,如果让x成为调用对象,那么就必须在所有类型包括自定义类型里都添加方法“::”,这显然是不现实的。如果让列表xs成为调用对象,那么只需要列表类定义该方法即可。例如:
1 | |
- 拼接左、右两个列表,返回新的列表:
:::
1 | |
空列表:
- List有一个子对象
Nil,示空列表。Nil的类型是List[Nothing] - 因为List的类型参数是协变的(有关泛型请见后续章节),而Nothing又是所有类的子类,所以List[Nothing]是所有列表的子类,即
Nil兼容所有元素
- List有一个子对象
使用空列表构造列表:既然Nil是一个空列表对象,那么它同样能调用方法
::,通过Nil和::就能构造出一个列表
使用空列表构造方法实例:
1 | |
- 用apply工厂方法构造其实是上述方式的等效形式。展开来解释就是:在空列表Nil的头部添加了一个元素3,构成了列表List(3);随后,继续在头部添加元素2,构成列表List(2, 3);最后,在头部添加元素1,得到最终的List(1, 2, 3)
使数组和列表包含不同类型的元素(不推荐):数组与列表元素不仅可以是值类型,它们也可以是自定义的类,甚至是数组和列表本身,构成嵌套的数组与列表。此外,如果元素类型是Any,那么数组和列表也就可以包含不同类型的元素。当然,并不推荐这么做。例如:
1 | |
10.3 快速添加元素、数组缓冲与列表缓冲
(1)如何快速添加元素往尾部添加元素:
一种可行方案是先往列表头部添加,再把列表整体翻转。
另一种方案是使用定义在scala.collection.mutable包里的ArrayBuffer和ListBuffer。
- 这两者并不是真正的数组和列表,而可以认为是暂存在缓冲区的数据。在数组缓冲和列表缓冲的头部、尾部都能添加、删去元素,并且耗时是固定的,只不过数组缓冲要比数组慢一些。数组和列表能使用的成员方法,在它们的缓冲类里也有定义。
(2)使用ArrayBuffer/ListBuffer添删元素的具体方法:
ArrayBuffer/ListBuffer += value可以往缓冲尾部添加元素- 通过
value +=: ArrayBuffer/ListBuffer可以往缓冲头部添加元素 - 只能通过
ArrayBuffer/ListBuffer -= value往缓冲的尾部删去第一个符合的元素 - 往尾部增加或删除元素时,元素数量可以不只一个。
常用的构造与访问方法实例:
1 | |
(3)使用ArrayBuffer/ListBuffer转换数组的方法:
- 通过方法
toArray或toList把缓冲的数据构造成一个数组或列表对象 - 注意,这是构造一个新的对象,原有缓冲仍然存在。例如:
1 | |
10.4 Tuple元组(一系列类)
- 元组也是一种常用的数据结构,不是一个类是一系列类,不可变,但可以包含不同类型元素
- 两种元组的构造写法:
- (不常用)使用具体的元组类进行元组构造:
new TupleX(元组元素),见下方介绍- 元组字面量构造的写法:就是在圆括号里编写用逗号间隔的元素。常用的构造方法实例:
- (不常用)使用具体的元组类进行元组构造:
1 | |
上述例子构造了一个三元组,包含了一个Int对象、一个String对象和控制台对象。注意查看打印的元组类型。
元组最常用的地方:作为函数的返回值。由于函数只有一个返回语句,但如果想返回多个表达式或对象,就可以把它们包在一个元组里返回。
元组不可遍历,无法通过下标来索引:因为元组含有不同类型的对象,所以不可遍历,也就无法通过下标来索引,只能通过“_1”、“_2”……这样来访问每个元素。注意第一个元素就是“_1”,不是“_0”(与Array和List从0开始不同)例如:
1 | |
元组并不是一个类,而是一系列类:Tuple1、Tuple2、Tuple3……Tuple22
这些类都是具体的,因此除了通过字面量的写法构造元组,也可以显式地通过
new TupleX(元组元素)来构造。其中,每个数字代表元组包含的元素数量,也就是说元组最多只能包含22个元素,除非自定义Tuple23、Tuple24……不过这没有意义,因为元组可以嵌套元组,并不妨碍元组包含任意数量的元素。查看元组的API,会发现每个TupleX类里都有名为“_1”、“_2”……“_X”的字段。这正好呼应了前面访问元组元素所用的独特语法。
- Tuple1(一元组)没有字面量,只能显式地通过“new Tuple1(元组元素)”来构造一元组,因为此时编译器不会把圆括号解释成元组
- Tuple2(二元组)也叫“对偶”,这在映射里会用到
当函数的入参数量只有一个时,那么调用时传递进去的元组字面量也可以省略圆括号。例如:
1 | |
10.5 Map映射(一个特质)
映射是包含一系列“键-值”对的集合,可重复的键值对(可重复hash)
键和值的类型可以是任意的,但是每个键-值对的类型必须一致
键-值对的写法是“键 -> 值”
映射并不是一个类,而是一个特质。所以无法用new构建映射对象,只能通过伴生对象里的apply工厂方法来构造映射类型的对象,常用的构造方法实例:
1 | |
- Map返回键对应值:对映射的apply方法通过接收一个键作为参数,返回对应的值。例如:
1 | |
- 实际意义(可以写成对偶形式):表达式“object1 -> object2”实际就是一个对偶(二元组),因此键-值对也可以写成对偶的形式。例如:
1 | |
- 映射可变与不可变:默认情况下,使用的是scala.collection.immutable包里的不可变映射。当然,也可以导入scala.collection.mutable包里的可变映射,这样就能动态地增加、删除键-值对。可变映射的名字也叫“Map”,因此要注意使用import导入可变映射时,是否把不可变映射覆盖了。
10.6 Set集合(一个特质)
- 集和映射一样,也是一个特质,也只能通过apply工厂方法构建对象
理解为hash哈希
集只能包含字面值不相同的同类型元素
- 集的apply方法是测试是否包含传入的参数,返回true或false,而不是通过下标来索引元素
常用的构造方法如下:
1 | |
- 默认情况下,使用的也是不可变集,scala.collection.mutable包里也有同名的可变集
10.7 Seq序列(一个特质)
序列Seq也是一个特质,数组和列表都混入了这个特质
序列可遍历、可迭代,也就是能用从0开始的下标索引,也可用于循环。
- 序列也是包含一组相同类型的元素,并且不可变。
- 其构造方法也是通过apply工厂方法。
只是因为Chisel在某些场合会用到Seq,所以介绍这个概念,但是不必深入了解。
10.8 针对集合的几种常用方法
上述类都定义了很多有用的成员方法,在这里介绍一二。如果想查看更多内容,建议前往官网的API网站查询
(1)map方法(同python里面的Map)
为集合内每个元素接受参数:Map方法接收一个无副作用的函数作为入参,对调用该方法的集合的每个元素应用入参函数,并把所得结果全部打包在一个集合里返回
1 | |
(2)foreach方法(同java里面的泛式)
遍历集合内每一个元素:foreach方法与map方法作用类似,不过它的入参是一个有副作用的函数。例如:
1 | |
(3)zip方法
把两个可迭代的集合一一对应,构成若干个对偶。如果其中一个集合比另一个长,则忽略多余的元素。例如:
1 | |
10.9 章节总结
本章介绍了Scala标准库里的常用集合,这些数据结构在Chisel里面也经常用到,读者应该熟悉掌握它们的概念和相关重点。在后一章内建控制结构中,也要用到这些集合
11 内建控制结构
11.1 if表达式
用于判断的“if……else if……else”语法想必是所有编程语言都具备的。Scala的if表达式与大多数语言是一样的。在if和每个else if后面都将接收一个Boolean类型的表达式作为参数,如果表达式的结果为true,就执行对应的操作,否则跳过。每个分支都可以包含一个表达式作为执行体,如果有多个表达式,则应该放进花括号里。对整个if表达式而言,实际是算作一个表达式。
为什么叫if表达式?
- Scala把“if”叫“表达式”,是因为if表达式能返回有用的值
- 但是while叫循环,是因为while循环不会返回有用的值,主要作用是不断重写某些var变量,所以while循环的类型是Unit
- 跟多内容在下一节有解释
类似大多数高级语言,不过多介绍
11.2 while循环
类似大多数高级语言,不过多介绍
1 | |
从上述代码可以看出,while语法的风格是指令式的。实际上,Scala把“if”叫“表达式”,是因为if表达式能返回有用的值,而“while”叫循环,是因为while循环不会返回有用的值,主要作用是不断重写某些var变量,所以while循环的类型是Unit,在纯函数式的语言里,只有表达式,不会存在像while循环这样的语法。Scala兼容两种风格,并引入了while循环,是因为某些时候用while编写的代码可阅读性更强
函数式风格的while循环(使用递归的方式实现):其实所有的while循环都可以通过其它函数式风格的语法来实现,常见做法就是函数的递归调用。例如,一个函数式风格的求取最大公约数的函数定义如下:
1 | |
11.3 for表达式与for循环(推荐)
(1)for循环介绍
要实现循环,在Scala里推荐使用for表达式。Scala的for表达式是函数式风格的,没有引入指令式风格的“for(i = 0; i < N; i++)”
其他风格的for(类似传统上的for循环)循环可以参考链接:https://www.runoob.com/scala/scala-for-loop.html
(2)使用yield的循环:
一个Scala的for表达式的一般形式如下:
1 | |
- 整个for表达式算一个语句。
- seq代表一个序列
- 能放进for表达式里的对象,必须是一个可迭代(Iterable)的集合。比如常用的列表(List)、数组(Array)、映射(Map)、区间(Range)、迭代器(Iterator)、流(Stream)和所有的集(Set),它们都混入了特质Iterable
- 可迭代的集合对象能生成一个迭代器,用该迭代器可以逐个遍历集合中的所有元素,进而构成了for表达式所需的序列。
- 能放进for表达式里的对象,必须是一个可迭代(Iterable)的集合。比如常用的列表(List)、数组(Array)、映射(Map)、区间(Range)、迭代器(Iterator)、流(Stream)和所有的集(Set),它们都混入了特质Iterable
- 关键字“yield”是“产生”的意思,也就是把前面序列里符合条件的元素拿出来,逐个应用到后面的“expression”,得到的所有结果按顺序产生一个新的集合对象
(3)完整的For循环(上述seq展开式):
1 | |
seq是由“生成器”、“定义”和“过滤器”三条语句组成(以分号隔开,或者放在花括号里让编译器自动推断分号)
- ①生成器
p <- persons右侧persons就是一个可迭代的集合对象,把它的每个元素逐一拿出来与左侧的模式p进行匹配(有关模式匹配请见后续章节)。- 如果匹配成功,那么模式里的变量就会绑定上该元素对应的部分;
- 如果匹配失败,并不会抛出匹配错误,而是简单地丢弃该元素。
- 在这个例子里,左侧的p是一个无需定义的变量名,它构成了变量模式,也就是简单地指向persons的每个元素
- 大多数情况下的for表达式的生成器都是这么简单。
- ②定义就是一个赋值语句,这里的n也是一个无需定义的变量名。定义并不常用,比如这里的定义就可有可无。
- ③过滤器则是一个if语句,只有if后面的表达式为true时,生成器的元素才会继续向后传递,否则就丢弃该元素。
- 这个例子中,是判断persons的元素的name字段是否以“To”为开头。最后,name以“To”为开头的persons元素会应用到yield后面的表达式,在这里仅仅是保持不变,没有任何操作。(总之,这个表达式的结果就是遍历集合persons的元素,按顺序找出所有name以“To”为开头的元素,然后把这些元素组成一个新的集合)
- 完整的sep展开的for的示例代码:
1 | |
PS E:\Microsoft VS\Scala> scala test.scala
List(Tom, Tony, Todd)
(4)嵌套for
- 一个for表达式中有多个生成器:那么出现在后面的生成器比出现在前面的生成器变得更频繁,也就是指令式编程里的嵌套的for循环。例如计算乘法口诀表:
1 | |
(5)普通遍历的for、定义的重新计算
每当生成器生成一个匹配的元素,后面的定义就会重新求值。
这个求值是有必要的,因为定义很可能需要随生成器的值变化而变化。为了不浪费这个操作,定义应尽量用到相关生成器绑定的变量,否则就没必要使用定义。例如:
1 | |
不如写成:
1 | |
(6)for求和、省略yield
如果只想把每个元素应用到一个Unit类型的表达式,那么就是一个“for循环”,而不再是一个“for表达式”。关键字“yield”也可以省略。例如:
1 | |
11.4 用try表达式处理异常
(1)抛出一个异常
如果操作非法,那么JVM会自动抛出异常。
也可以手动抛出异常,只需要用new构造一个异常对象,并用关键字“throw”抛出即可,语法与Java一样。
try表达式的完整形式是“try-catch-finally”
(2)try-catch
try后面可以用花括号包含任意条代码,当这些代码产生异常时,JVM并不会立即抛出,而是被catch捕获。catch捕获异常后,按其后面的定义进行相应的处理。处理的方式一般借助偏函数,在详细了解模式匹配前,只需要了解这些语法即可。例如处理除零异常:
1 | |
(3)finally
try表达式的完整形式是“try-catch-finally”。不管有没有异常产生,finally里的代码一定会执行。通常finally语句块都是执行一些清理工作,比如关闭文件。尽管try表达式可以返回有用值,但是最好不要在finally语句块里这么做。因为Java在显式声明“return”时,会用finally的返回值覆盖前面真正需要的返回值。为了以防万一,最好不要这样做。例如:
1 | |
10.5 match表达式
match表达式的作用相当于“switch”,也就是把作用对象与定义的模式逐个比较,按匹配的模式执行相应的操作。在详细了解模式匹配之前,先看一个简单的例子粗浅地了解一番:
1 | |
10.6 关于continue和break
(1)传统循环中的continue和break
对于指令式编程而言,循环里经常用到关键字“continue”和“break”,例如下面的Java程序:
1 | |
实际上,这两个关键字对循环而言并不是必须的。例如可以改写成如下Scala代码:
1 | |
(2)Scala中的break和continue
又因为这两个关键字过于偏向指令式风格,就像“return”,所以Scala并没有引入它们。
Scala不提供原生的break和continue,也不推荐用for循环,而是通过递归调用实现:
1 | |
Scala标准库中提供了Break类从而实现break
通过import scala.util.control.Breaks._”可以导入Breaks类,该类定义了一个名为“break”的方法。那么,在写下break的地方,就会被编译器标记为可中断。
11.7 变量的作用域
在使用控制结构的时候,尤其是有嵌套时,必然要搞清楚变量的作用范围。Scala变量作用范围很明确,边界就是花括号。例如:
1 | |
如果内、外作用域有同名的变量,那么内部作用域以内部变量为准,超出内部的范围以外部变量为准。例如:
1 | |
11.8 章节总结
本章介绍了Scala的内建控制结构,尤其是for表达式,在Chisel里面也是经常用到。对于重复逻辑、连线等,使用for表达式就很方便。尽管Verilog也有for语法,但是使用较为麻烦,而且不能像Chisel一样支持泛型。
除此之外,Chisel也有自定义的控制结构,这些内容会在后续章节讲解。

本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!